本文转自公众号“纸鱼AI”,该公众号专注于AI竞赛与前沿研究。作者为中国科学技术大学的linhw。本文是刚刚结束的CCF BDCI的新闻情感分类的方案分享,代码已经开源,希望对NLP感兴趣的朋友带来帮助。
写在前面
本文将带来CCF BDCI新闻情感分类的题解报告,该方案在初赛A榜获得了4/2735,复赛成绩Top1%。希望可以给大家提供一些思路,互相交流学习。
比赛代码已经开源在https://github.com/linhaow/TextClassify
赛题说明
比赛的链接在这里:
https://www.datafountain.cn/competitions/350
比赛的内容是互联网的新闻情感分析。给定新闻标题和新闻的内容,然后需要我们设计一个方案对新闻的情感进行分类,判断新闻是消极的,积极的还是中立的。
训练数据集的字段如下:
id:新闻的唯一标识。
title:新闻的题目。
content:新闻的内容。
label:情感分类的标签。
数据分析
一个好的数据分析可以给比赛带来很大的提升。所以数据分析的过程不能忽视。对训练数据集分析后,可以发现训练集有如下一些特征。
(1)训练数据集中0标签的数据量比较少,只有几百。
(2)训练集中1和2的标签比较平衡,都是几千,相差不大。
(3)此外新闻的文章内容很长,很多有上千个字。
(4)相比于新闻内容,新闻标题较短,很少有上百字的标题。
针对上述特征,可以看出标签中存在一定的数据不均衡,此外如何处理过长的文章内容也是一个核心任务。对于常用的bert模型,只能接收512个token,所以需要一个能处理过千字的文章内容的方法。
baseline
我刚参加比赛的时候初赛已经过去了一段时间了,当时有一个郭大开源的baseline,我的baseline是基于这个开源baseline修改的。baseline的结构图如下:
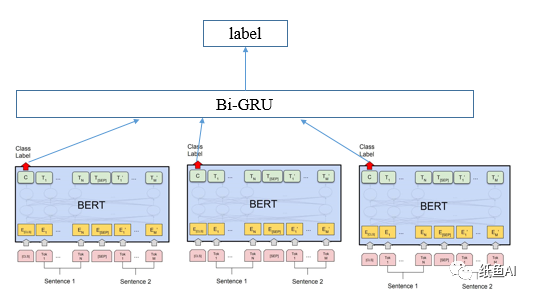
整个模型由两个部分组成。
(1)第一部分是最下方的split_num个bert模型(这里可以使用bert全家桶中的任意一个),现在基本文本分类比赛的前排都是bert模型。毕竟bert模型在预训练的时候就加入了很多比赛外的数据。所以相对来说效果也不会太差。
为了同时利用标题和文章内容信息,在bert模型的输入端。我选用了两个sentence加[SEP]做为模型的输入,其中sentence1是该新闻的标题,而sentence2则是该新闻的内容的一部分。为了让新闻内容可以覆盖到整篇文章,我首先将文章分成split_num段,然后在每一段选择maxlen的长度,分别做为split_num个bert模型的sentence2的输入。
举个例子,如果下面的长方形代表的是一个文章的内容,而split_num是3,则三颗五角星的地方是三个bert的sentence2的输入。sentence1均是文章标题。

(2)第二部分是上方的biGRU模块。该模块将bert对文章理解的不同部分串起来,最后给出综合考虑的分类输出。在这种RNN结构中,双向的效果往往比单向更好,所以使用了双向的GRU。
上述结构有如下的优点:
(1)减少了显存的使用,经过split后你可以在同样显存下处理更长的长度。
(2)另一个就是解决了长度上千的句子塞进bert的问题。上文bert模型处我使用的是中文的roberta-large模型。
提升模型
使用完上述baseline,并且调参后成绩就可以达到100名左右了。接下来就是如何提升模型的效果了。
(1)首先我发现郭大最初的代码好像有bug,当gru的层数大于1的时候维度不对。于是我查看源代码后把它fix了,然后在gru中加了几层layers,调整参数后,名次就到了前50了,大概线上是81.6左右。
具体的代码在pytorch_transformers文件夹中的modeling_bert.py第976行,修改后的代码如下:
self.gru.append(nn.GRU(config.hidden_sizeif i==0else config.lstm_hidden_size*2, config.lstm_hidden_size,num_layers=1,bidirectional=True,batch_first=True).cuda() )
最后
以上就是和谐钢笔最近收集整理的关于lstm训练情感分析的优点_CCF BDCI新闻情感分类初赛A榜4/2735,复赛Top1%题解报告的全部内容,更多相关lstm训练情感分析的优点_CCF内容请搜索靠谱客的其他文章。








发表评论 取消回复