用Python写了一个简单的爬虫,实现抓取图片素材,源代码可以查看我的GitHub:https://github.com/corolcorona/spider_demo
1.抓取图片链接:http://sc.chinaz.com/tupian/fengyetupian.html
选择查看源代码,需要注意的是图片路径,也就是我们要抓取的内容,可以看到每个div标签下包含一个图片,alt是图片的描述,src2为图片的路径

2.新建一个Python项目
首先我用的环境是Mac,关于Mac下怎样新建一个Python项目,可以参考:http://www.cnblogs.com/corolcorona/p/6678197.html
3.安装Python库
有用到2个库,1个是urllib2(不需要安装)用于抓取URL,1个是BeautifulSoup,用于解析抓取下来的HTML
关于安装BeautifulSoup,可以参考:http://www.cnblogs.com/corolcorona/p/6667698.html
4.写代码
import urllib2 import urllib import os from BeautifulSoup import BeautifulSoup def getAllImageLink(): html = urllib2.urlopen('http://sc.chinaz.com/tupian/fengyetupian.html').read() soup = BeautifulSoup(html) liResult = soup.findAll('div',attrs={"class":"box picblock col3"}) print len(liResult) for li in liResult: imageEntityArray = li.findAll('img') for image in imageEntityArray: link = image.get('src2') imageName = image.get('alt') filesavepath = '/Users/corolcorona/desktop/picture/%s.jpg' % imageName urllib.urlretrieve(link,filesavepath) if __name__ == '__main__': getAllImageLink()
urllib2.urlopen方法抓取了网页的HTML
BeautifulSoup.findAll方法解析了抓取下来的HTML
urllib.urlretrieve方法保存到指定路径
5.可以增加一个循环抓取下一页的数据
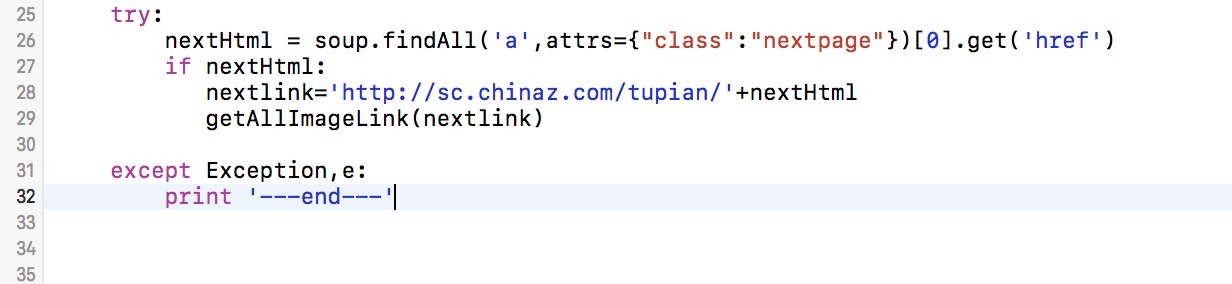
转载于:https://www.cnblogs.com/corolcorona/p/6721983.html
最后
以上就是专一大米最近收集整理的关于beautiful Soup实现抓取图片素材的全部内容,更多相关beautiful内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复