文章目录
- Step 1. 数据格式准备
- Step 2. Mapper
- Step 3. Reducer
- Step 4. 定义主类, 描述 Job 并提交 Job
- 在集群上运行
- 1. 将程序打包为jar包
- 2.在集群上运行MapReduce程序
需求: 在一堆给定的文本文件中统计输出每一个单词出现的总次数
Step 1. 数据格式准备
-
创建一个新的文件
cd /export/servers vim wordcount.txt -
向其中放入以下内容并保存
hello,world,hadoop hive,sqoop,flume,hello kitty,tom,jerry,world hadoop -
上传到 HDFS
hdfs dfs -mkdir /wordcount/ hdfs dfs -put wordcount.txt /wordcount/
Step 2. Mapper
首先还是要配置pom.xml文件
<!--最后要打包成jar包-->
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
创建一个包MapReduceDemo1
然后重新编写mapper逻辑
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
四个泛型:
KEYIN:K1的类型
VALUEIN:V1的类型
KEYOUT:K2的类型
VALUEOUT:V2的类型
*/
// hadoop中数据需要经常进行序列化,因此在Java中的数据结构较为臃肿
// 因此一般使用hadoop中的数据类型,如LongWritable, Text都是hadoop自带的数据类型
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/*
map是将K1,V1转为K2,V2
K1 V1
0 hello,world,hadoop
12 hdfs,hive,hello
---------------------------------
K2 V2
hello 1
world 1
hadoop 1
hdfs 1
hive 1
hello 1
*/
@Override
//protected void map(KEYIN key, VALUEIN value, Context context)
protected void map(LongWritable key, Text value, Context context) throws InterruptedException, IOException {
// 对每一行数据进行拆分
// Text不能直接进行拆分
String line = value.toString();
String[] split = line.split(",");
//遍历数组,得到K2和V2
for (String word : split) {
context.write(new Text(word),new LongWritable(1));
}
}
}
Step 3. Reducer
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
/*
Reduce是将K2,V2转为K3,V3
K2 V2
hello <1,1>
world <1>
hadoop <1>
hdfs <1>
hive <1>
---------------------------------
K3 V3
hello 2
world 1
hadoop 1
hdfs 1
hive 1
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
/*
key:K3
values:V3
context:上下文对象
*/
long count = 0;
// 遍历集合
for (LongWritable value : values) {
count += value.get();
}
// 将K3和V3写入context
context.write(key,new LongWritable(count));
}
}
Step 4. 定义主类, 描述 Job 并提交 Job
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class main extends Configured implements Tool {
//指定一个job任务
@Override
public int run(String[] args) throws Exception {
// 创建job任务对象, 获取的是main中的Configuration
Job job = Job.getInstance(super.getConf(), "wordCount");
//打包到集群上面运行时候,必须要添加以下配置,指定程序的main函数
job.setJarByClass(main.class);
//第一步:读取输入文件解析成key,value对
job.setInputFormatClass(TextInputFormat.class);
//读取源文件
//文件在hdfs上
TextInputFormat.addInputPath(job, new Path("hdfs://hadoop1:8020/wordcount"));
//文件在本地
// TextInputFormat.addInputPath(job, new Path("file:///E:\atest\hello.txt"));
//第二步:设置我们的mapper类
job.setMapperClass(WordCountMapper.class);
//设置我们map阶段完成之后的输出类型,即K2和V2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//第三步,第四步,第五步,第六步采用默认方式,本案例不重新设置
//第七步:设置我们的reduce类
job.setReducerClass(WordCountReducer.class);
//设置我们reduce阶段完成之后的输出类型,K3和V3的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步:设置输出类以及输出路径
job.setOutputFormatClass(TextOutputFormat.class);
// 输出存到HDFS上
Path path = new Path("hdfs://hadoop1:8020/wordcount_out");
// 判断路径是否存在文件
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop1:8020"), new Configuration());
boolean exists = fileSystem.exists(path);
// 如果目标路径存在,删除之前的
if(exists){
fileSystem.delete(path,true);
}
TextOutputFormat.setOutputPath(job,path);
// 输出存到本地
// TextOutputFormat.setOutputPath(job,new Path("file:///E:\atest\output"));
// 等待任务结束
boolean b = job.waitForCompletion(true);
return b?0:1;
}
/**
* 程序main函数的入口类
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
// 启动job任务,返回int,0表示失败
int run = ToolRunner.run(configuration, new main(), args);
System.exit(run);
}
}
如果有log4j Warning,可以在resorces下新建一个log4j.properties
# Configure logging for testing: optionally with log file
#log4j.rootLogger=debug,appender
log4j.rootLogger=info,appender
#log4j.rootLogger=error,appender
#u8F93u51FAu5230u63A7u5236u53F0
log4j.appender.appender=org.apache.log4j.ConsoleAppender
#u6837u5F0Fu4E3ATTCCLayout
log4j.appender.appender.layout=org.apache.log4j.TTCCLayout
在集群上运行
1. 将程序打包为jar包
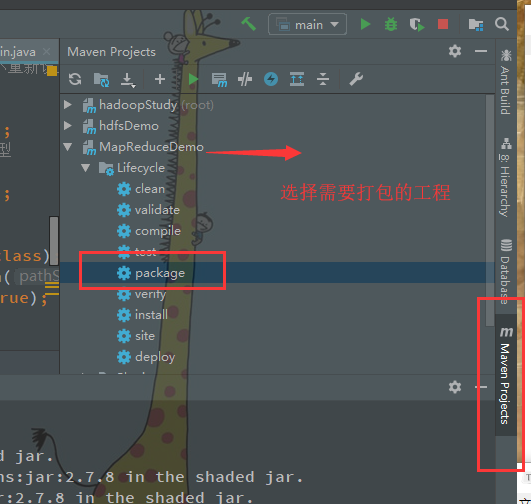
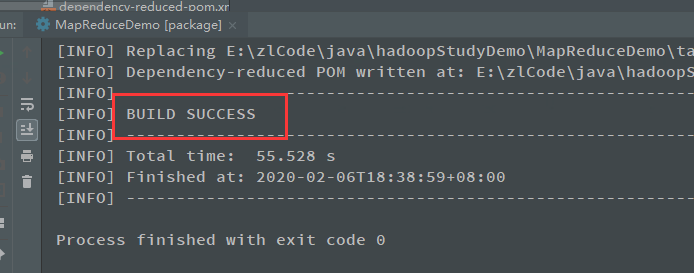
打包后的jar包
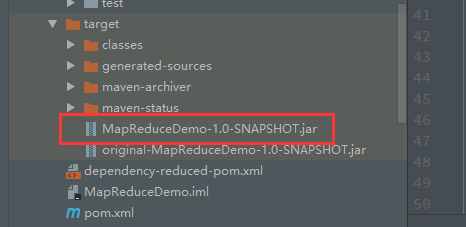
MapReduceDemo-1.0-SNAPSHOT.jar是把所有依赖包都打包在一起
original-MapReduceDemo-1.0-SNAPSHOT.jar未打包依赖包
2.在集群上运行MapReduce程序
- 上传jar包
cd /export/servers/
mkdir jar_test
rz -E
- 运行程序
hadoop jar jar包名 主方法位置
hadoop jar MapReduceDemo-1.0-SNAPSHOT.jar MapReduceDemo1.main
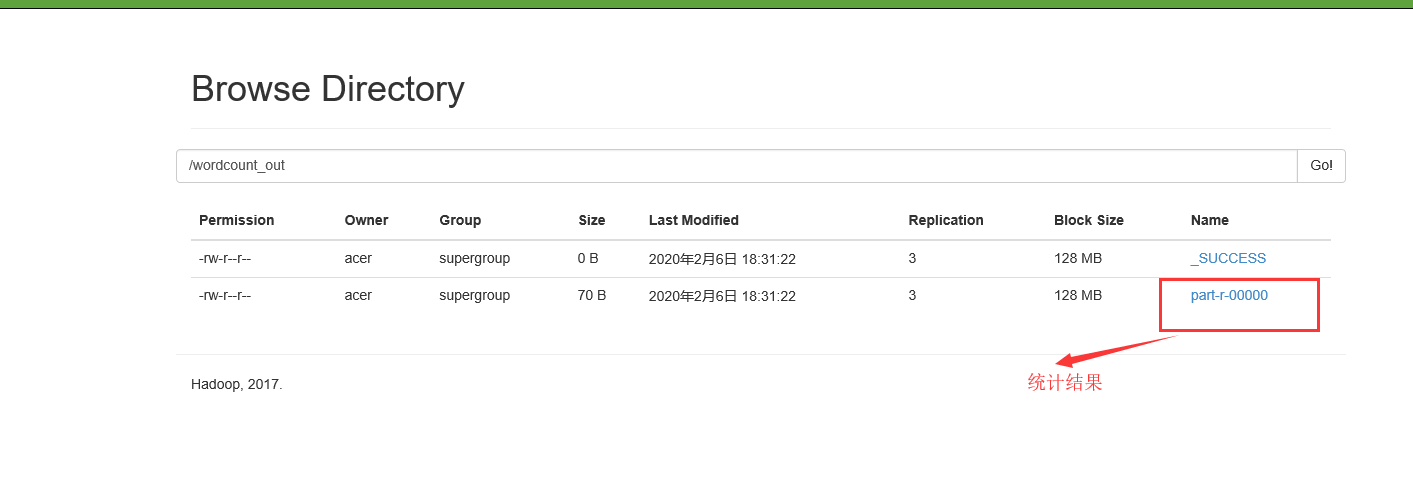
最后
以上就是务实泥猴桃最近收集整理的关于MapReduce实例1-统计文本单词个数的全部内容,更多相关MapReduce实例1-统计文本单词个数内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复