之前花了半个小时做了个DataCastle上的基础竞赛题,然后提交结果后直接第六名,因此来分享一下。该文章之前记录在我的公众号上,原文链接:https://mp.weixin.qq.com/s/nIJ2begF2_5i_WnT1PEM3w
数据主要包括IMDB网站上的电影评论文本数据。 数据分为训练数据和测试数据,分别保存在train.csv和test_noLabel.csv两个文件中。 字段说明如下: (1)ID:编号 (2)TXT:电影评论文本 (3)Label:评论的情感类别,1表示积极,0表示消极。 注:比赛所用到的数据来自于公开数据集Large Movie Review Dataset。
首先导入相关的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score
导入文件并查看:
train = pd.read_csv('train.csv')
test = pd.read_csv('test_noLabel.csv')
train.head()

查看数据分布:
train.Label.value_counts()
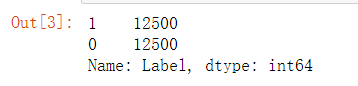
正例和负例各12500个,分布非常均匀。
合并训练集和测试集数据,便于统一处理:
full = pd.concat([train, test], sort=False)
将文本转换为tfidf的词向量:
tfidf = TfidfVectorizer()
x_full = tfidf.fit_transform(full.txt)
再将训练数据和测试数据拆分开来:
x_train, x_test = x_full[:25000], x_full[25000:]
提取训练集标签:
y_train = train.Label
创建模型并训练(这里取了20000条数据训练,5000条数据验证):
lg = LogisticRegression(C=1.0, fit_intercept=True, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001)
lg.fit(x_train[:20000], y_train[:20000])
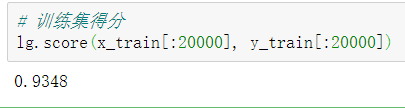
查看训练集得分:
lg.score(x_train[:20000], y_train[:20000])
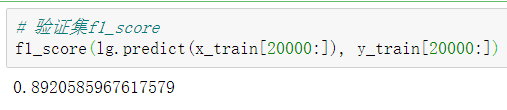
查看验证集f1_score:
f1_score(lg.predict(x_train[20000:]), y_train[20000:])
对测试集进行预测:
y_test = lg.predict(x_test)
test['Label'] = y_test
将预测结果保存成csv文件:
test.drop('txt', axis=1).to_csv('lg_test.csv', encoding='utf-8', index=False)
提交数据,查看结果:
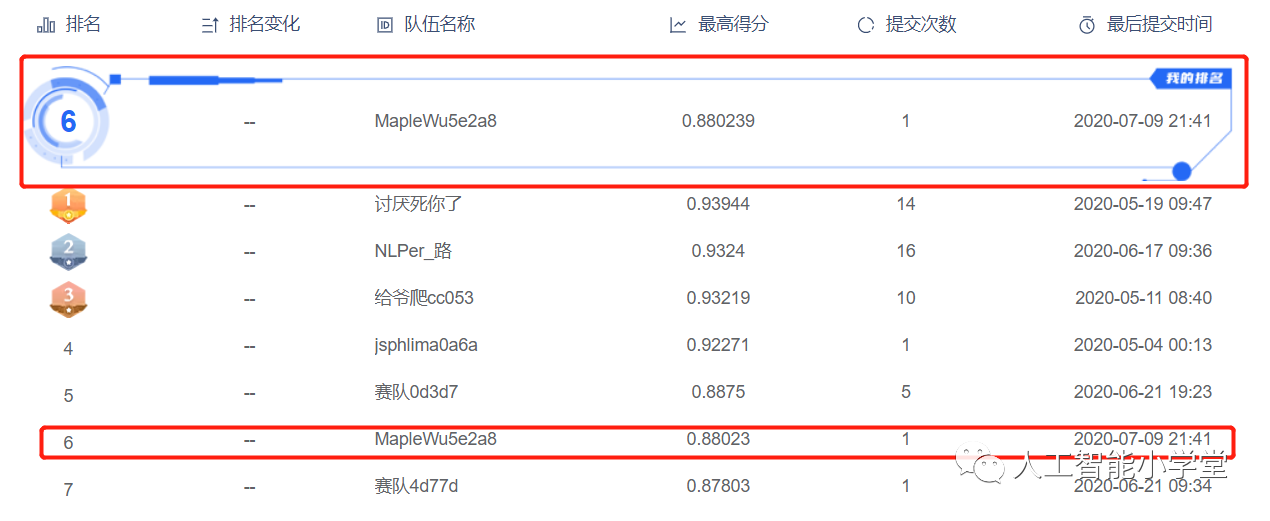
得分0.880239,排名第6。
竞赛地址:https://www.dcjingsai.com/v2/cmptDetail.html?id=359
最后
以上就是任性香水最近收集整理的关于文本情感分析竞赛(首次提交排名第6)的全部内容,更多相关文本情感分析竞赛(首次提交排名第6)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复