网路爬虫是python最重要的应用之一,甚至有很多地方认为python就是用来做网抓的。这里将用大约20行代码展示一个从人民银行官网抓取当日人民币美元汇率的示例来入门这项技术。
和我们平时手动上网寻找信息一样,使用python爬虫主要由以下几个步骤。
一、打开网页。
我们需要使用python自带的urlopen的方法得到网页的反馈信息对象response,然后通过response对象的read方法获得代表网页源代码的字节流信息。
二、解析网页。
手动解析要编写大量的代码,这里要祭出我大BeautifulSoup方法,这个方法就像搅和汤一样搅和网页的源代码信息,最终输出一个用来分析网页标签的BeautifulSoup对象。
三、精准定位。
BeautifulSoup也和网页一样,是一个类似套娃的结构,一层一层的关系比较规整,所以我们可以使用类似正则表达式的.find_all()方法来让让BS定位到需要的标签。
四、存储信息。
我们可以使用循环的方法把需要的这些信息依次存在列表里面。此例当中,我们使用了pandas中的DataFrame来存储该页货币的现钞买入价、现钞卖出价。然后使用DF数据的读取方法来打印美元的信息。
关于pandas中DF数据的操作,参见博文pandas中数据的操作
具体的代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
r = urlopen('http://www.boc.cn/sourcedb/whpj/') #r是一个HttpResponse的对象
c = r.read().decode('utf-8') #使用HttpResponse的read函数读取之后用decode翻译成人类语言
bs_obj = BeautifulSoup(c,features='lxml')#构造了一个BeatifulSoup的对象
t = bs_obj.find_all('table')[1] #找到第一个table,findall找到所有放到列表中,t的数据类型是Tag类
trs = t.find_all('tr') #trs是一个ResultSet集合
trs.pop(0)
c_name,s_price,b_price = [],[],[]
for tr in trs:
tds = tr.find_all('td')
c_name.append(tds[0].text) #text属性相当于去掉了标签
s_price.append(tds[4].text) #输出现钞卖出价
b_price.append(tds[2].text)
toe = pd.DataFrame({
"现钞买入价" : b_price,
"现钞卖出价" : s_price,
},index = c_name
)
print(toe.loc['美元'])
最终输出的结果:
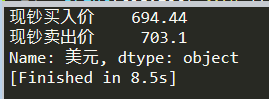
最后
以上就是甜甜爆米花最近收集整理的关于20行python代码入门网络爬虫全流程:使用BeautifulSoup抓取当日人民银行外汇数据的全部内容,更多相关20行python代码入门网络爬虫全流程内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复