应用
- Answer Selection:给定一个问题,从候选答案集合中匹配最佳答案。
- Paraphrase Identification释义识别:给定两个句子,判断它们是否包含相同的语义。
- Textual entailment:给定一句话作为前提,另一句话作为推断,去判断能否根据前提得到推断。
评估
MAP,MRR评估方法
思路
representation learning的深度匹配模型,两个文本进行represent,之后进行交互,优点是快捷,便于进行无监督训练(大量无标注数据上进行表示学习)
match function learning不直接学习query和doc的表示,而是一开始就让query和doc进行各种交互,通过两者交互的match signals进行特征提取,然后通过aggregation对提取到的match signals用各种网络结构进行学习得到最终的匹配分数。
MatchPyramid模型
灵感来源于CV,把word-level的匹配情况看作是一张图片,用卷积来进行处理
word-level的匹配图示,显然word-level能很好的体现细粒度的匹配信息。

模型的整体架构,word-level的匹配信息可以看做图像的像素,第一层卷积学到的是n-gram匹配信息(s0和s1连续k个词的组合),后面的卷积是将n-gram匹配进行组合
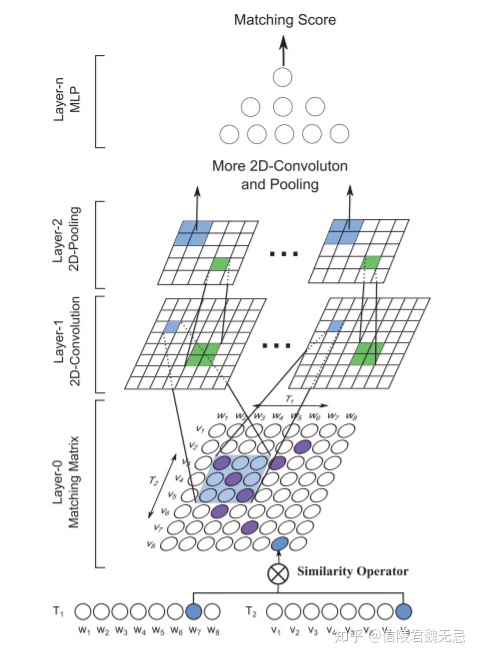
特点
(1) 比起ARC-II模型通过n-gram得到的word embedding进行相似度计算,MatchPyramid模型在匹配矩阵的计算上做得更加精细,关注的是原始word级别的交互
(2) 对于query和doc之间每个word的两两交互提出了3中方法,包括精确匹配的indicator计算,两个word完全相同为1否则为0;以及语法相似度的匹配,包括cosine以及dot product,关注的是更泛化的匹配
(3) 整个过程和图像识别以及人类的认知一样,word-level的匹配信号,类比图像中的像素特征;phrase-level的匹配信号,包括n-gram有序的phrase以及n-term无序的phrase,类比图像中的边缘检测;到sentence-level的匹配信号,类比图像中的motifs检测。
Match SRNN(IJCAI 2016)
特点是用了二维RNN对匹配矩阵进行建模,类似于最长公共子序列的模式。似于一种动态规划的思路,query和doc的交互矩阵中每个位置的值由不仅由当前两个word的交互值得到,还由其前面(左、上、以及左上三个位置)的值决定。
ABCNN(Attention-based CNN) TACL 2016
1、Basic CNN
宽卷积+窗口为w的pooling,这样句子的长度跟原来一样,理论上可以堆叠多次,最后进行全局pooling
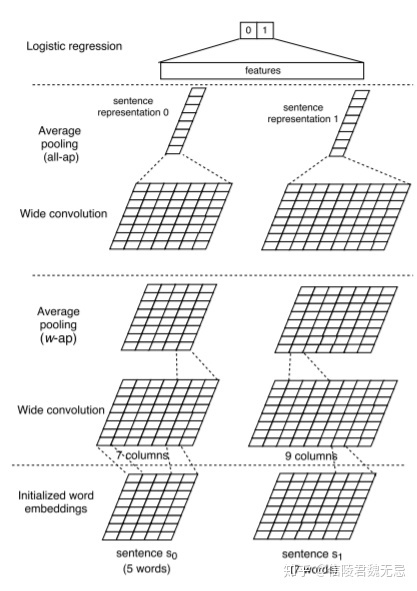
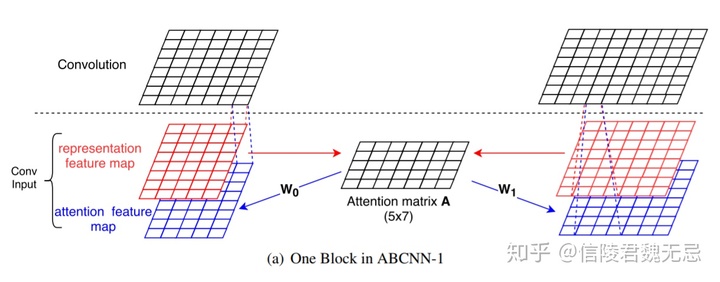
2、ABCNN 1
在卷积之前计算attention,通过红色的representation map(word embedding),进行attention得到attention matrix,attention matrix表示feature map 0的i位置和feature map 1的j位置的相关性。
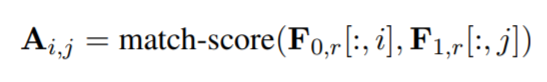
这里的match score用的是
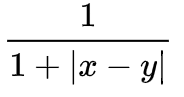
经过转换之后可以得到attention feature map
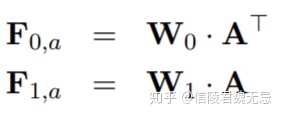
通过W0和W1两个矩阵将其转化为attention feature map
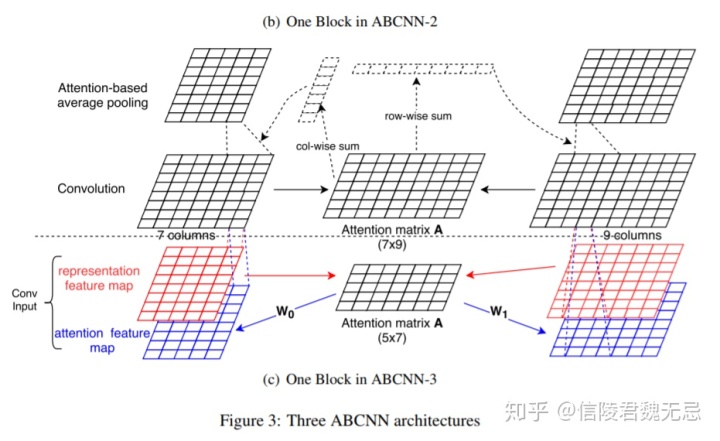
3、ABCNN-2
卷积之后进行attention计算,同样得到attention matrix,通过column-wise和row-wise的sum得到s0和s1中每个词的重要性,从而进行attention pooling,attention pooling就是让attention score序列乘以句子的representation最后进行池化,相对于平均池化来说每个词都包含了一个权重。但是这里的池化不是全局的,而是窗口为w的池化。
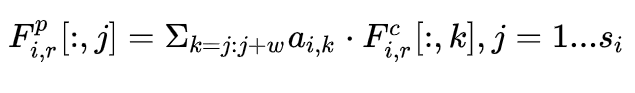
ESIM
Enhanced LSTM for Natural Language Inference
ESIM主要分为三部分:input encoding,local inference modeling 和 inference composition。
input encoding就是用word embedding + bilstm
local inference就是用一种交互式的attention架构,得到局部的交互信息。需要计算一个attention matrix(要分别根据两个句子的mask生成),然后生成align(也就是a每个位置分别跟b哪个位置align,b每个位置分别跟a哪个位置align),具体:
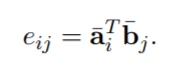
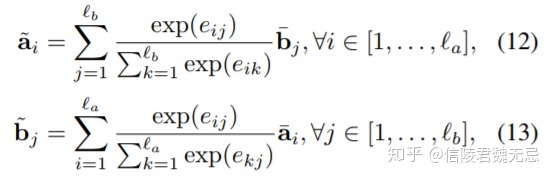
生成align之后,还需要有一部enhancement,进行element-wise的相乘和相减操作,并且与之前的拼接起来,作者希望这样能sharpen local inference information。
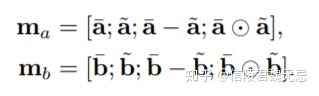
inference composition就是组合local inference交互之后的信息,用LSTM+池化得到全局的交互信息,这是输出层了,具体是把a和b的representation用avg/max pooling得到四个向量拼接起来。
BIMPM
Bilateral Multi-Perspective Matching双向多角度匹配模型
不仅需要考虑query到doc,也应该考虑从doc到query的倒推关系,因此这是个双边(Bilateral)的关系。
四个层,重点是matching layer
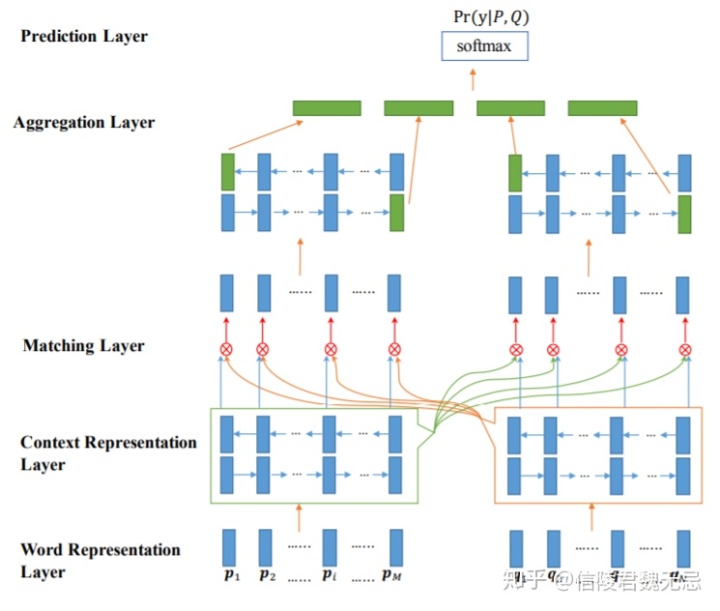
matching layer
这里分前向和后向分别计算match representation,match operation是多角度的。原来计算match score输入两个向量,输出一个值,现在输入两个向量,输出一个match向量,其中match向量每一个维度代表一个角度的匹配。
W代表一个l*d的向量,l代表视角数量
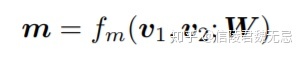
第k个视角对应一个相似度,用第k个视角的Wk作用在v1和v2上面得到,因此控制d维度空间不同dimension的权重。因此不同视角的Wk,本质是对于不同维度的取舍权重不同。
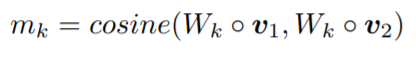
matching strategy
a. 以第一个句子P为例,如图a中左边的橙色条框,对于P中的每个前向单词hp_i(对于后向单词则为hp_1),都和Q中所有N个隐层的最后一个隐层输出hq_N(对于后向则为hq_1)进行匹配,通过fm网络拟合得到前向和后向两个维度为l的向量mi_full。如图a中a最右侧的蓝色条框为前向最后一个隐层的输出
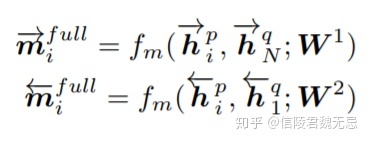
full-matching方法在计算当前匹配的时候,只用到后向LSTM隐层中的最后一个隐层以及前向LSTM隐层中的第一个隐层,中间的隐层信息并未利用。
b. max-pooling matching
对于P中的每个前向单词hp_i,如图b中最左边的橙色条框,都和Q中所有N个隐层输出一一计算,每个向量对通过fm映射后可以得到N个l维度的匹配向量后,对这N个匹配向量进行element-wise 的最大值,也就是在l个维度中的每个维度,从N个向量当前这个维度选择最大值,相当于是对N个隐层的max-pooling操作,最终得到前向和后向两个维度为l的向量mimax。
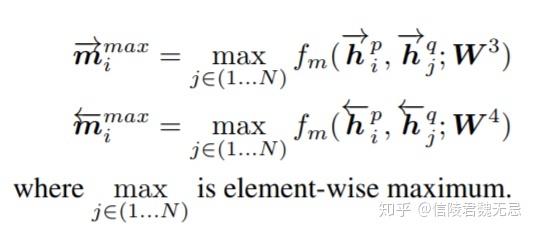
c.Attentive-Matching
用ESIM的方式得到交互align向量,然后计算原来vector和align vector的match。
类似于ESIM的align,不过这里是进行了前向和后向的计算
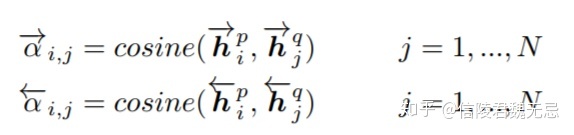

然后,计算align之后的match,这一步很像是ESIM的element-wise的相减和相乘,不过这里进行了复杂的多角度match
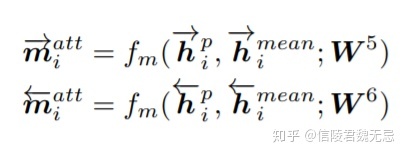
d.Max-Attentive-Matching
计算align的那一步,只需要选择M*N的attention matrix里面行(对应sent0)最大的和列(sent1)最大的就OK
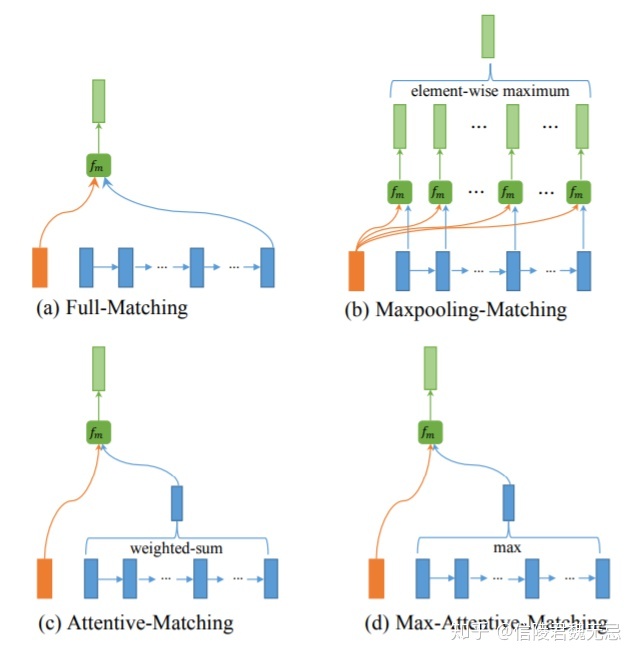
以上4种不同的匹配策略捕捉到的信息各自不同,在论文中为了提升模型拟合精度,在实际应用中是4种attention策略的叠加,每个策略中每个word得到一个l维的向量,最终得到4个匹配向量concat起来
对于句子P,得到一个M*4l的矩阵(M个time-step,每个time-step是一个4*l维度的向量),对于句子Q,得到一个N*4l的矩阵(N个time-step,每个time-step是一个4*l维度的向量)。
MIX KDD2018腾讯
Multi-Channel Information Crossing for Text Matching,原文聚焦于短文本匹配。短文本最大的特点是词数有限,更为灵活。这对于传统的基于规则的方法并不适用。
整体架构
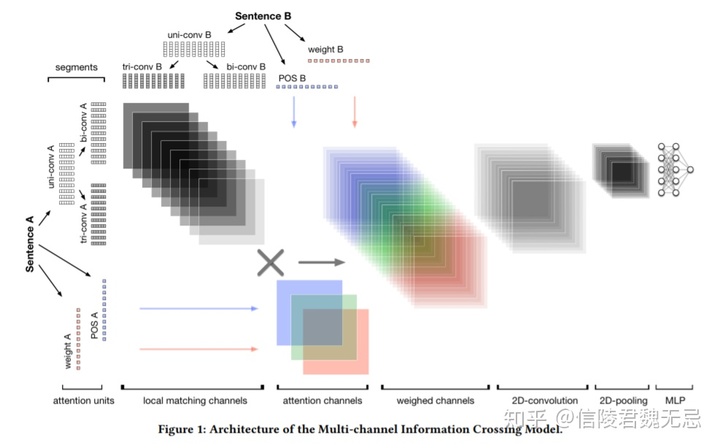
MIX利用不同窗长的CNN捕捉不同粒度的信息,也即N-gram。然后这些N-gram的信息交叉匹配形成多通道交叉信息,接着设计精细化的注意矩阵交叉将丰富的句子结构暴露给深度神经网络用于提取关键匹配信息。
最后通过CNN来聚合这些匹配信息再经过MLP得到匹配分数。原文的多通道交叉匹配是比较重要的创新点,不同粒度之间的匹配可以交叉并且真实work,启发后续多篇论文。最后实验是基于微软WikiQA数据集和QQ移动浏览器查询文档对数据集的offine测试。
作者提出了三个问题
1、如下图,当只使用word embdding时,三个短语对之间的匹配结果,”place of interest”和”senic spot”意思相同但是匹配分数很低,相反”in all”和”all in”两个意思相去甚远,但是匹配分数很高。
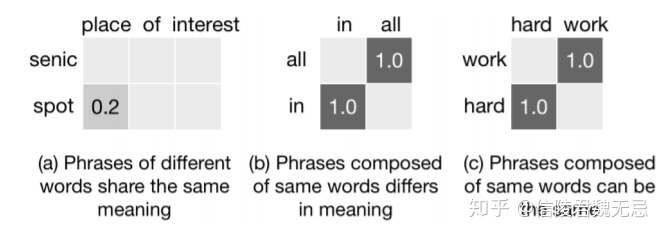
这说明单纯基于嵌入向量的文本匹配在很大程度上是无效的。换句话说,仅从一个角度进行文本匹配不能产生令人满意的结果。我们希望的是文本匹配要考虑匹配词在上下文中的词义变化,也就是在不同短语结构中的变化。原文提出的方法就是将词语放于不同粒度的短语中,也就是应用不同窗口的卷积中。
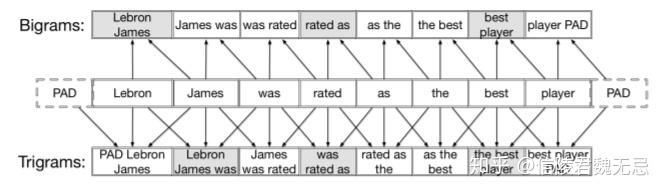
原文采用的窗口是{1,2,3},即unigram、bigrams、trigrams–也是考虑到在英文中,一个最小的语义单位通常包含1到3个单词。这样短文本对各自拥有三个粒度的信息,然后两个短语对的不同粒度交叉匹配,形成交叉匹配矩阵,原文也称为局部匹配。这样的做法使得MIX可以通过文本片段(可以是单词、术语或短语)确定最合适的语义表示,从而提高了局部匹配的准确性,目标是在不同层次的交互中捕获最多的信息。
2、Question-Answer中的问题,问题是”What year did Lebron James win his frst MVP”,错误答案”Steve Curry won his frst MVP in 2014”从匹配矩阵上看起来更像是该问题的答案,因为它的匹配度是被很多无关紧要的高局部匹配词如”his-his, frst-frst, year-2014”影响如上图的(a)。原文作者认为交互矩阵中不同项的权重应反映出每个匹配信号的重要性。换句话说,在考虑两个句子时,两个关键短语的匹配比两个琐碎短语的匹配更有意义。
在原匹配矩阵上覆盖注意力权重Masking,这个Masking的初始值用逆文档频率IDF来初始化,这样处理后的结果就如上图(b)和(c)。另外,这个IDF Mask(也就是Weight Mask)是可训练的–IDF值是初始化。
3、一般来说词性(词性)特征也是衡量术语交互重要性的好方法。例如,两个命名实体(比如两个人名)之间的匹配总是比普通名词和形容词之间的匹配更重要。理想地是在训练数据丰富、模型通用性强的情况下,该特征可以在训练过程中自动学习。然而,在实际应用中我们通常只有有限的训练数据,这些数据可能会也可能不会捕捉到POS特性的强大影响,因此引入一些与有用的POS匹配相关的先验知识是非常必要的。
原文作者从两段文本中提取POS标签,并用上图图(b)中的POS标签交互初始化这个POS Mask。我们可以看到,POS标签的交互显示出更高的重要性:两个人标签之间的交互,两个人标签之间的交互动词(VB),与时间有关的wh - pr名词(WP_time)与基数(CD)之间的相互作用。将POStag注意通道应用于上图(a)后,上图(c)强调了关键的局部匹配信号。另外,原文实验中作者对匹配句子进行了NER–为了进一步丰富POS tag信息。POS和NER标记是使用自然语言工具包(NLTK)提取的
总结:首先两个文本A、B,分别使用卷积核大小是{1,2,3}的CNN提取多粒度信息,然后多粒度信息交叉匹配。接着原文设计的三个注意力Mask矩阵—Weight Mask(IDF Mask)、POS Mask、Spatial Mask分别作用于这些交叉匹配矩阵上,结果拼接在一起,后续经过CNN聚合、Pooling,最后经过MLP得到匹配分数。
最后
以上就是尊敬仙人掌最近收集整理的关于图片维度不匹配_文本匹配入门总结的全部内容,更多相关图片维度不匹配_文本匹配入门总结内容请搜索靠谱客的其他文章。








发表评论 取消回复