该代码是根据麦子学院的机器学习教程中的决策树算法课程内容:
1.csv的文件内容
rid,age,income,student,credit_rating,class_buy_computer
1,youth,high,no,fair,no
2,youth,high,no,excellent,no
3,middle_aged,high,no,fair,yes
4,senior,medium,no,fair,yes
5,senior,low,yes,fair,yes
6,senior,low,yes,excellent,no
7,middle_aged,low,yes,excellent,yes
8,youth,medium,no,fair,no
9,youth,low,yes,fair,yes
10,senior,medium,yes,fair,yes
11,youth,medium,yes,excellent,yes
12,middle_aged,medium,no,excellent,yes
13,middle_aged,high,yes,fair,yes
14,senior,medium,no,excellent,no
2.编写代码:
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
#读取csv文件的标题行
allElectronicsData = open(r'D:buy_computer.csv','rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
print(headers)
featureList=[]
labelList=[]
#读取csv文件的内容行,并整理成字典格式
for row in reader:
labelList.append(row[len(row)-1])
rowDict={}
for i in range(1,len(row)-1):
rowDict[headers[i]]=row[i]
featureList.append(rowDict)
print(featureList)
print(labelList)
#使用DictVectorizer中的各个属性列的不同属性值转换成0,1格式
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:"+str(dummyX))
print(vec.get_feature_names())
print("labelList:"+str(labelList))
#使用DictVectorizer中的标签列的不同属性值转换成0,1格式
lb=preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY :"+str(dummyY))
#使用tree的中DecisionTreeClassifier的信息熵差值方法构建决策树
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(dummyX, dummyY)
print("clf:" + str(clf))
#使用tree的中DecisionTreeClassifier的信息熵差值方法构建决策树
with open("allElectronicInformationGainOri.dot",'w') as f:
f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f)
#使用构建好的决策树来预测新的样本标签值
oneRowX = dummyX[0,:]
print("oneRowX:"+str(oneRowX))
newRowX = oneRowX
newRowX[0]=1
newRowX[2]=0
print("newRowX:"+str(newRowX))
predictedY= clf.predict(newRowX.reshape(1, -1))
print("predictedY"+str(predictedY))Console输出的结果为:
[‘rid’, ‘age’, ‘income’, ‘student’, ‘credit_rating’, ‘class_buy_computer’]
[{‘age’: ‘youth’, ‘income’: ‘high’, ‘student’: ‘no’, ‘credit_rating’: ‘fair’}, {‘age’: ‘youth’, ‘income’: ‘high’, ‘student’: ‘no’, ‘credit_rating’: ‘excellent’}, {‘age’: ‘middle_aged’, ‘income’: ‘high’, ‘student’: ‘no’, ‘credit_rating’: ‘fair’}, {‘age’: ‘senior’, ‘income’: ‘medium’, ‘student’: ‘no’, ‘credit_rating’: ‘fair’}, {‘age’: ‘senior’, ‘income’: ‘low’, ‘student’: ‘yes’, ‘credit_rating’: ‘fair’}, {‘age’: ‘senior’, ‘income’: ‘low’, ‘student’: ‘yes’, ‘credit_rating’: ‘excellent’}, {‘age’: ‘middle_aged’, ‘income’: ‘low’, ‘student’: ‘yes’, ‘credit_rating’: ‘excellent’}, {‘age’: ‘youth’, ‘income’: ‘medium’, ‘student’: ‘no’, ‘credit_rating’: ‘fair’}, {‘age’: ‘youth’, ‘income’: ‘low’, ‘student’: ‘yes’, ‘credit_rating’: ‘fair’}, {‘age’: ‘senior’, ‘income’: ‘medium’, ‘student’: ‘yes’, ‘credit_rating’: ‘fair’}, {‘age’: ‘youth’, ‘income’: ‘medium’, ‘student’: ‘yes’, ‘credit_rating’: ‘excellent’}, {‘age’: ‘middle_aged’, ‘income’: ‘medium’, ‘student’: ‘no’, ‘credit_rating’: ‘excellent’}, {‘age’: ‘middle_aged’, ‘income’: ‘high’, ‘student’: ‘yes’, ‘credit_rating’: ‘fair’}, {‘age’: ‘senior’, ‘income’: ‘medium’, ‘student’: ‘no’, ‘credit_rating’: ‘excellent’}]
[‘no’, ‘no’, ‘yes’, ‘yes’, ‘yes’, ‘no’, ‘yes’, ‘no’, ‘yes’, ‘yes’, ‘yes’, ‘yes’, ‘yes’, ‘no’]
dummyX:[[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[ 0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
[‘age=middle_aged’, ‘age=senior’, ‘age=youth’, ‘credit_rating=excellent’, ‘credit_rating=fair’, ‘income=high’, ‘income=low’, ‘income=medium’, ‘student=no’, ‘student=yes’]
labelList:[‘no’, ‘no’, ‘yes’, ‘yes’, ‘yes’, ‘no’, ‘yes’, ‘no’, ‘yes’, ‘yes’, ‘yes’, ‘yes’, ‘yes’, ‘no’]
dummyY :[[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
clf:DecisionTreeClassifier(class_weight=None, criterion=’entropy’, max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter=’best’)
oneRowX:[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
newRowX:[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY[1]
3.决策树dot文件的可视化(使用Graphviz软件将dot文件转化为pdf格式)
Graphviz下载地址:http://www.graphviz.org/download/
选择Windows下面的
Stable 2.38 Windows install packages 点击选择zip压缩包即可,然后解压。
在系统环境变量中添加该文件的安装目录下的bin(例如我的目录为:C:UsersAdministratorDesktop小论文外文文献-深度稀疏自动编码器graphviz-2.38releasebin,首先在原始的path值后面添加分号,然后再加上bin的路径)
可以将项目生成的allElectronicInformationGainOri.dot(可以右键点击“属性”,右面Location的值即为文件路径)
转换成pdf的命令:
打开cmd命令窗口,输入:dot -Tpdf E:WorkpaceAnacondaPyTestsrcallElectronicInformationGainOri.dot-o d:output.pdf
即在d盘下生成了output.pdf文件,打开文件,内容如下:
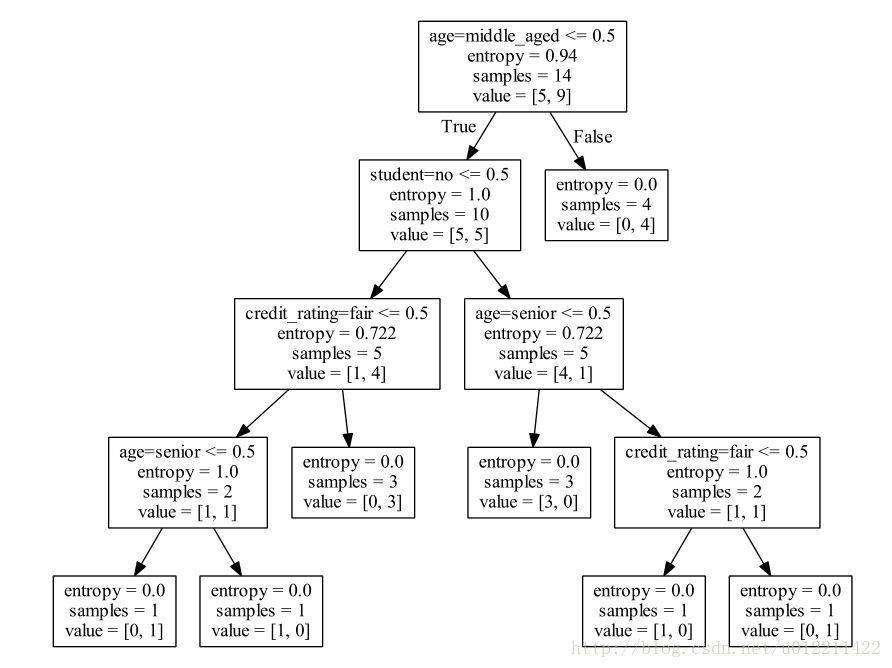
最后
以上就是不安奇迹最近收集整理的关于如何使用Pydev实现简单的决策树算法以及可视化的全部内容,更多相关如何使用Pydev实现简单内容请搜索靠谱客的其他文章。








发表评论 取消回复