Hadoop单词统计实验
一、搭建思路
1. 使用前期搭建好的伪分布式hadoop系统(单节点部署方案)作为Hadoop的基础环境平台,如果对前期Hadoop基础平台搭建不熟悉可以关注CSDN的博客,有详细说明,详细地址如下:https://blog.csdn.net/arnoldmapo/article/details/104964971
2. 运用环境中自带Wordcount.java程序实现单词统计
二、单词统计实验步骤
1、开启搭建好的Hadoop平台虚拟机
2、远程接入系统
3、开启Hadoop的服务进程
(1)进入Hadoop目录
使用命令:cd /opt/hadoop/hadoop/etc/hadoop/
![]()
(2)开启节点服务进程
使用命令:start-all.sh
![]()
(3)服务已经开启
使用命令:jps

(4)查看集群状态
使用命令:hadoop dfsadmin -report
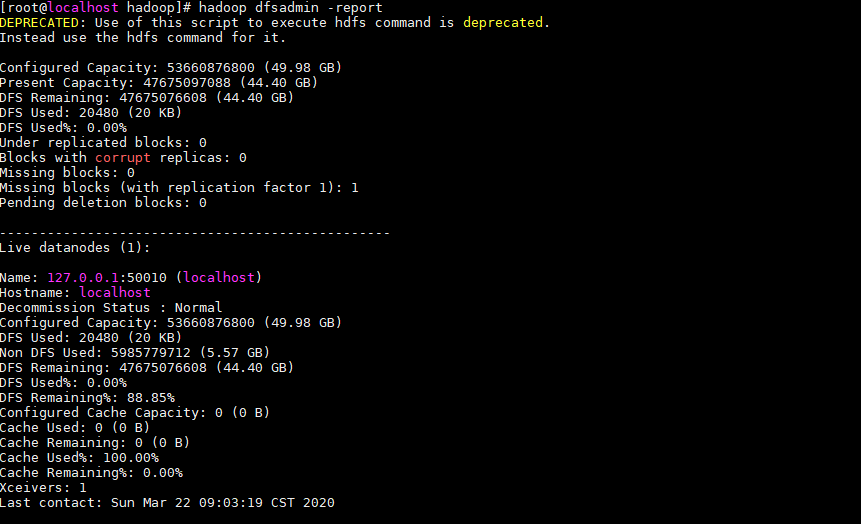
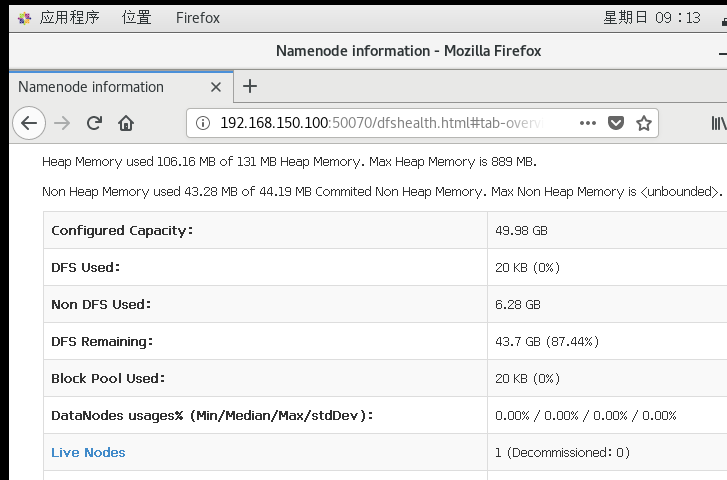
(5)通过web查看
使用命令:http://192.168.150.100:50070/
4、运行Wordcount.java程序实现单词统计
(1)在“/opt/test”目录下创建文件mp.txt,并写入一段单词
使用命令:vi mp.txt
![]()
复制一段单词进去:This is a test,hello,Hadoop,my name is mp , This is a test,hello,Hadoop,my name is mp , This is a test,hello,Hadoop,my name is mp , This is a test,hello,Hadoop,my name is mp , This is a test,hello,Hadoop,my name is mp编辑成功
(2)在hdfs上建立一个输入文件夹input,用于上传源文件
使用命令:hdfs dfs -mkdir /input
![]()
(3)查看已经建立成功
使用命令:hdfs dfs -ls /

(4)上传本地文件mp.txt 到hdfs上input中
使用命令:hdfs dfs -put mp.txt /input
![]()
(5)查看已经上传成功
使用命令:hdfs dfs -cat /input/mp.txt

(6)在集群上运行 WordCount 程序
以 input 作为输入目录,output 目录作为输出目录(output不需要创建,需要自动创建)。
已经编译好的WordCount的Jar在 “/opt/hadoop/hadoop/share/hadoop/mapreduce/”下面,就是“hadoop-mapreduce-examples-2.8.3.jar”。
进入目录并查看,使用命令:cd /opt/hadoop/hadoop/share/hadoop/mapreduce/
(7)执行MapReduce进行单词统计
每次运行前请先删除输出目录,因为他是自动生成的;或者每次都创建一个新的目录,否则会运行失败。
使用命令:hadoop jar /opt/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /input /output
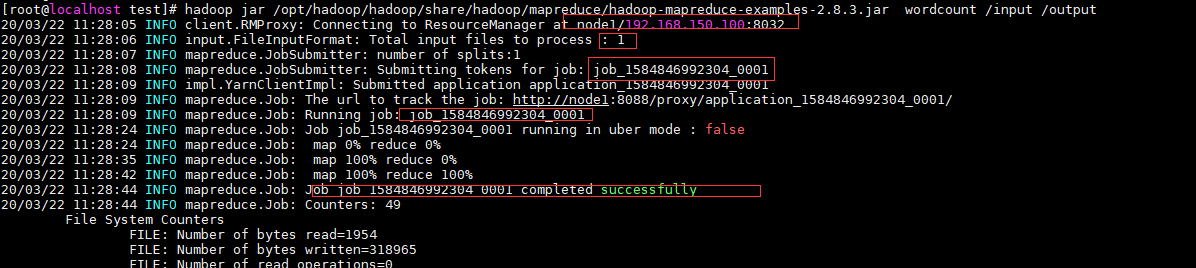
Hadoop 命令会启动一个 JVM 来运行这个 MapReduce 程序,并自动获得 Hadoop 的配置,同时把类的路径(及其依赖关系)加入到 Hadoop 的库中。以上就是 Hadoop Job 的运行记录,从这里可以看到,这个 Job 被赋予了一个 ID 号:job_1584846992304_0001,而且得知输入文件有1个(Total input files to process : 1)
5、查看结果
(1)查看 HDFS 上 output 目录内容
使用命令:hdfs dfs -ls /output

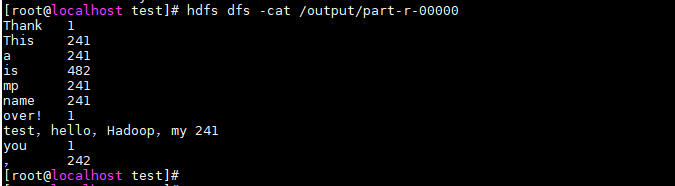
(2)我们的结果在“part-r-00000”中
使用命令:hdfs dfs -cat /output/part-r-00000
三、问题解决
1、启动map统计不成功
(1)报错信息如下

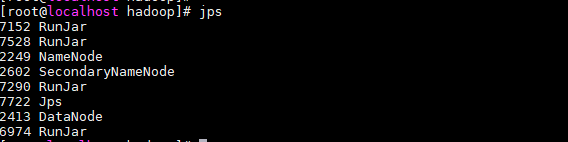
(2)图中发现链接RM遭到拒绝,通过jps查看发现没有RM节点
(3)重启RM节点,使用命令:yarn-daemon.sh start resourcemanager

(4)问题解决
最后
以上就是冷艳钢铁侠最近收集整理的关于Hadoop单词统计实验Hadoop单词统计实验 一、搭建思路 二、单词统计实验步骤 三、问题解决的全部内容,更多相关Hadoop单词统计实验Hadoop单词统计实验内容请搜索靠谱客的其他文章。








发表评论 取消回复