- 下载地址:
https://flume.apache.org/download.html
- 上传至目标服务器

- 解压
[root@hadoop01 wyh]# tar -zxvf apache-flume-1.8.0-bin.tar.gz
- 配置环境变量
[root@hadoop01 wyh]# vi /etc/profile
#添加环境变量
FLUME_HOME=/usr/local/wyh/apache-flume-1.8.0-bin
PATH=$PATH:$FLUME_HOME/bin
export FLUME_HOME PATH
#使配置生效
[root@hadoop01 wyh]# source /etc/profile
- 验证flume是否安装成功
[root@hadoop01 wyh]# flume-ng version

- 修改flume配置文件
[root@hadoop01 conf]# pwd
/usr/local/wyh/apache-flume-1.8.0-bin/conf
[root@hadoop01 conf]# vi flume-env.sh
#添加JAVA_HOME
export JAVA_HOME=/usr/local/wyh/java/jdk1.8.0_311
案例实现
- 创建目录用来存放测试使用的conf
[root@hadoop01 apache-flume-1.8.0-bin]# pwd
/usr/local/wyh/apache-flume-1.8.0-bin
[root@hadoop01 apache-flume-1.8.0-bin]# mkdir test_conf
- 创建conf文件
[root@hadoop01 test_conf]# vi test-avro-logger.conf
[root@hadoop01 test_conf]# cat test-avro-logger.conf
#定义flume中的三大组件
myagent.sources=mysource1
myagent.channels=mychannel1
myagent.sinks=mysink1
#source-channel-sink之间组件
myagent.sources.mysource1.channels=mychannel1
#注意一个sink只能来源于一个channel,所以这里属性名中的channel是不加s的
myagent.sinks.mysink1.channel=mychannel1
#定义source的属性
myagent.sources.mysource1.type=avro
myagent.sources.mysource1.bind=hadoop01
#端口号自定义,但是要和后面使用该source的数据时使用的端口号保持一致
myagent.sources.mysource1.port=8888
#定义channel的属性
myagent.channels.mychannel1.type=memory
#定义sink的属性
myagent.sinks.mysink1.type=logger
myagent.sinks.mysink1.maxBytesToLog=200
- 启动flume服务
[root@hadoop01 test_conf]# flume-ng agent -c /usr/local/wyh/apache-flume-1.8.0-bin/conf -f /usr/local/wyh/apache-flume-1.8.0-bin/test_conf/test-avro-logger.conf -n myagent -Dflume.root.logger=INFO,console
#-c后面的参数是flume自身的conf目录
#-f后面的参数是我们配置的要实现具体业务的conf文件
#-n后面的参数是我么要启动的flume agent的名字,这个名字是和-f指定的conf文件中定义的agent名字相同可以看到flume agent已经启动:

重新打开一个终端,做如下操作:
- 准备数据文件作为数据输入
[root@hadoop01 test_data]# pwd
/usr/local/wyh/test_data
[root@hadoop01 test_data]# cat test-flume.txt
hello flume~
- 向flume source发送数据
[root@hadoop01 test_data]# flume-ng avro-client -c /usr/local/wyh/apache-flume-1.8.0-bin/conf -H hadoop01 -p 8888 -F /usr/local/wyh/test_data/test-flume.txt
#-c后面的参数是flume自身的conf目录
#-H后面的参数是前面自定义的conf文件中source所在的机器名
#-p后面的参数是source所监听的端口号,在自定义的conf文件中指定
#-F后面的参数是要向source发送数据的文件回到刚才启动flume agent的终端,可以看到已经把刚才我们指定的数据文件中的数据读出来并打印在控制台了。
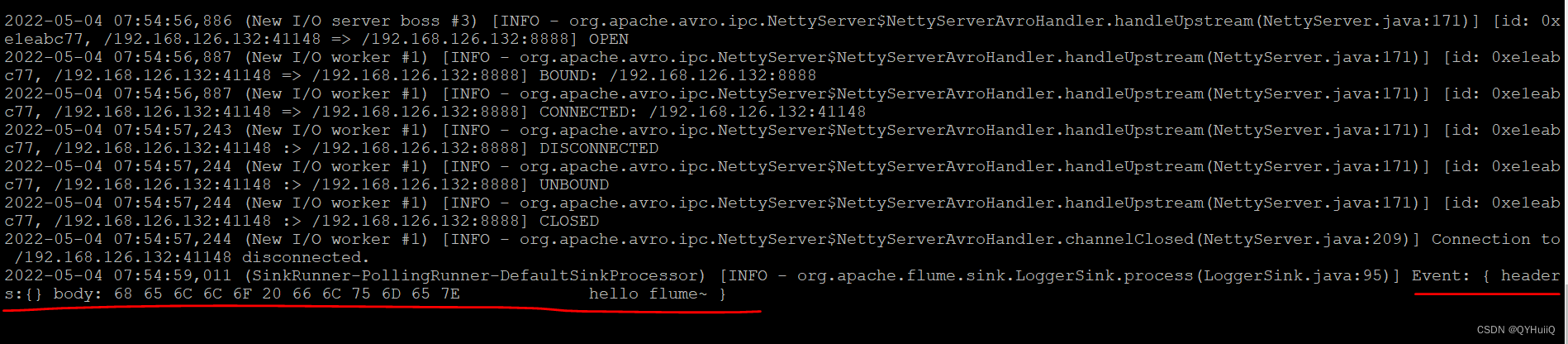
以上就是flume的安装以及使用案例的简单实现。
最后
以上就是标致胡萝卜最近收集整理的关于Flume的安装及基本使用的全部内容,更多相关Flume内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复