本文为 AI 研习社编译的技术博客,原标题 :
Generative models: finding the object position by a single image
作者 | Ian Tsybulkin
翻译 | 小Y的彩笔
校对 | 邓普斯•杰弗 审核 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/@iantsybulkin/generative-models-finding-the-object-position-by-a-single-image-cc36b160a428
机器人技术和自动驾驶的兴起驱使人们需要更好的机器视觉。有许多不同的方法可以帮助机器人来给自己定位,导航,防止碰撞等等。这其中的一些方法要求非常复杂的 AI 算法,巨大的训练数据集,和昂贵的硬件。在这篇文章中,我们将展示一个相对简单和强大的算法,既不要求初步训练也不需要强大的硬件来运行。你只需要知道机器人预计要检测出哪种物体。这个算法仅花费很小的计算能力就可以以很棒的准确率检测到目标的位置。
工业上的应用
更具体的,让我们假设有一个传送带在传送不同尺寸的盒子,一个机器人需要将他们堆到不同大小的托盘上。为了实现这个,机器人需要检测盒子的类型和它的位置。盒子的位置可以用(x, y)坐标和盒子一条边和x轴形成的夹角来定义,比如,盒子沿传送带排列。机器人只有固定在传送带上的相机。

相机的启动
我们将会生成许多虚拟的图像,对应传送带上盒子的不同位置。由于这个原因,我们需要知道相机的坐标,和它相对于参考框架的角度,这些参考框架是与传送带相关的,我们称之为全局参考框架。
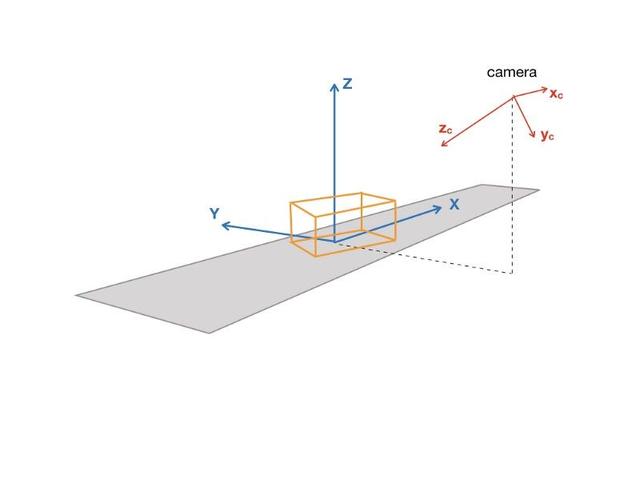
相机的启动
知道相机得坐标系和它的角度,我们可以找到相机的外部矩阵,而相机的外部矩阵是由它的特征确定的,比如焦距和像素数。外部矩阵可以轻易的通过一个标准的相机校准流程得到。
所以将任意在全局参考框架中的 3D 向量转化为一个图像像素的矩阵,可以用内部矩阵和外部矩阵的乘积得到,我们把它记作 M。
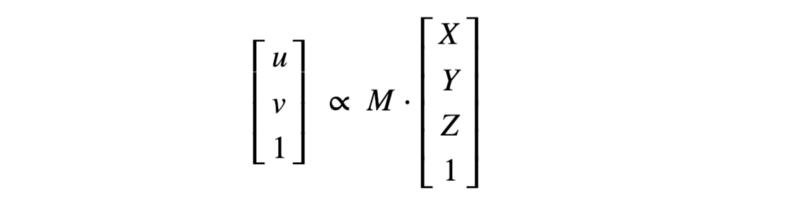
那么,我们找到了一个由相机矩阵定义的 2D 或 3D 的转换,它允许我们生成不同状态下盒子的虚拟图像。
生成图像
如果可以将任意的 3D 向量转换成图像,如果有盒子的 {x, y} 位置,角度 α 和维度 {W x D x H},我们就能生成图像来表示在相机眼中盒子是什么样的。也就是说对于任何状态的盒子 {x, y, α, t},我们可以构建一个虚拟图像来表示在相机眼中类型 t,位置在 {x, y},角度为 α 的盒子的样子。
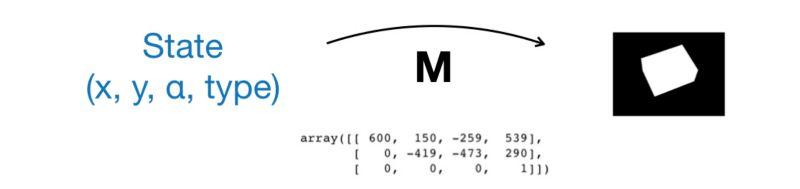
现在让我们定义一个函数,来展示虚拟图像和盒子的“真实图像”有多相似。如果虚拟图片与真实图片非常相似,我们可能会希望我们的虚拟盒子 {x, y, α,t} 距离盒子 {x, y, α} 的位置是非常近的,并且盒子有由类型 t 确定的维度。
损失函数
一个好的测量两个二进制图像之间相似的的方法是将不匹配的像素加起来。

例如,在这幅图中,有大概 20,000 个像素不匹配,用黄色标出。
生成的算法
现在让我们看一下生成的过程,它帮我们最小化损失函数,并且将状态终止在生成图片与从相机得到的盒子的真实图片最相似的地方。
我们将从随机选择 {x, y, α, t} 的状态开始。用相机转换矩阵,我们可以得到一个图像,并计算损失函数 L。这是马尔科夫链的初始状态,它将随机转换到下一状态,相应的对应到下面的步骤:
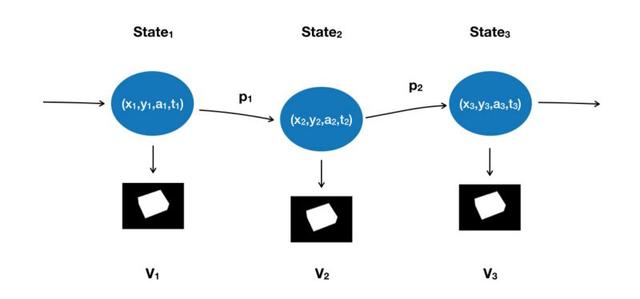
在每个状态我们随机生成一个接近当前状态的候选状态 (candidate state),这个候选状态可以通过下面的式子得到:
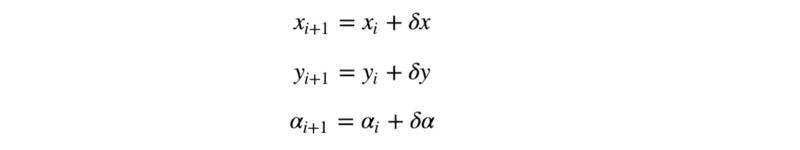
其中 δx, δy, δα 是零均值的正态分布的随机变量。
当 t 是一个类别变量时,我们可能对应下面的规则改变它:
变换可能性
现在让我们假设我们在状态 Si,候选状态是 Si+1。
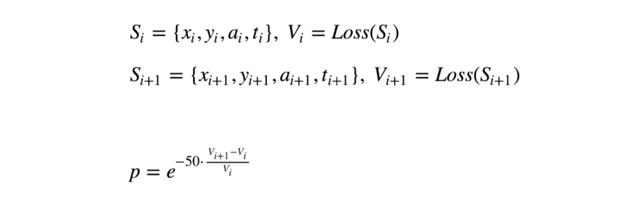
如果在候选状态的损失函数小于或等于当前状态的值,我们就认为到候选状态的概率为1,否则,转换的概率有上面的公式来定义。很容易注意到候选状态越糟糕(损失值越高),转换到该状态的概率越小。
然而,比如说,如果在候选状态的损失值只比当前状态的值高2%,转换到候选状态的概率会是 37%,这说明转换是很有可能发生的。
这个转换到有更高损失状态的随机性将帮助我们避开局部最小值,最终到达一个损失函数的全局最小值。
仿真
让我们来设置盒子的“真实位置”的隐藏值,并生成一个“真实相机镜头”。
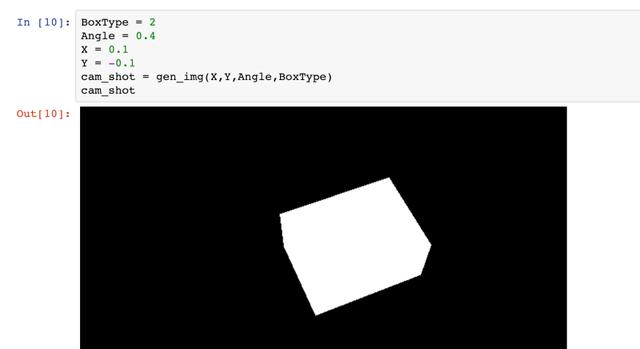
现在,我们运行一千次迭代,也就是说我们将会尝试改变初始随即状态一千次。从下面的图你可以看到损失函数在这个过程中是如何变化的:
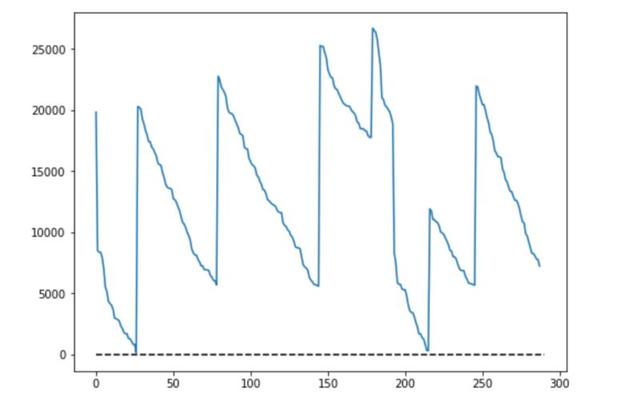
如你所见,我们的生成过程有大约 300 个状态,这意味着只有三分之一的状态可以转换到候选状态。除此之外,你可能会看到算法自动地终止并重启了6次,因为转到的状态很难再有提升。
你可能看到只用了25步就找到了全局最小值。之后的三次都是得到的局部最小值。很有趣的是所有的镜头都可以并行地运行。
准确率
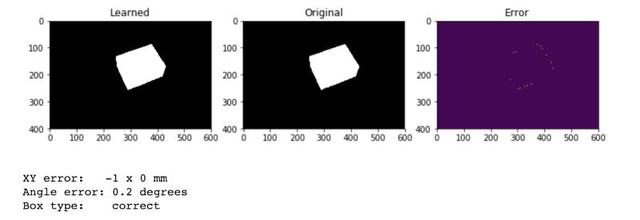
最令人印象深刻的部分是我们得到的准确率,如你所见,盒子位置的误差小于 1mm 并且角度误差仅仅为 0.2 度!
总结
有时反向解决问题是一个很好的方法。如例子中所示,如果找到什么样的输入可以产生给定的输出是很容易的且计算成本很低,那么你可以构建一个生成的过程,来猜测并改进初始猜测转换到下一个随即状态。
你可以在这里找到完整的代码:
https://github.com/tsybulkin/box-detect/blob/master/box-detect.ipynb
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【生成模型:基于单张图片找到物体位置】:
https://ai.yanxishe.com/page/TextTranslation/1452
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网雷锋网雷锋网
盘点图像分类的窍门
深度学习目标检测算法综述
生成模型:基于单张图片找到物体位置
AutoML :无人驾驶机器学习模型设计自动化
等你来译:
如何在神经NLP处理中引用语义结构
你睡着了吗?不如起来给你的睡眠分个类吧!
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体
最后
以上就是健忘大侠最近收集整理的关于图片维度不匹配_生成模型:基于单张图片找到物体位置的全部内容,更多相关图片维度不匹配_生成模型内容请搜索靠谱客的其他文章。








发表评论 取消回复