好久没写爬虫程序,最近才又重新完整的写了一次。突然发现和原来的风格大相径庭,今天的代码量少了好多,实现的方式也有所不同,并没有依赖于tuple或者dictionary的数据类型,仅在sql和pandas的灵活运用下,实现了数据的获取与初步处理。这次程序最大的特点是灵活与简洁。
Covid-Data
疫情数据获取与处理
为研究疫情期间公众舆论反应与疫情发展状况直接的关系,利用python爬虫程序和平台API接口,获取有关数据,并进行数据处理,方便进行下一步时间序列分析,数据分析部分后期将进行相应更新。
myCatch.py
基于央视新闻官方微博对公众舆论关注度进行分析,目的是获取2020年以来央视新闻官方微博的所有微博评论数,点赞量,以及转发数。
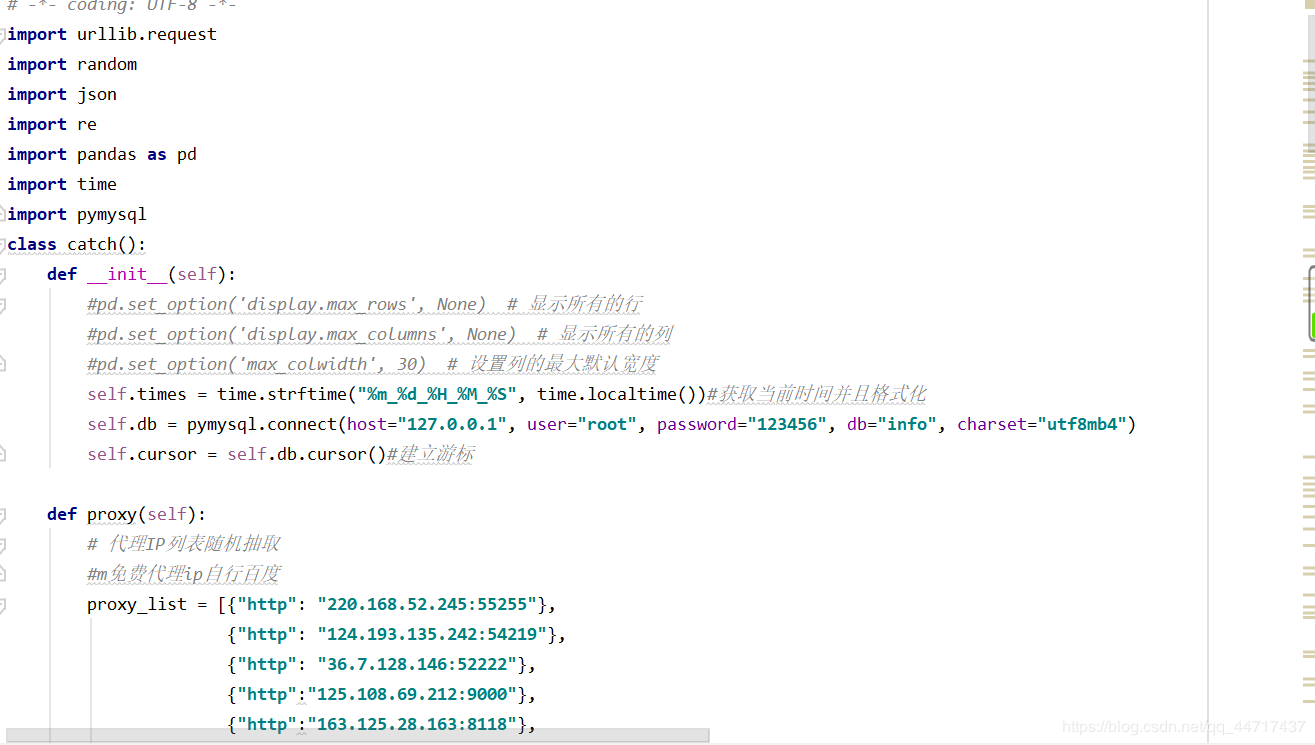
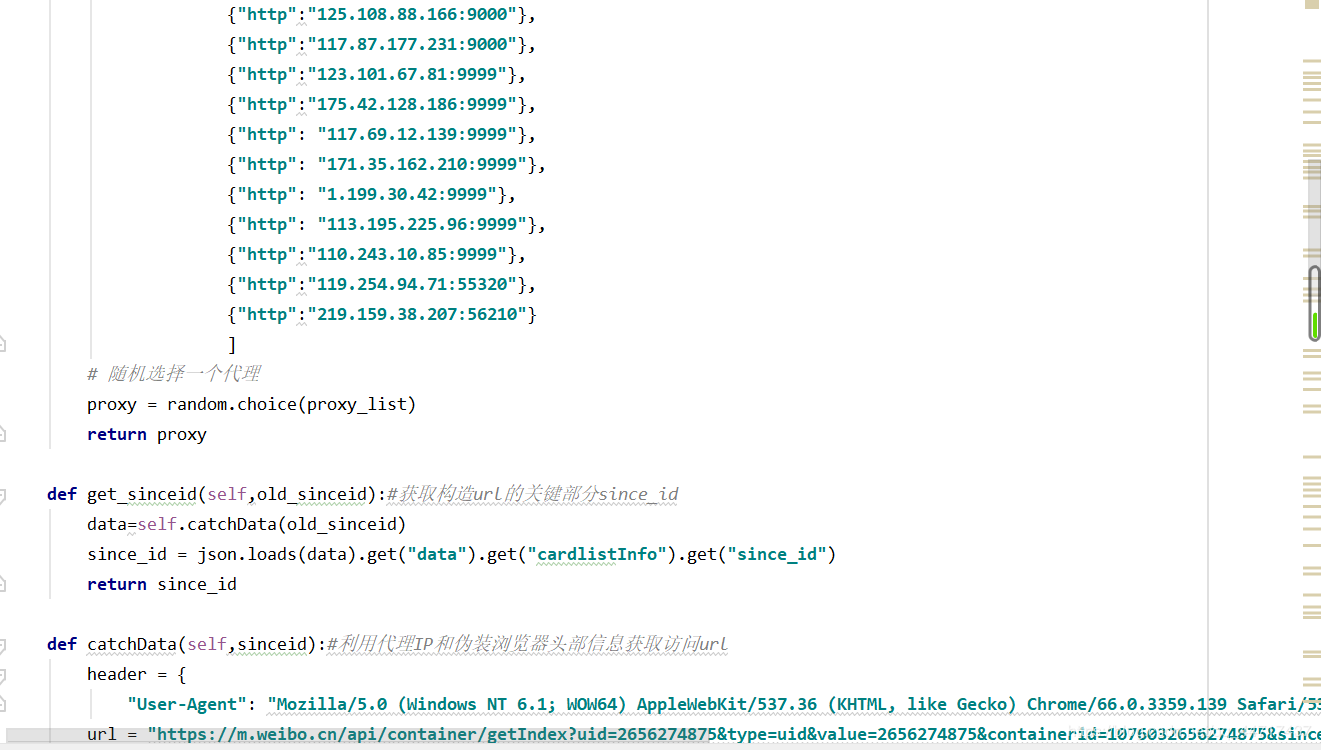
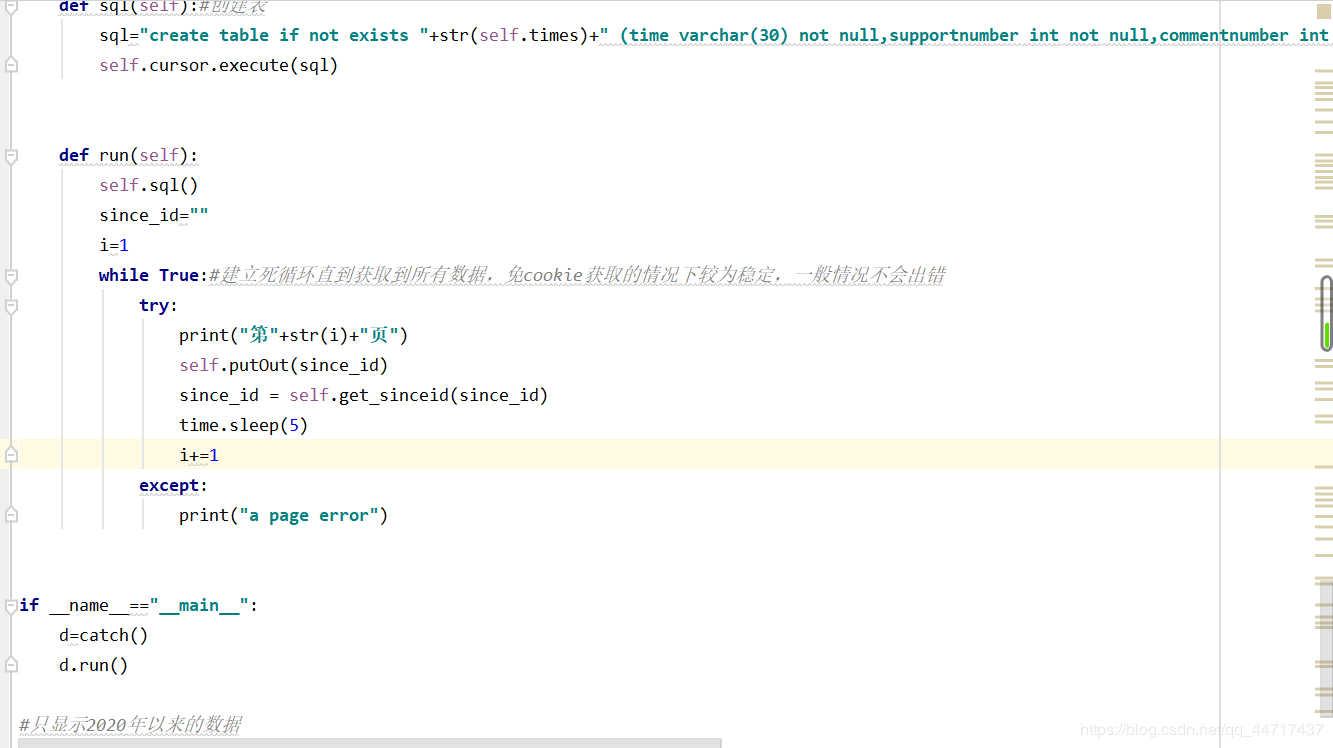
与前面程序不同,这次爬取的是微博手机端的网页版,采取免登录的模式,并且采用多个代理ip,通过获取api接口,保证爬取任务的一次性完成。获取api接口:
since_id
https://m.weibo.cn/api/container/getIndex?uid=2656274875&type=uid&value=2656274875&containerid=1076032656274875
https://m.weibo.cn/api/container/getIndex?uid=2656274875&type=uid&value=2656274875&containerid=1005052656274875
https://m.weibo.cn/api/container/getIndex?uid=2656274875&type=uid&value=2656274875&containerid=1078032656274875
https://m.weibo.cn/api/container/getIndex?uid=2656274875&type=uid&value=2656274875&containerid=2302832656274875
https://m.weibo.cn/api/container/getIndex?uid=2656274875&type=uid&value=2656274875&containerid=1076032656274875&since_id=4511399117729669
https://m.weibo.cn/api/container/getIndex?uid=2656274875&type=uid&value=2656274875&containerid=1076032656274875&since_id=4511342374405026
https://m.weibo.cn/api/container/getIndex?uid=2656274875&type=uid&value=2656274875&containerid=1076032656274875&since_id=4511280708383633
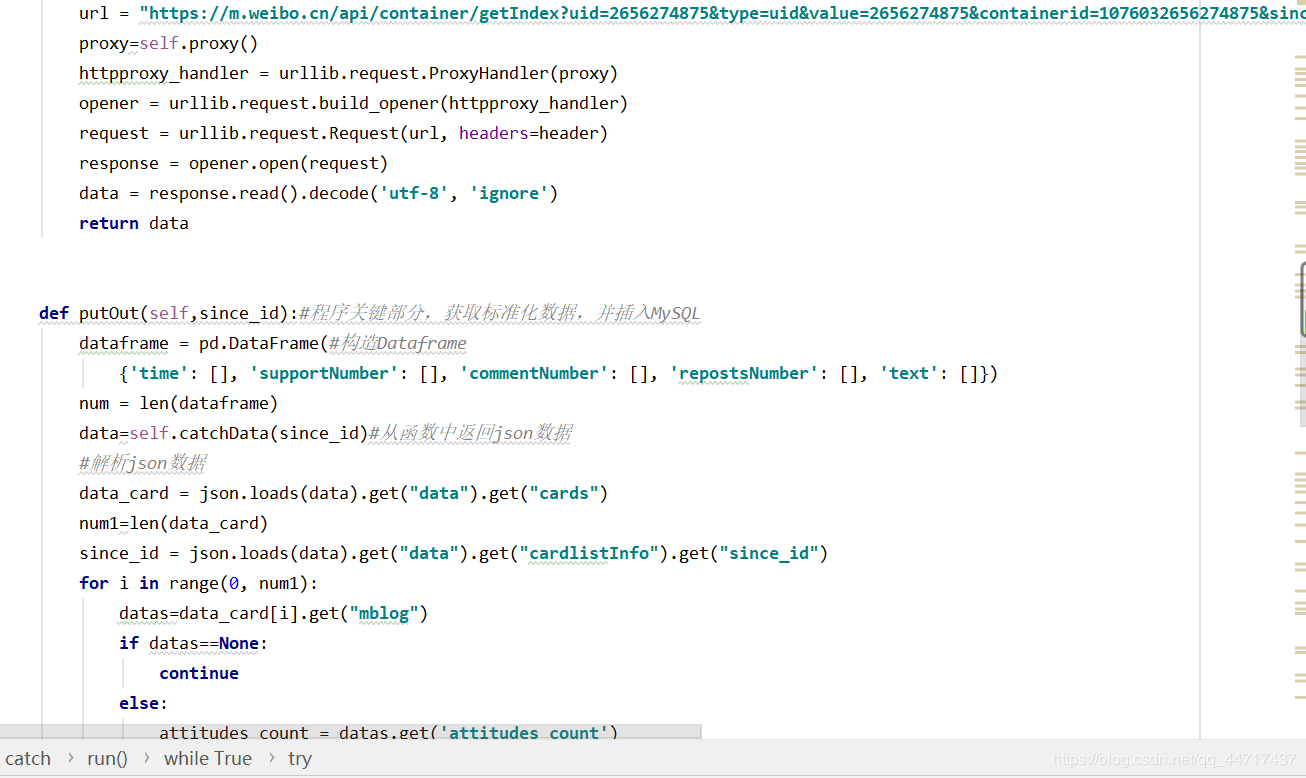
在谷歌浏览器中选择:检查-network-XHR-getIndex…-preview,从而在上一个返回json中寻找since_id。在经过一系列处理后,直接存储到sql中
covid.py
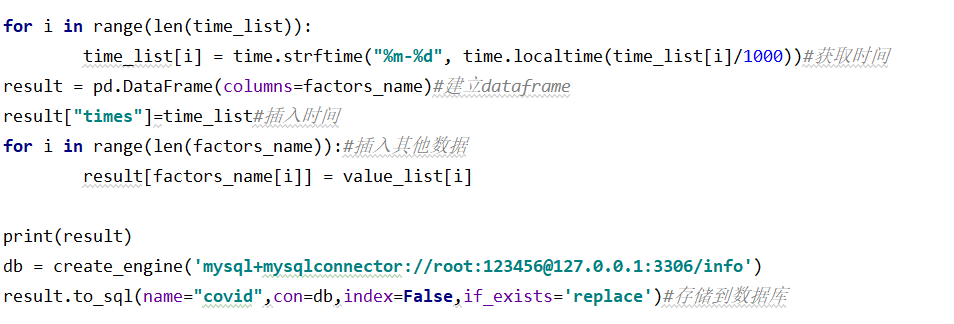
利用万矿平台的现成的接口,获取数据,并且把数据整理成dataframe形式,然后保持到mysql中。
self.conn = create_engine(‘mysql+mysqlconnector://root:123456@127.0.0.1:3306/info’)#需要下载一个软件mysql_connector到电脑上,或者用pymysql会有警告
improveData.to_sql(name=“data_sum”,con=self.conn, index=False, if_exists=‘replace’)#存回数据库

deal.py
deal1():
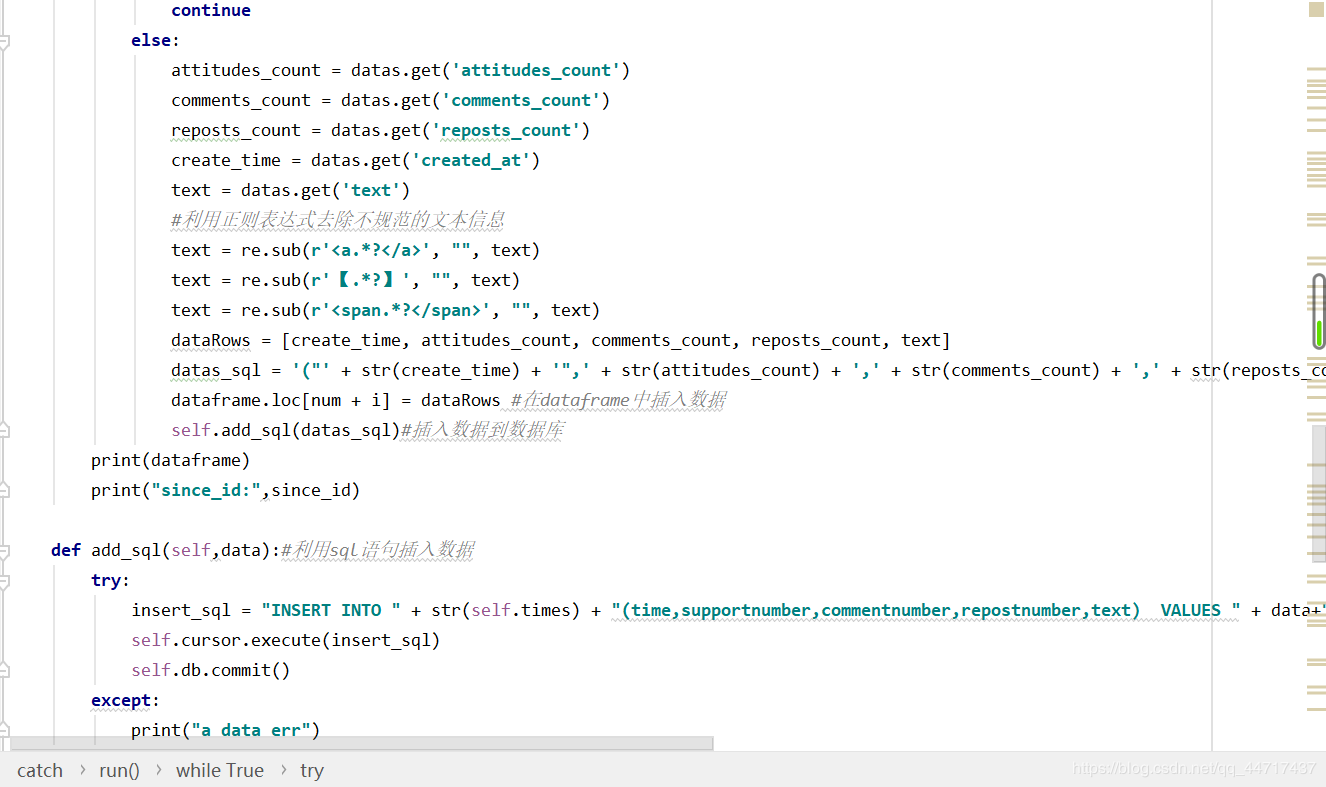
先对数据进行初步筛选,获取发布日期为1月20日到6月9日的微博,然后构建一个简单的语义字典,判别本条微博是否与疫情相关,在dataframe中新建一列,如果相关的话,该列值为1。
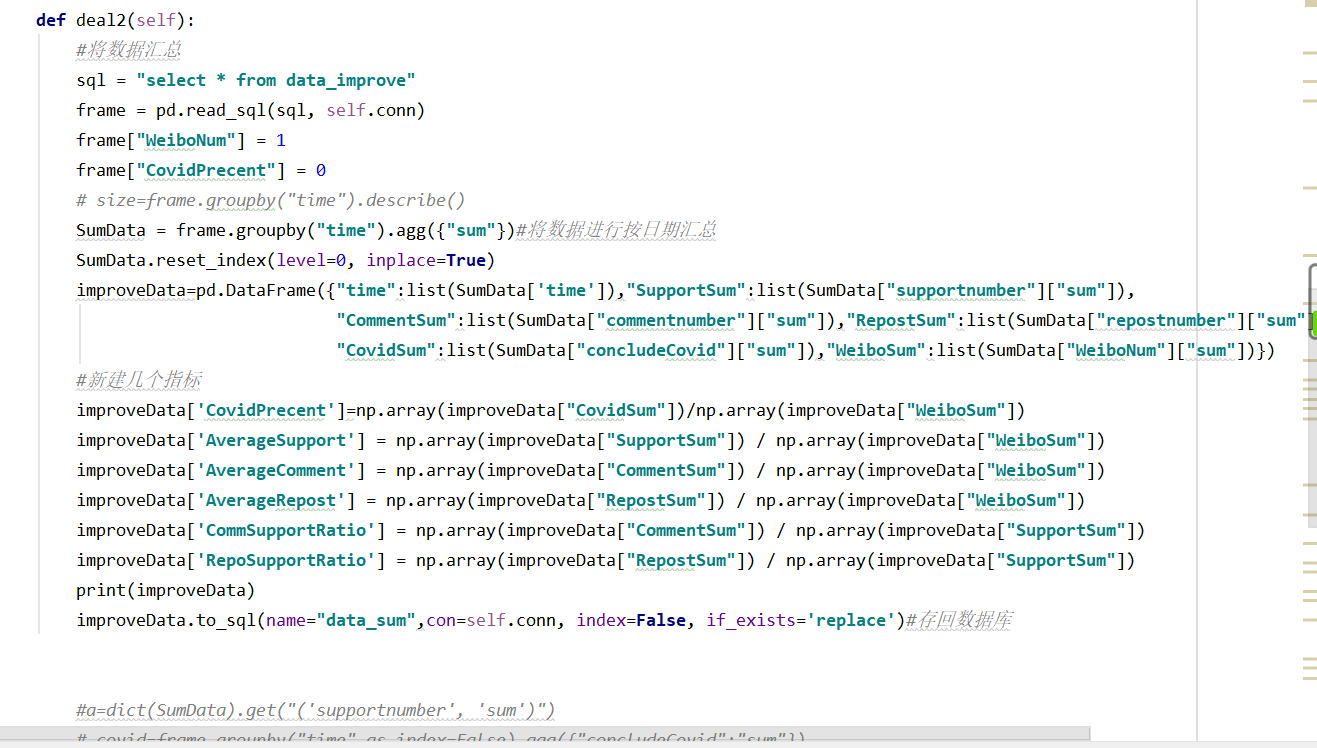
deal2():
实现数据按日期汇总归纳,之后再在dataframe中新建几个指标。
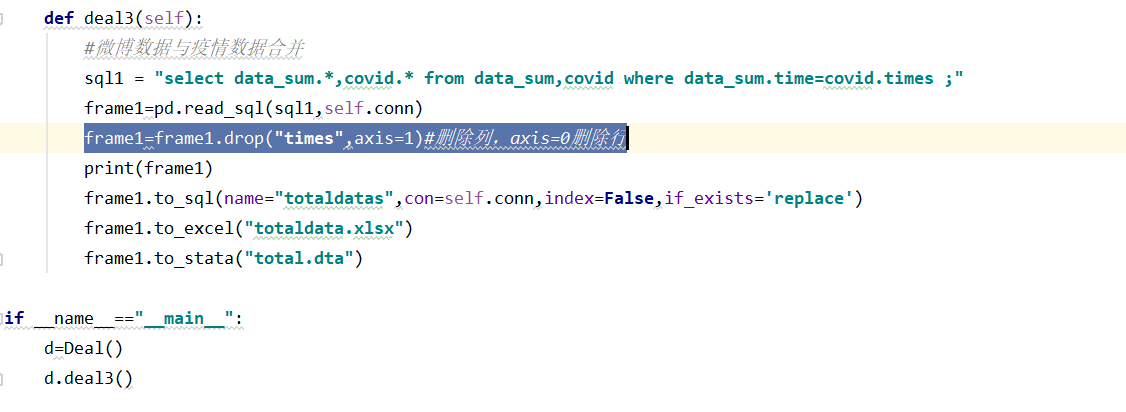
deal3():
利用sql语句将疫情数据表和微博表合并,只保留一列的时间数据。

最后
以上就是忐忑含羞草最近收集整理的关于疫情相关数据的获取与处理Covid-DatamyCatch.pycovid.py的全部内容,更多相关疫情相关数据内容请搜索靠谱客的其他文章。








发表评论 取消回复