我是靠谱客的博主 干净仙人掌,这篇文章主要介绍爬虫:python爬虫学习笔记之Beautifulsoup&正则表达式Beautifulsoup正则表达式正则表达式实例:,现在分享给大家,希望可以做个参考。
本文是我在使用网易云课堂学习日月光华老师讲的“Python爬虫零基础入门到进阶实战”课程所做的笔记,如果大家觉得不错,可以去看一下老师的视频课,讲的还是很棒的。
本文没什么营养,只是做个笔记。
Beautifulsoup
使用beautifulsoup可以直接返回源代码。
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
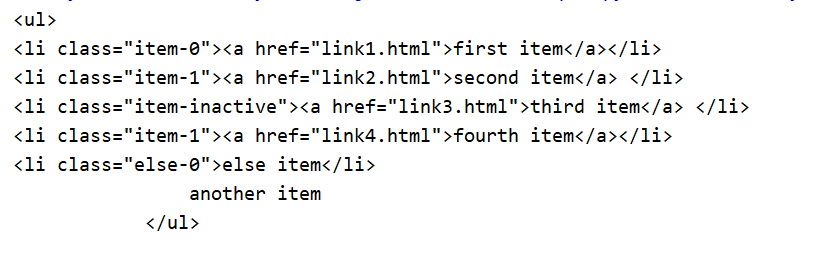
print(soup.ul)
执行效果:
使用 . 选取元素
使用.选择元素后,默认输出的是第一个元素
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
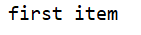
print(soup.ul.li)
执行效果图:

取出文本
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.ul.li.a.string)
执行效果图:

提取属性
类似于字典
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
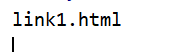
print(soup.a['href'])
执行效果图:
使用get方法
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
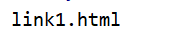
print(soup.a.get('href'))
执行效果图:
使用find_all()查找元素
返回所有某种元素
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('a'))
执行效果图:

取出某个元素中的文本
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('a')[2].string)
执行效果图:

直接使用soup()与soup.find_all()效果相同
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup('a')[2].string)
执行结果图:

根据属性名查找元素
找出属性名固定的元素
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup(class_='item-0'))
执行效果图:
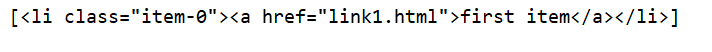
找出某个元素文本
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup(class_='item-0')[0].string)
执行效果图:
结合正则表达式寻找属性名包含某段文本的元素
相当于xpath中的startwith
# 引入beautifulsoup
from bs4 import BeautifulSoup
# 引入正则表达式
import re
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup(class_=re.compile('item-'))[3].string)
执行效果图:

取出所有文本
# 引入beautifulsoup
from bs4 import BeautifulSoup
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a> </li>
<li class="item-inactive"><a href="link3.html">third item</a> </li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="else-0">else item</li>
another item
</ul>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
print([x.strip() for x in soup.ul.get_text().split('n') if x.strip()])
# print(soup.ul.get_text())
执行效果图:
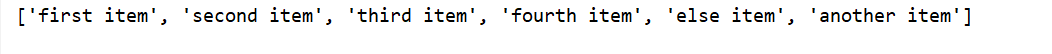
正则表达式
Python标准库中的re模块提供正则表达式的全部功能。
import re
正则表达式方法
函数匹配
1.从匹配开头 match()
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
# 从头开始匹配
print(re.match('Beautiful', text))
执行结果:
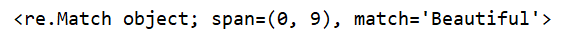
其中:span为匹配到的范围。
使用span()方法取出匹配位置
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.match('Beautiful', text).span())
执行结果:
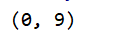
使用group()方法取出匹配内容
import re
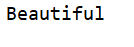
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.match('Beautiful', text).group())
执行结果:
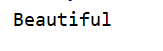
group()可以进行选择输出第几个对象
只有用括号括起来的内容才算是对象
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.match('(w+) is (w+)', text).group(1))
执行结果:
使用不同模式匹配
匹配两边有空格的is/从头开始匹配
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.match('w+ is w+', text).group())
执行结果:

其中:w为匹配空格和下划线,+代表一个或多个
2.匹配整个串,一直匹配到第一个结束search()
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.search('ugly', text).group())
执行结果:
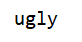
3.替换方法 sub()
第一个参数为被替换对象,第二个参数为替换成什么,第三个参数为替换地址,第四个参数为替换次数。
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.sub('better', '666', text, count=1))
执行结果:

利用sub()进行删除操作
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.sub(', dou.*', '', text))
执行结果:

4.分割方法split()
最简单的分割:
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.split(', ', text))
执行结果:

利用数字分割:
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.split('d+ ', text))
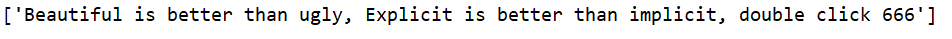
5.匹配整个字符串所有的匹配对象findall()
返回一个迭代对象,存储于列表之中。
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.findall('is w+',text))
执行结果:
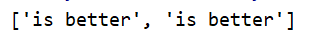
如果加括号,则括号内的为匹配对象。
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
print(re.findall('is (w+)',text))
执行结果:
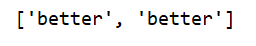
6.complie函数根据一个模式字符串和可选的标志参数生成一个字符表达式对象,该对象拥有一系列方法用于正则表达式匹配和替换。
对需要匹配的模式尽心预编译,会让速度变快。可以直接在预编译下进行查找。
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
pat = re.compile('is (w+)').findall(text)
print(pat)
执行结果:
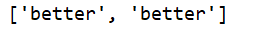
7.使用不同模式查找
常用的正则表达式模式
import re
text = "Beautiful is better than ugly, Explicit is better than implicit, double click 666"
# []表示 或者的意思
pat = re.compile('[une]').findall(text)
print(pat)
执行结果:

8.对进行转义
正则表达式实例:
提取部分内容
import re
html = """
<html>
<head>
<base href='http://example.com/'/>
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name:My image 1 <br /><img src='image1_thumb.jph'/></a>
<a href='image2.html'>Name:My image 2 <br /><img src='image2_thumb.jph'/></a>
<a href='image3.html'>Name:My image 3 <br /><img src='image3_thumb.jph'/></a>
<a href='image4.html'>Name:My image 4 <br /><img src='image4_thumb.jph'/></a>
<a href='image5.html'>Name:My image 5 <br /><img src='image5_thumb.jph'/></a>
</div>
"""
# 根据前后内容,构造正则表达式模式
print(re.compile("image1.html'>(.*)<br />").findall(html))
执行结果:

提取所有文本
import re
html = """
<html>
<head>
<base href='http://example.com/'/>
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name:My image 1 <br /><img src='image1_thumb.jph'/></a>
<a href='image2.html'>Name:My image 2 <br /><img src='image2_thumb.jph'/></a>
<a href='image3.html'>Name:My image 3 <br /><img src='image3_thumb.jph'/></a>
<a href='image4.html'>Name:My image 4 <br /><img src='image4_thumb.jph'/></a>
<a href='image5.html'>Name:My image 5 <br /><img src='image5_thumb.jph'/></a>
</div>
"""
# 找所有文本的共同内容
print(re.compile("html'>(.*)<br />").findall(html))
提取属性
import re
html = """
<html>
<head>
<base href='http://example.com/'/>
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name:My image 1 <br /><img src='image1_thumb.jph'/></a>
<a href='image2.html'>Name:My image 2 <br /><img src='image2_thumb.jph'/></a>
<a href='image3.html'>Name:My image 3 <br /><img src='image3_thumb.jph'/></a>
<a href='image4.html'>Name:My image 4 <br /><img src='image4_thumb.jph'/></a>
<a href='image5.html'>Name:My image 5 <br /><img src='image5_thumb.jph'/></a>
</div>
"""
print(re.compile("a href='(w+.w+)").findall(html))
执行结果:

最后
以上就是干净仙人掌最近收集整理的关于爬虫:python爬虫学习笔记之Beautifulsoup&正则表达式Beautifulsoup正则表达式正则表达式实例:的全部内容,更多相关爬虫内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复