深度了解MapReduce运行流程,通过案例全面了解MR运行过程、涉及的组件、设计的思想。对MapReduce Partition、 Mapreduce Combiner、MapReduce编程技巧掌握,对自定义对象、序列化、排序、分区、分组的实现熟练掌握,掌握MapReduce并行度机制、工作流程和shuffle的机制。
1、 Mapreduce Partition、Combiner
输出结果文件只有一个。默认情况下,最终输入文件只有一个
改变reducetask的个数
job.setNumReduceTask(2)1.1Mapreduce Partition
数据分区问题:多个reduce执行的时候,maptask交给哪一个来处理。
默认情况下,只有一个reducetask,不管输入量多大,map最终结果输入到一个文件里面
按照什么规则进行分:默认分区规则是HashPartitioner,分区结果和map输出的key有关。
注意事项:
- reducetask个数的改变导致了数据分区的产生。
- 数据分区的核心是分区规则
- 默认的规则不能保证每个分区内数据量一样,可以保证只要map阶段输出的key一样,数据就一定分到同一个分区
- 改变了reducetask导致结果文件不再是一个整体,而是多个文件。
1.2 Combiner
默认不启用的组件Combiner
数据规约:是指尽可能保持数据原貌的前提下,精简原数据量。map端的输出先做一次局部聚合,以减少map和reduce节点之间的数据传输量。Combiner本质就是一个reduce。
具体实现步骤:
自定义一个CustomCombiner类,继承Reducer,重写reduce方法,
job.setCombinerClass(customCombiner.class);
使用注意事项:
Combiner能够应用的前提是不能影响最终的业务逻辑。
禁用Combiner的场景:业务和数据个数相关的。业务和整体排序相关的。
-
2、MapReduce 编程指南
-
2.1 编程技巧
- 1 、MR的执行流程需要了然于心
- 2、业务需求解读准确
- 3、执行流程梳理
- 4、key重要性体现
- 5、学会自定义修改默认行为
- 6、通过画图梳理业务执行流程
- 5、学会自定义修改默认行为
- 4、key重要性体现
- 3、执行流程梳理
-
2.2 流程梳理
- Map阶段
- 第一阶段:逻辑切片,SplitSize = BlockSize
- 第二阶段:对切片中的数据按行去读
- 第三阶段:调用Mapper类中的map()方法处理数据
- 第四阶段:map计算结果分区partition。默认不分区
- 第五阶段:map写出数据到内存缓冲区,达到比例溢出到磁盘,溢出spill时,排序
- 第六阶段:溢出数据合并
- Reduce阶段
第一阶段:拉取自己分区的数据
第二阶段:把数据合并,在排序
第三阶段:对排序后的键值对调用reduce方法,以key分组,按组调用。
key的重要性的体现
牢牢把握每个阶段输出输入key是什么
排序、分区、分组都与key有关
Mapreduce支持排序、分区、分组自定义规则。
3、案例:美国新冠疫情病例统计
有一份2021-01-28号美国各县county的新冠疫情统计数据,包括累计确诊病例、累计死亡病例。使用MapReduce对疫情数据进行各种分析统计。
自定义对象序列化、自定义排序、自定义分区、自定义分组,自定义分组(topN)
涉及多属性数据传递,建议使用JavaBean进行封装,注意需要实现序列化,如果作为key,需要实现Comparable接口。如果需要输出,还需要实现toString()。
各州感染和死亡病例
package cn.btks.mapreduce.covid.sum;
import cn.btks.mapreduce.covid.beans.CovidCountBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CovidSumMapper extends Mapper<LongWritable, Text,Text, CovidCountBean> {
Text outKey = new Text();
CovidCountBean outValue = new CovidCountBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//读取一行数据,切割
String[] fields = value.toString().split(",");
//提取数据,州,确诊,死亡
outKey.set(fields[2]);
//outValue.set(Long.parseLong(fields[4]),Long.parseLong(fields[4]));
//因为疫情数据中某些县缺失邮编字段,角标越界,倒数角标
outValue.set(Long.parseLong(fields[fields.length-2]),Long.parseLong(fields[fields.length-1]));
//输出键值对
context.write(outKey,outValue);
}
}
package cn.btks.mapreduce.covid.sum;
import cn.btks.mapreduce.covid.beans.CovidCountBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CovidSumReducer extends Reducer<Text, CovidCountBean,Text,CovidCountBean> {
private CovidCountBean outValue = new CovidCountBean();
@Override
protected void reduce(Text key, Iterable<CovidCountBean> values, Context context) throws IOException, InterruptedException {
//创建两个统计变量
long totalCases = 0;
long totalDeaths = 0;
//遍历各个州的书
for (CovidCountBean value : values) {
totalCases += value.getCases();
totalDeaths += value.getDeaths();
}
//结果赋值
outValue.set(totalCases,totalDeaths);
//输出结果
context.write(key,outValue);
}
}
package cn.btks.mapreduce.covid.beans;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 自定义对象在mapreduce中运行,要实现Writable
*/
public class CovidCountBean implements Writable {
//确诊病例数
private long cases;
//确诊病例数
private long deaths;
public CovidCountBean() {
}
public CovidCountBean(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
//自己封装对象的set方法,用于赋值
public void set(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public long getCases() {
return cases;
}
public void setCases(long cases) {
this.cases = cases;
}
public long getDeaths() {
return deaths;
}
public void setDeaths(long deaths) {
this.deaths = deaths;
}
@Override
public String toString() {
return cases + "t" + deaths;
}
/**
* 序列化方法,将数据写出去
* @param out 输出
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(cases);
out.writeLong(deaths);
}
/**
* 反序列化方法,反序列话的顺序与序列化一致
* @param in 输入
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.cases = in.readLong();
this.deaths = in.readLong();
}
}
累积病例倒排统计
Map的输出中用自定义对象作为key,自定义对象实现compareTo方法,认为改变其比较规则。
package cn.btks.mapreduce.covid.beans;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 自定义对象在mapreduce中运行,要实现Writable
*/
public class CovidCountBean implements WritableComparable<CovidCountBean> {
//确诊病例数
private long cases;
//确诊病例数
private long deaths;
public CovidCountBean() {
}
public CovidCountBean(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
//自己封装对象的set方法,用于赋值
public void set(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public long getCases() {
return cases;
}
public void setCases(long cases) {
this.cases = cases;
}
public long getDeaths() {
return deaths;
}
public void setDeaths(long deaths) {
this.deaths = deaths;
}
@Override
public String toString() {
return cases + "t" + deaths;
}
/**
* 序列化方法,将数据写出去
* @param out 输出
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(cases);
out.writeLong(deaths);
}
/**
* 反序列化方法,反序列话的顺序与序列化一致
* @param in 输入
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.cases = in.readLong();
this.deaths = in.readLong();
}
/**
* 自定义对象的排序方法
* @param o
* @return 0 正序:相等,负数 小于,正数 大于,倒叙:负数 大于,正数 小于
*/
@Override
public int compareTo(CovidCountBean o) {
return this.getCases()-o.getCases()>0?-1:(this.getCases()-o.getCases()<0?1:0);
}
}
package cn.btks.mapreduce.covid.sortsum;
import cn.btks.mapreduce.covid.beans.CovidCountBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CovidSortReducer extends Reducer<CovidCountBean, Text,Text,CovidCountBean> {
@Override
protected void reduce(CovidCountBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//排序好之后,reduce会进行分组操作,判断我们的key是否相等,本业务中使用自定义对象作为key
// ,没有写分组规则,默认调用equal,比较对象地址,正是我们需要的。
Text outKey = values.iterator().next();
context.write(outKey,key);
}
}
package cn.btks.mapreduce.covid.sortsum;
import cn.btks.mapreduce.covid.beans.CovidCountBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CovidSortSumMapper extends Mapper<LongWritable, Text, CovidCountBean,Text> {
private CovidCountBean outKey = new CovidCountBean();
private Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] strings = value.toString().split("t");
//取值,赋值
outKey.set(Long.parseLong(strings[1]),Long.parseLong(strings[2]));
outValue.set(strings[0]);
//写出
context.write(outKey,outValue);
}
}
各州累计病例分区统计,不同州下所有县的数据输出到一个文件中。
需求分析:输出到不同文件,不止一个redutask,代码中可以设置job.setNumRedueTask(N),意味着数据分区,默认分区规则HashPartioner,不满足,自定义分区规则。
输出到不同的文件中,reducetask有多个,意味着有分区操作,默认分区规则是什么,
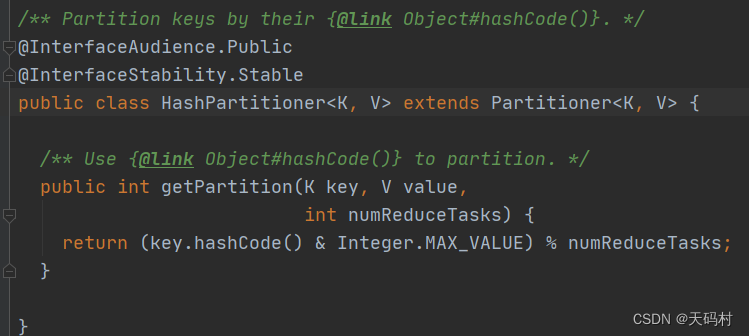
默认的分区规则源码
/** Partition keys by their {@link Object#hashCode()}. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}自定义分区类的实现
public class StatePartitioner extends Partitioner<Text,Text> {
//模拟一下美国各州的数据字典,实际中可以从redis中加载,如果数据量不大,也可以集合保存
public static HashMap<String,Integer> stateMap = new HashMap<>();
static {
stateMap.put("Alabama", 0);
stateMap.put("Alaska",1);
stateMap.put("Arkansas",2);
stateMap.put("California",3);
stateMap.put("Colorado",4);
}
/**
* 自定义分区规则的实现方法,只要getPartition返回的int一样,数据就会被分到同一个分区
* @param key 州
* @param value 一行文本数据据
* @param numPartitions
* @return
*/
@Override
public int getPartition(Text key, Text value, int numPartitions) {
Integer code = stateMap.get(key.toString());
if (code != null){
return code;
}
return 5;
}
}设置分区生效
//设置程序的Partitioner,分区组件生效的前提是educeTask个数
job.setNumReduceTasks(6);
job.setPartitionerClass(StatePartitioner.class);疑问:分区个数和reducetask个数之间的关系?
正常情况下,分区个数==reducetask个数
其他情况,reducetask>分区个数,生成reducetask个数文件,但是多余的文件是空文件,影响性能。
reducetask<分区个数,会报错:非法的分区。
5、MapReduce并行度机制
reducetask并行度同样影响整个job的执行并发度和执行效率,与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置:job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜。
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask。
6、MapReduce工作流程详解
简单概述:input File通过split被逻辑切分为多个split文件,通过Record按行读取内容给map(用户自己实现的)进行处理,数据被map处理结束之后交给OutputCollector收集器,对其结果key进行分区(默认使用hash分区),然后写入buffer,每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
7、MapReduce Shuffle 机制
shuffer的本意是洗牌,吧一组有规则的数据尽量打乱成无规则的数据
而在mapreduce中,shuffle更像洗牌的逆过程,从map产生输出开始到reduce数据作为输入之前的过程。
最后
以上就是曾经火最近收集整理的关于大数据学习笔记-MapReduce(二) 深度1、 Mapreduce Partition、Combiner2、MapReduce 编程指南2.2 流程梳理3、案例:美国新冠疫情病例统计5、MapReduce并行度机制6、MapReduce工作流程详解7、MapReduce Shuffle 机制的全部内容,更多相关大数据学习笔记-MapReduce(二)内容请搜索靠谱客的其他文章。








发表评论 取消回复