决策树是一种贪心算法,每次选取的分割数据的特征都是当前的最佳选择,并不关心是否达到最优。
ID3使用信息增益作为属性选择度量,选择具有最高信息增益的属性A作为节点N的分裂属性。
对D中的元组分类所需要的期望信息(熵):![]()
![]() 是任意元组属于类Ci 的概率。熵越小,说明样本集合D的纯度越高。
是任意元组属于类Ci 的概率。熵越小,说明样本集合D的纯度越高。
按某个属性A划分对D的元组分类所需要的期望信息:![]()
信息增益:Gain(A)= ![]() -
- ![]()
一般来说,信息增益越大,说明如果用属性a来划分样本集合D,那么纯度会提升,因为我们分别对样本的所有属性计算增益情况,选择最大的来作为决策树的一个节点。
ID3决策树的缺点在于,当一个属性的可取值数目较多时,那么可能在这个属性值对应的可取值下的样本只有一个或多个,那么这个时候它的信息增益是非常高的,这个时候纯度很高,ID3决策树会认为这个属性很适合划分,但是较多取值的属性来进行划分带来的问题是它的泛化能力比较弱,不能对新样本进行有效的预测。ID3不能处理特征值为连续的情况。
作为ID3的改进,C4.5使用一种称为增益率的信息增益扩充。
增益率的本质是在信息增益的基础上乘一个惩罚函数。特征取值个数较多时,SplitInfo较大,则增益率较小。特征取值较少时,SplitInfo较小,则增益率较大。也就是说增益率对可取值数目较少的属性有所偏好。
分裂信息: ![]()
增益率为: ![]()
需要注意的是,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
相比ID3算法改进:
- 使用信息增益率作为分裂标准
- 处理含有缺失值的样本方法为将这些值并入最常见的某一类或以最常见的值代替
- 处理连续值属性
但是C4.5倾向于产生不平衡的划分,其中一个分区比其他分区小得多。
CART构成的是一个二叉树。即使一个属性有多个取值,也是把数据分为两部分。
基尼指数:反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。
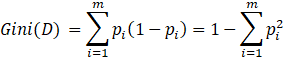
基尼指数越小,则数据集D的纯度越高。
属性A的基尼指数定义为 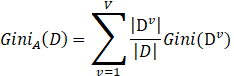
我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。CART分类树通过基尼指数选择最优特征,同时决定该特征的最优二值切分点。
如果属性A的二元划分把D划分成D1和D2,则给定该划分,D的基尼指数为:
![]()
对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的基尼指数,然后从所有的可能划分中找出Gini指数最小的划分,这个划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
与ID3和C4.5不同,CART不仅可以用于分类,还可用于回归;ID3、C4.5生成的决策树是多叉的,每个节点下的叉数由该节点特征的取值而定,而CART假设决策树为二叉树,内部节点特征取值为“是”“否”;ID3、C4.5计算的数值是针对每一个特征,不将特征划分,CART为求所有特征下的所有切分点后进行比较来划分。
CART树的生成:
(1) 设结点的训练数据集为D,计算现有特征对该数据集的基尼指数.此时,对于每个特征,每次取其中一个每个可能取得值,根据样本点对该值的测试结果为”是”或”否”将D分成2部分,并计算基尼指数.
(2) 在所有可能的特征,以及他们所有可能的切分点中,选择基尼指数最小的特征,该选择的特征为最优特征,该特征中的切分点为最优切分点,依照最优特征和最优切分点生成二叉树,并把训练数据集分配到子节点中。
(3)对两个子节点递归调用 (1) (2) ,直至满足停止条件
(4)生成CART决策树。
剪枝处理是决策树对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,节点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好”了,以致于把训练集自身的一些特点当做所有数据共有的一般性质而导致过拟合。
预剪枝指在决策树生成过程中,对每个节点在划分前进行估计,若当前节点的划分不能为决策树带来泛化能力(用验证数据集来评价)的提升,则停止划分并将当前节点标记为叶子节点。
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶子节点进行考察,若将该节点对应的子树替换成叶节点能带来决策树泛化能力的提升,则将该子树替换成叶节点。
伪代码:
算法:Generate_decision_tree。由数据分区D中的训练元组产生决策树。
输入:
数据分区D,训练元组和它们对应的类标号集合。
attribute_list,候选属性的集合
Attribute_selection_method,一个确定“最好地”划分数据元组为个体类的分裂准则的过程。
输出:一棵决策树。
方法:
创建一个节点N;
if D中的元组都在同一个类C中then
返回N作为叶节点,以类C标记;
if attribute_list为空then
返回N作为叶节点,标记为D中的多数类; //多数表决
使用Attribute_selection_method(D,attribute_list),找出“最好地”splitting_criterion;
用splitting_criterion标记节点N;
if splitting_criterion是离散值的,并且允许多路划分then //不限于二叉树
attribute_list attribute_list-splitting_criterion; //删除分裂属性
for splitting_criterion的每个输出j
//划分元组并对每个分区产生子树
设Dj为D中满足输出j的数据元组的集合; //一个分区
if Dj为空then
加一个树叶到节点N,标记为D中的多数类;
else 加一个由Generate_decision_tree(Dj,attribute_list)返回的节点到N;
endfor
返回N;
ID3的python实现:
from math import log
import operator
import numpy as np
from sklearn import datasets
iris=datasets.load_iris()
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels
#计算给定数据集的香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
#按照给定特征划分数据集
#对第一个特征以1值划分结果如下
#In[7]: splitDataSet(myDat,0,1)
#Out[7]: [[1, 'yes'], [1, 'yes'], [0, 'no']]
def splitDataSet(dataSet, axis, value):#3个参数分别为待划分的数据集、划分数据集的特征、需要返回的特征的值
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #对每个特征
featList = [example[i] for example in dataSet]#找出特征值
uniqueVals = set(featList) #特征值唯一化
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)#找出以每个特征值划分的数据集
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet) #计算每种划分方式的信息熵
infoGain = baseEntropy - newEntropy #计算信息增益
#计算最好的信息增益
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回最好的特征
#多数表决法决定叶子节点的分类
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
#创建树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#类别完全相同则停止继续划分
if len(dataSet[0]) == 1: #遍历完所有的特征时返回出现次数最多的类别
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])#删除这个特征值
featValues = [example[bestFeat] for example in dataSet]#得到列表包含的所有属性值
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
sklearn 中的决策树:
titanic数据集来源于Kaggle
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import tree
import graphviz
import numpy as np
#读取数据
def read_dataset(fname):
#指定第一列作为行索引
data=pd.read_csv(fname,index_col=0)
#丢弃无用数据
data.drop(['Name','Ticket','Cabin'],axis=1,inplace=True)
#处理性别数据
labels=data['Sex'].unique().tolist()
data['Sex']=[*map(lambda x:labels.index(x),data['Sex'])]
#处理登船港口数据
labels=data['Embarked'].unique().tolist()
data['Embarked']=data['Embarked'].apply(lambda n:labels.index(n))
#处理缺失数据填充0
data=data.fillna(0)
return data
train=read_dataset('E:/Data/titanic/train.csv')
#print(train)
#拆分数据集
x=train.drop(['Survived'],axis=1).values
y=train['Survived'].values
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
#拟合数据集
clf=DecisionTreeClassifier(criterion="entropy")
clf.fit(x_train,y_train)
print(clf.score(x_test,y_test))
#通过max_depth参数(决策树最大深度)来优化模型
def cv_score(d):
clf=DecisionTreeClassifier(max_depth=d)
clf.fit(x_train,y_train)
return (clf.score(x_test,y_test))
depths=np.arange(1,10)
scores=[cv_score(d) for d in depths]
best_index=np.argmax(scores)
#因为train_test_split对数据切分是随机打散的,造成每次可能得到不同的最佳深度和最佳正确率。
print("bestdepth:",best_index+1,"bestdepth_score",scores[best_index],"n")
#通过min_impurity_split(节点划分最小不纯度,决策树分裂后信息增益低于这个阈值则不再分裂)来优化模型
def minsplit_score(val):
clf=DecisionTreeClassifier(min_impurity_split=val)
clf.fit(x_train,y_train)
return (clf.score(x_test,y_test))
vals=np.linspace(0,0.2,100)
scores=[minsplit_score(v) for v in vals]
best_index=np.argmax(scores)
print("bestmin:",vals[best_index],"bestminsplit_score:",scores[best_index],"n")
#画决策树
dot_data=tree.export_graphviz(clf,out_file=None)
graph=graphviz.Source(dot_data)
最后
以上就是风中小虾米最近收集整理的关于决策树的全部内容,更多相关决策树内容请搜索靠谱客的其他文章。


![[附源码]Node.js计算机毕业设计JAVA疫情社区管理系统Express](https://www.shuijiaxian.com/files_image/reation/bcimg25.png)



![[Graphviz]一些简单的例子(未完待续)1.设置点和线的形状和颜色2.设置点和线的位置(子图的概念)](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)

发表评论 取消回复