对于给定的video日志数据,先利用mapreduce程序进行数据清洗,把数据的存储格式按我们的要求存入文件。
一、数据清洗代码
mapper端对数据清洗后直接输出,不需要reduce阶段
public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable>{
private Counter pass;
private Counter fail;
private StringBuilder sb = new StringBuilder();
private Text result = new Text();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
pass = context.getCounter("ETL", "Pass");
fail = context.getCounter("ETL","Fail");
}
/**日志样例:SDNkMu8ZT68 w00dy911 630 People & Blogs 186 10181 3.49 494 257 rjnbgpPJUks
* 将一行的日志进行处理,字段不够的抛弃,将第四个字段中的空格去掉,将最后的相关视频的分隔符改成‘&’
* @param key 行偏移量
* @param value 这行内容
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//一行数据
String line = value.toString();
//这样切分会把最后一个字段的数据切开,需要最后做拼接
String[] fields = line.split("t");
//每一行数据都会进入map一次,sb是可变字符串,所以每次进来需要清零。
sb.setLength(0);
//先判断字段个数够不够
if (fields.length >= 9){
//去掉第四个字段的空格(视频标签字段的数组用&连接) 样例:People & Blogs
fields[3] = fields[3].replace(" ","");
//拼接字段
for (int i = 0; i < fields.length; i++) {
if (i == fields.length-1){ //相关视频的最后一个,不用做处理,直接添加
sb.append(fields[i]);
}else if (i <= 8){ //前九个字段之间用t隔开
sb.append(fields[i]).append("t");
}else{ //相关视频字段用&隔开
sb.append(fields[i]).append("&");
}
}
result.set(sb.toString());
context.write(result,NullWritable.get());
pass.increment(1);
}else {
//如果字段不够,舍弃不要
fail.increment(1);
}
}
}driver端
public class ETLToolDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//使用tez引擎
// conf.set("mapreduce.framework.name","yarn-tez");
Job job = Job.getInstance(conf);
job.setJarByClass(ETLToolDriver.class);
job.setMapperClass(ETLMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}①程序编写完成后,现在本地模式下跑一遍看看有没有问题,没问题的话,直接打包上传到集群
②将要清洗数据的文件提前上传到hdfs
在hadoop服务器端执行如下代码实现数据清洗
yarn jar /opt/module/hadoop/上传的jar包名 driver类的reference引用 hdfs上的文件目录 清洗后存放的目录
我的代码
yarn jar /opt/module/hadoop/etltool-1.0-SNAPSHOT.jar com.atguigui.etl.ETLToolDriver /gulivideo/video /gulivideo/video_etl在hive端创建数据库并使用该数据库
create database gulivideo;
use gulivideo;创建两张外部表
create external table video_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "t"
collection items terminated by "&"
location '/gulivideo/video_etl';create external table user_ori(
uploader string,
videos int,
friends int)
row format delimited fields terminated by "t"
location '/gulivideo/user';在创建两张内部表并添加数据到内部表
create table video_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "t"
collection items terminated by '&'
stored as orc
tblproperties("orc.compress"="snappy");create external table user_orc(
uploader string,
videos int,
friends int)
row format delimited fields terminated by "t"
stored as orc
tblproperties("orc.compress"="snappy");insert into table video_orc select * from video_ori;
insert into table user_orc select * from user_ori;需求①:统计视频播放量Top10
select
videoid,views
from
video_orc
order by
views desc
limit 10; 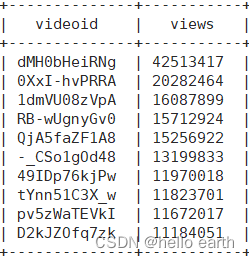
需求②:统计视频类别热度Top10
第一步:把类别字段的数组炸开
select
videoid,cate
from
video_orc
lateral view
explode(category) tbl as cate;
第二步:根据第一步的结果,分类统计各个类别的数目并作排序输出目标数据
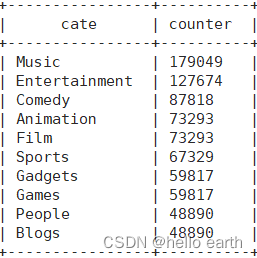
select
cate,count(videoid) as counter
from(
select
videoid,cate
from
video_orc
lateral view
explode(category) tbl as cate) tbl
group by cate
order by counter desc
limit 10;
需求③:统计视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
第一步:统计观看数最高的20个视频以及类别
select
videoid,category,views
from
video_orc
order by views desc
limit 20;
//第二步:根据①的结果,将category炸开。
select cate,videoid
from(
select
videoid,category,views
from
video_orc
order by views desc
limit 20) t1
lateral view
explode(category) tbl as cate;
第三步:按照炸开后的类别分组,统计个数
select cate,count(videoid) n
from(
select cate,videoid
from(
select
videoid,category,views
from
video_orc
order by views desc
limit 20) t1
lateral view
explode(category) tbl as cate
) t2
group by cate
order by n desc; 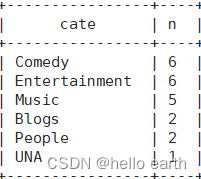
需求④:统计视频观看数Top50 所关联视频的所属类别排序
第一步:统计Top50的关联视频
select
videoid,views,relatedid
from
video_orc
order by views desc
limit 50;
第二步:炸开相关视频的数组
select
explode(relatedid) videoid
from(
select
videoid,views,relatedid
from
video_orc
order by views desc
limit 50
) t1;
第三步:和原表join获取category
select distinct t2.videoid,v.category
from(
select
explode(relatedid) videoid
from(
select
videoid,views,relatedid
from
video_orc
order by views desc
limit 50
) t1
) t2
join video_orc v
on t2.videoid=v.videoid;
第四步:炸开第三步中得到的category
select videoid,cate
from(
select distinct t2.videoid,v.category
from(
select
explode(relatedid) videoid
from(
select
videoid,views,relatedid
from
video_orc
order by views desc
limit 50
) t1
) t2
join video_orc v
on t2.videoid=v.videoid
) t3
lateral view
explode(category) tbl as cate;
第五步:将第四步的结果按照cate分组并计数排序后输出
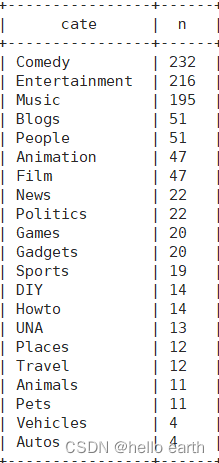
select cate,count(videoid) n
from(
select videoid,cate
from(
select distinct t2.videoid,v.category
from(
select
explode(relatedid) videoid
from(
select
videoid,views,relatedid
from
video_orc
order by views desc
limit 50
) t1
) t2
join video_orc v
on t2.videoid=v.videoid
) t3
lateral view
explode(category) tbl as cate
) t4
group by
cate
order by n desc;
需求⑤:统计每个类别中的视频热度Top10,以music为例
//创建一张中间表格,把category字段炸开
create table video_category
stored as orc
tblproperties("orc.compress"="snappy") as
select
videoid,uploader,age,cate,length,views,rate,ratings,comments,relatedid
from
video_orc
lateral view
explode(category) tbl as cate;
//从中间表格查询
select
videoid,views,cate
from
video_category
where
cate='Music'
order by views desc
limit 10;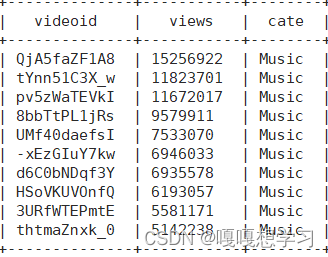
需求⑥:统计每个类别中视频流量Top10,以Music为例
//直接在需求⑤生成的中间表查询
select videoid,ratings
from video_category
where cate='Music'
order by ratings desc
limit 10; 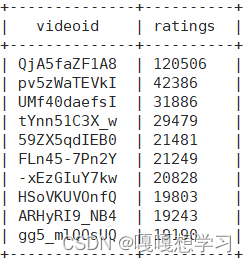
需求⑦:统计上传视频最多的用户Top10 以及他们上传的观看次数在前20的视频
理解一:Top用户和他们的播放量Top20
第一步:统计上传视频数Top10
select
uploader,videos
from
user_orc
order by videos desc
limit 10;
第二步:和video_orc表join查看这些用户都上传了哪些视频和视频观看数
select t1.uploader,v.videoid,
rank() over(partition by t1.uploader order by v.views desc) hot
from(
select
uploader,videos
from
user_orc
order by videos desc
limit 10
) t1
left join video_orc v
on t1.uploader = v.uploader;
第三步:根据第二步的结果排序
select t2.uploader,t2.videoid,t2.hot
from(
select t1.uploader,v.videoid,
rank() over(partition by t1.uploader order by v.views desc) hot
from(
select
uploader,videos
from
user_orc
order by videos desc
limit 10
) t1
left join video_orc v
on t1.uploader = v.uploader
) t2
where t2.hot <= 20;理解二: 播放量Top20哪些是由上传量Top10用户上传的
//上传量Top10用户
select
uploader,videos
from
user_orc
order by videos desc
limit 10;
//播放量Top20
select
videoid,uploader,views
from
video_orc
order by views desc
limit 20;
//两表join查看
select t1.uploader,t2.videoid,t2.views
from(
select
uploader,videos
from
user_orc
order by videos desc
limit 10
) t1
left join (
select
videoid,uploader,views
from
video_orc
order by views desc
limit 20
) t2
on t1.uploader=t2.uploader;需求⑧:统计每个类别视频的观看数Top10
//从video_category表中查videoid,views和按类别分组的播放量排名
select cate,videoid,views,
rank() over(partition by cate order by views desc) hot
from
video_category;
//从①的结果中输出各个类别的播放量Top10
select cate,videoid,views
from(
select cate,videoid,views,
rank() over(partition by cate order by views desc) hot
from
video_category
) t1
where hot <= 10;
最后
以上就是留胡子煎饼最近收集整理的关于hive实战——谷粒影音一、数据清洗代码的全部内容,更多相关hive实战——谷粒影音一、数据清洗代码内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复