 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
大数据组件安装(非CDH)和使用 总文章
flume 的安装和部署(非CDH):
1.tar -zxvf apache-flume-1.6.0-bin.tar.gz
2.mv apache-flume-1.6.0-bin flume
3.cd /root/flume/conf
4.cp flume-env.sh.template flume-env.sh
5.which java
得出结果:/root/java/jdk1.8.0_45/bin/java
6.vim flume-env.sh 修改JAVA_HOME配置信息如下:
export JAVA_HOME=/root/java/jdk1.8.0_45
补充知识:0.0.0.0
IPV4中,0.0.0.0地址被用于表示一个无效的,未知的或者不可用的目标。
在服务器中,0.0.0.0指的是本机上的所有IPV4地址,如果一个主机有两个IP地址,192.168.1.1 和 10.1.2.1,
并且该主机上的一个服务监听的地址是0.0.0.0,那么通过两个ip地址都能够访问该服务。
在路由中,0.0.0.0表示的是默认路由,即当路由表中没有找到完全匹配的路由的时候所对应的路由。
==================Flume 安装部署1=================
配置案例1:
1.cd /root/flume/conf
2.vim netcat-logger.conf内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.启动flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令:bin/flume-ng agent --conf conf/ --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
-c conf/ 或 --conf conf/:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
-name agent的名字 或 -n agent的名字:指定我们这个agent 的名字
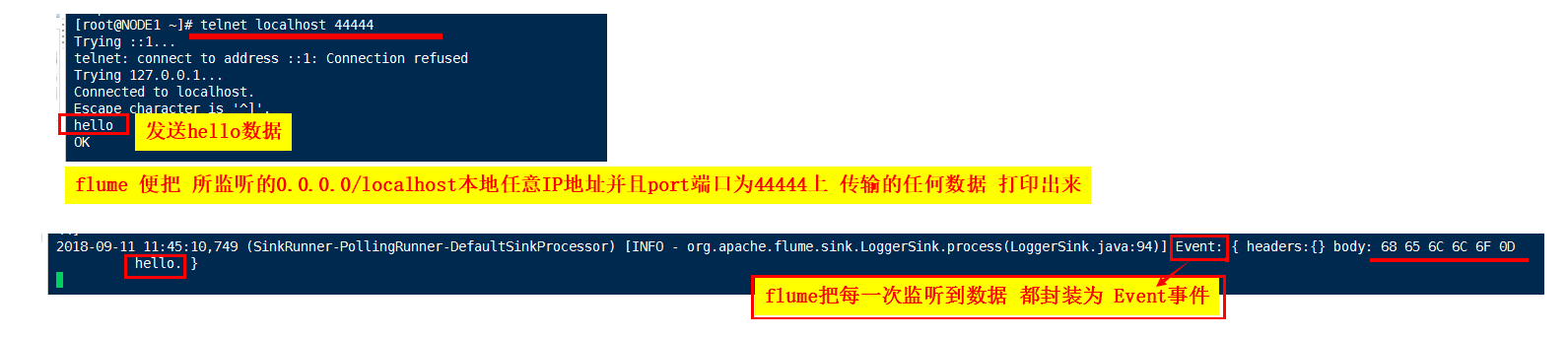
启动的最后会显示:Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
表示 flume负责监听 0.0.0.0/localhost本地任意IP地址并且port端口为44444上 传输的任何数据
4.注意:
此处之所以只执行“cd /root/flume”,而不是执行“cd /root/flume/bin”,是因为启动命令中要指定的是以当前路径为开始找配置文件,
比如 “--conf conf/” 表示以 “/root/flume”的当前路径找到“conf/”。
比如“--conf-file conf/netcat-logger.conf”表示以 “/root/flume”的当前路径找到“conf目录下的netcat-logger.conf”。
4.测试是否搭建成功:
1.yum install -y telnet
telnet:在网络上进行数据传输的模拟工具
2.telnet flume监听的地址 flume监听的端口
比如:此处执行的是 telnet localhost 44444
==================Flume 安装部署2=================
Flume 安装部署
1.上传安装包到数据源所在节点上,然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
2.然后进入 flume 的目录,修改 conf 下的 flume-env.sh,在里面配置 JAVA_HOME
3.根据数据采集需求配置采集方案,描述在配置文件中(文件名可任意自定义)
4.指定采集方案配置文件,在相应的节点上启动 flume agent
5.先用一个最简单的例子来测试一下程序环境是否正常
1.先在 flume 的 conf 目录下新建一个文件:vi netcat-logger.conf
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = logger
# 描述和配置 channels 组件c1,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000 # 容量/event的传输数量
a1.channels.c1.transactionCapacity = 100 # 事务的容量
# 描述和配置 source、channel、sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channels = c1
2.启动 agent 去采集数据
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
参数:
-c conf:指定 flume 自身的配置文件所在目录
-f conf/netcat-logger.conf:指定我们所描述的采集方案
-n a1:指定我们这个agent 的名字
3.测试
先要往 agent 采集监听的端口上发送数据,让 agent 有数据可采。
随便在一个能跟 agent 节点联网的机器上:telnet anget-hostname port (如:telnet localhost 44444)
最后
以上就是落后往事最近收集整理的关于flume 的安装和部署(非CDH)日萌社大数据组件安装(非CDH)和使用 总文章的全部内容,更多相关flume内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复