上面两篇博客对机器学习有了简单的介绍,并介绍了机器学习中的一些基本的概念;下面我们来介绍机器学习中的第一个算法决策树算法DT(Decision Tree)。
介绍Decision Tree之前我先来引入一些经典的小例子来说明什么是决策树。如下面的图:
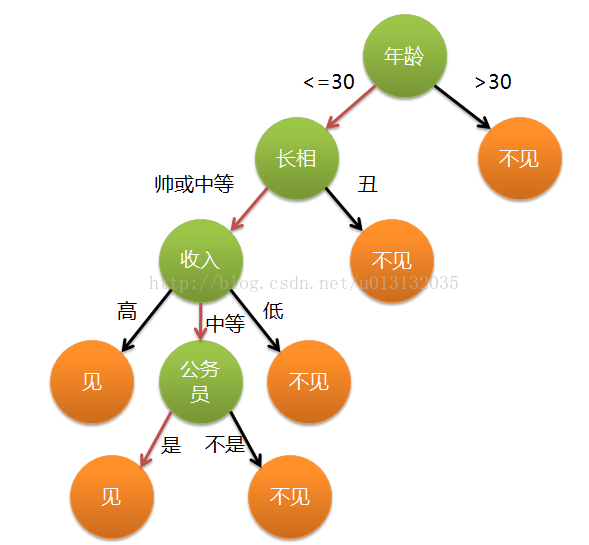
在当今这个社会尤其是我们这群程序员对象是一个很头疼的问题,于是就出现了非诚勿扰,缘来了,等等一些大型的综艺节目,有些时候由于子女工作忙的原因,于是有些地方也就出现了父母替子女见面,父母替子女见对方,不像年轻的子女一样看脸,而是内心默默的出现了一些评判标准,于是上面图片的分叉树就产生了,比如年龄最高不能超过30岁,否则不见,年龄在30岁以下,再看相貌,如果相貌难以接受,不见,如果相貌可以接受,于是现实问题就来了,收入怎么样,收入高的见,收入低的不见(不能让孩子吃苦啊),收入中等呢再看有没有铁饭碗,有呢就见,没有呢就不见,慢慢在无数父母中间就形成了这么一套不成文的规则,慢慢的被大家接受。但是呢,父母最终的愿望就是子女能幸福。有心的人看着上面的那副图片,有没有像我们数据结构常说的分叉树呢?可是我这分叉树代表了一些父母的决策,于是乎有了很高大上的名字-------决策树DT(Decision Tree)。当然决策树的典故肯定不是我说的这样,我只是想让大家形象的知道什么是决策树。其实上面的介绍父母给自己子女选择对象时,就很好的执行了机器学习中的决策树算法。其中绿色的圆圈就代表了一些判断条件和机制,而深橙色的圆圈就代表某一个实体在这个决策树中的执行结果-----见或者不见。
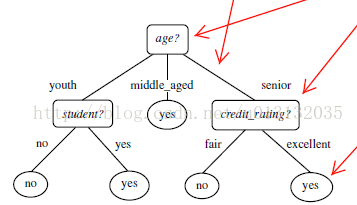
上面的图片也很好的体现了决策树算法,其中age是根节点,credit_rating是叶节点,yes是树叶,那条指着黑色线连接age和credit_rating的红色箭头是分支即判断条件。
下面来说一说决策树的概念及其定义。
决策树是在已经知道的各种情况的发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于0的概率,来评价一件事的风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一种预测模型,它代表了对象属性与对象值之间的一种映射关系。
决策树又称判定树:英文名字是Decision Tree;决策树是类似于流程图的树形结构,其中每个内部节点表示在一个属性上的测试,每个分支代表一个属性的输出,而每个树叶节点代表类或者类分布。树的最顶层是根节点。
决策树算法的重点在于决策树分裂的条件即决策树的构造过程:在决策树的构造过程中,我们需要一步一步的分裂这群实体的属性,使其找到一个合适的度使其分裂属性使每一个叶节点都相对来说比较单一,即结果统一;让同一个类别的属于一个叶节点,不同类别的不属于同一个节点。其中分裂可以分成两大类:
1:属性是连续的值。此时我们需要找到一个合适的split_point去分割这些属性,使这个属性可以很好地在split_point的两侧。然后尽可能使每个叶节点都是同一类别的实体结果。
2:属性是离散的值。此时又可以分成两种情况:离散值是否要求生成二叉树。a:如果要求生成二叉树,此时要用属性的划分的一个子集去测试,按照是否属于这个子集进行划分。b:如果不要求生成二叉树,则用每一个属性划分一个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂标准,是将给定的类标记的训练集合的数据划分D“最好”的分成个体类的的启发式方法,它决定了拓扑结构及分裂点split_point的选择。属性选择度量算法有很多,一般使用自顶向下的递归分治法,并采用不回溯的贪心策略。
在真正使用决策树算法之前,我们不得不先来说一说熵,因为这些算法的使用前提都是在熵的基础上。Entropy=系统的凌乱程度。决策树算法的ID3(贪心算法),C4.5(贪心算法)与C5.0生成树算法用熵。而熵这一度量是基于信息学理论中熵的概念。在信息和抽象如何度量时,香农在1948年提出来了“信息熵”的概念。一条信息的信息量大小和它的不确定性有着直接的关系,要搞清楚一件非常不确定的事情,或者是我们一无所知的事情,需要了解大量的信息,而信息量的度量就等于不确定性的多少。
例如我们要预测2017年NBA总冠军花落谁家,由于了解NBA的人都知道,比如湖人、76人、篮网等等球队,这几年都比较埋没,它们进季后赛都困难,不要说夺得总冠军,所以说它们夺得总冠军的概率比较小,可是我们不能说它们没有概率,万一强队比如卫冕冠军骑士,总决赛亚军勇士,常年“装死”的马刺(它们的夺冠概率比较高)主力球员都回家休息或者退役了呢,这里我们来衡量哪一个球队夺冠,我们可以知道它们的夺冠概率不等。这里我们用比特来衡量信息多少。公式如下:
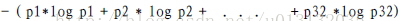
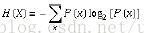
由公式我们可以知道变量的不确定性越大,公式的值H(X)就越来,信息的熵越大,即信息的量也就越大。
下面我就以ID3算法(决策树算法中的一个属于贪心算法,是J.Ross Quinlan在1970-1980年发明的)来说明决策树算法。其理论过称为:
以D为class_label算出对信息进行训练,pi代表第i个元组符合class_label的概率。则Class_Label D的信息熵为:
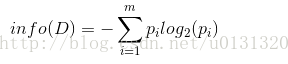
训练元组D按照属性A进行划分,则属性A对元组D的期望为:
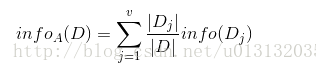
A的信息增益为:
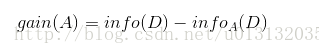
最后比较哪一个属性的信息增益最大就选择它作为节点进行分支。
下面用一个具体的例子来进行说明ID3算法。
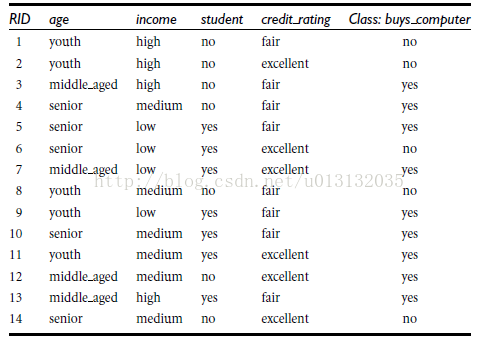
其中我们选择buy_computer的Yes Or No这个结果作为Class Label。算出buy_computer的熵:
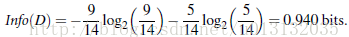
然后我们按照class_label为是否buy_computer按属性age、income、student、credit_rating来进行划分,则属性的age、income、student、credit_rating对元组buy_computer的期望进行计算算出信息增益最大的那个属性。
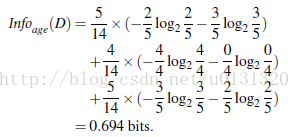
最后计算属性age的信息增益:
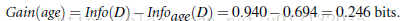
故以属性age为根节点进行划分。
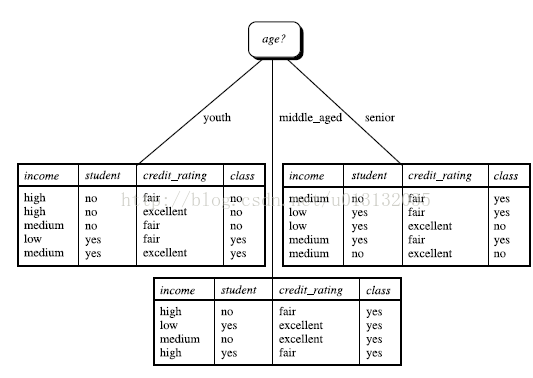
然后在根据上面的进行循环,直到叶节点class_label比较单一为止。决策树分裂完毕,得到完整的决策树。
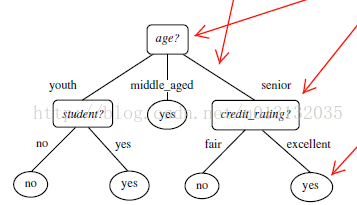
这就是用ID3算法分完结果的决策树。
算法总结:
1:树以代表训练样本的单个结点开始(步骤1)。
2:如果样本都在同一个类,则该结点成为树叶,并用该类标号(步骤2 和3)。
3:否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性(步骤6)。该属性成为该结点的“测试”或“判定”属性(步骤7)。在算法的该版本中,所有的属性都是分类的,即离散值。连续属性必须离散化。
4:对测试属性的每个已知的值,创建一个分枝,并据此划分样本(步骤8-10)。
5:算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代上考虑它(步骤13)。
6:递归划分步骤仅当下列条件之一成立停止。
7:(a) 给定结点的所有样本属于同一类(步骤2 和3)。
8:(b) 没有剩余属性可以用来进一步划分样本(步骤4)。在此情况下,使用多数表决(步骤5)。
9:这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结点样本的类分布。
10:(c) 分枝
11:test_attribute = a i 没有样本(步骤11)。在这种情况下,以 samples 中的多数类:
12:创建一个树叶(步骤12)
其他算法:C4.5算法:

Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)
它们的共同点都是贪心算法,自上而下,区别是:度量方法不同,C4.5为gain ratio;CART为gini index;ID3为Information Gain。
决策树有时候也需要剪枝是为了避免过度拟合(Overfitting)。
剪枝有两种方法1:先剪枝:在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造;
2:后剪枝:先构造成完整的决策树,在通过某些特定的条件遍历决策树进行剪枝。
有时候在决策树构造的过程中可能会出现这种情况:所有属性都作为分裂属性用光了,但有的子集还不是纯净集,即集合内的元素不属于同一类别。在这种情况下,由于没有更多的信息可以使用了,一般对这些子集进行“多数表决”,即使用子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
决策树的优点:直观,便于理解,小规模数据集有效。缺点:处理连续型变量不好,类别较多时,错误增加的比较快,可规模性一般。
但是决策树(分类树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称为监督学习。
决策树(DT)是用于分类和回归的非参数监督学习方法。目标是创建一个模型,通过学习从数据特征推断的简单决策规则来预测目标变量的值。
这就是机器学习中的决策树(Decision Tree)DT
最后
以上就是魔幻万宝路最近收集整理的关于机器学习(三)决策树算法Decision Tree的全部内容,更多相关机器学习(三)决策树算法Decision内容请搜索靠谱客的其他文章。








发表评论 取消回复