模型总览:
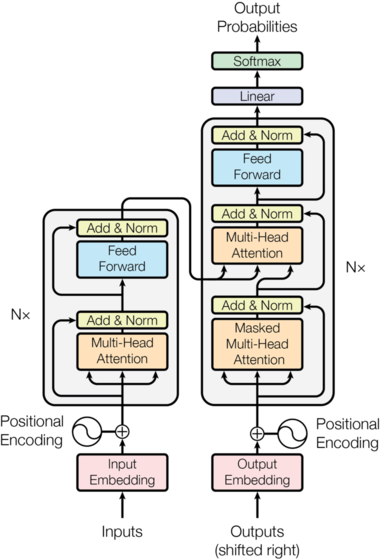
1.Transformer的结构是什么样的?
Transformer本身还是一个典型的encoder-decoder模型,如果从模型层面来看,Transformer实际上就像一个seq2seq with attention的模型,下面大概说明一下Transformer的结构以及各个模块的组成。
(1). Encoder端 & Decoder端总览
-
Encoder端由N(原论文中N=6)个相同的大模块堆叠而成,其中每个大模块又由两个子模块构成,这两个子模块分别为多头self-attention模块,以及一个前馈神经网络模块;
- 需要注意的是,Encoder端每个大模块接收的输入是不一样的,第一个大模块(最底下的那个)接收的输入是输入序列的embedding(embedding可以通过word2vec预训练得来),其余大模块接收的是其前一个大模块的输出,最后一个模块的输出作为整个Encoder端的输出。
-
Decoder端同样由N(原论文中N=6)个相同的大模块堆叠而成,其中每个大模块则由三个子模块构成,这三个子模块分别为多头self-attention模块,多头Encoder-Decoder attention交互模块,以及一个前馈神经网络模块;
- 同样需要注意的是,Decoder端每个大模块接收的输入也是不一样的,其中第一个大模块(最底下的那个)训练时和测试时的接收的输入是不一样的,并且每次训练时接收的输入也可能是不一样的(也就是模型总览图示中的"shifted right",后续会解释),其余大模块接收的是同样是其前一个大模块的输出,最后一个模块的输出作为整个Decoder端的输出。
- 对于第一个大模块,简而言之,其训练及测试时接收的输入为:
- 训练的时候每次的输入为上次的输入加上输入序列向后移一位的ground truth(例如每向后移一位就是一个新的单词,那么则加上其对应的embedding),特别地,当decoder的time step为1时(也就是第一次接收输入),其输入为一个特殊的token,可能是目标序列开始的token(如<BOS>),也可能是源序列结尾的token(如<EOS>),也可能是其它视任务而定的输入等等,不同源码中可能有微小的差异,其目标则是预测下一个位置的单词(token)是什么,对应到time step为1时,则是预测目标序列的第一个单词(token)是什么,以此类推;
- 这里需要注意的是,在实际实现中可能不会这样每次动态的输入,而是一次性把目标序列的embedding通通输入第一个大模块中,然后在多头attention模块对序列进行mask即可
- 而在测试的时候,是先生成第一个位置的输出,然后有了这个之后,第二次预测时,再将其加入输入序列,以此类推直至预测结束。
- 训练的时候每次的输入为上次的输入加上输入序列向后移一位的ground truth(例如每向后移一位就是一个新的单词,那么则加上其对应的embedding),特别地,当decoder的time step为1时(也就是第一次接收输入),其输入为一个特殊的token,可能是目标序列开始的token(如<BOS>),也可能是源序列结尾的token(如<EOS>),也可能是其它视任务而定的输入等等,不同源码中可能有微小的差异,其目标则是预测下一个位置的单词(token)是什么,对应到time step为1时,则是预测目标序列的第一个单词(token)是什么,以此类推;
(2).Encoder端各个子模块
多头self-attention模块
在介绍self-attention模块之前,先介绍self-attention模块,图示如下:
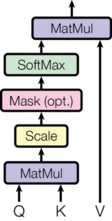
上述attention可以被描述为将query和key-value键值对的一组集合映射到输出,其中 query,keys,values和输出都是向量,其中 query和keys的维度均为
d
k
d_k
dk,values的维度为
d
v
d_v
dv(论文中
d
k
=
d
v
=
d
model
/
h
=
64
d_k=d_v=d_{text{model}}/h=64
dk=dv=dmodel/h=64),输出被计算为values的加权和,其中分配给每个value的权重由query与对应key的相似性函数计算得来。这种attention的形式被称为“Scaled Dot-Product Attention”,对应到公式的形式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
mathrm{Attention}(Q, K, V) = mathrm{softmax}(frac{QK^T}{sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
而多头self-attention模块,则是将
Q
,
K
,
V
Q,K,V
Q,K,V通过参数矩阵映射后(给
Q
,
K
,
V
Q,K,V
Q,K,V分别接一个全连接层),然后再做self-attention,将这个过程重复
h
h
h(原论文中
h
=
8
h=8
h=8)次,最后再将所有的结果拼接起来,再送入一个全连接层即可,图示如下:
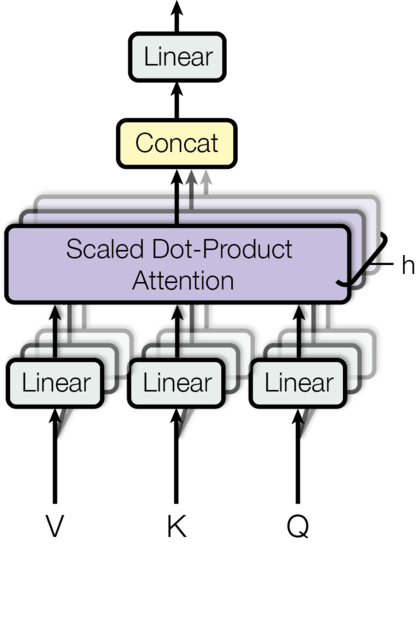
对应到公式的形式为:
MultiHead
(
Q
,
K
,
V
)
=
Concat (head
1
,
…
,
head
h
)
W
O
where head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
begin{aligned} text { MultiHead }(Q, K, V) &left.=text { Concat (head }_{1}, ldots, text { head }_{mathrm{h}}right) W^{O} \ text { where head }_{mathrm{i}} &=text { Attention }left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}right) end{aligned}
MultiHead (Q,K,V) where head i= Concat (head 1,…, head h)WO= Attention (QWiQ,KWiK,VWiV)
其中
W
i
Q
∈
R
d
m
o
d
e
l
×
d
k
,
W
i
K
∈
R
d
m
o
d
e
l
×
d
k
,
W
i
V
∈
R
d
m
o
d
e
l
×
d
v
,
W
O
∈
R
h
d
v
×
d
model
W_{i}^{Q} in mathbb{R}^{d_{mathrm{model}} times d_{k}}, W_{i}^{K} in mathbb{R}^{d_{mathrm{model}} times d_{k}}, W_{i}^{V} in mathbb{R}^{d_{mathrm{model}} times d_{v}}, W^{O} in mathbb{R}^{h d_{v} times d_{text {model }}}
WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,WO∈Rhdv×dmodel
前馈神经网络模块
前馈神经网络模块(即图示中的Feed Forward)由两个线性变换组成,中间有一个ReLU激活函数,对应到公式的形式为:
F
F
N
(
x
)
=
max
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
mathrm{FFN}(x)=max left(0, x W_{1}+b_{1}right) W_{2}+b_{2}
FFN(x)=max(0,xW1+b1)W2+b2
论文中前馈神经网络模块输入和输出的维度均为
d
model
=
512
d_{text {model}}=512
dmodel=512,其内层的维度
d
f
f
=
2048
d_{ff}=2048
dff=2048。
(3).Decoder端各个子模块
多头self-attention模块
Decoder端多头self-attention模块与Encoder端的一致,但是需要注意的是Decoder端的多头self-attention需要做mask,因为它在预测时,是“看不到未来的序列的”,所以要将当前预测的单词(token)及其之后的单词(token)全部mask掉。
多头Encoder-Decoder attention交互模块
多头Encoder-Decoder attention交互模块的形式与多头self-attention模块一致,唯一不同的是其 Q , K , V Q,K,V Q,K,V矩阵的来源,其 Q Q Q矩阵来源于下面子模块的输出(对应到图中即为masked多头self-attention模块经过Add & Norm后的输出),而** K , V K,V K,V矩阵则来源于整个Encoder端的输出**,仔细想想其实可以发现,这里的交互模块就跟seq2seq with attention中的机制一样,目的就在于让Decoder端的单词(token)给予Encoder端对应的单词(token)“更多的关注(attention weight)”
前馈神经网络模块
该部分与Encoder端的一致
(4).其他模块
Add & Norm模块
Add & Norm模块接在Encoder端和Decoder端每个子模块的后面,其中Add表示残差连接,Norm表示LayerNorm,残差连接来源于论文Deep Residual Learning for Image Recognition,LayerNorm来源于论文Layer Normalization,因此Encoder端和Decoder端每个子模块实际的输出为: L a y e r N o r m ( x + S u b l a y e r ( x ) ) mathrm{LayerNorm}(x + mathrm{Sublayer}(x)) LayerNorm(x+Sublayer(x)),其中 S u b l a y e r ( x ) ) mathrm{Sublayer}(x)) Sublayer(x))为子模块的输出。
Positional Encoding
Positional Encoding添加到Encoder端和Decoder端最底部的输入embedding。Positional Encoding具有与embedding相同的维度 d model d_{text{model}} dmodel,因此可以对两者进行求和。
具体做法是使用不同频率的正弦和余弦函数,公式如下:
P
E
(
p
o
s
,
2
i
)
=
sin
(
pos
/
1000
0
2
i
/
d
m
o
d
e
l
)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
pos
/
1000
0
2
i
/
d
m
o
d
e
l
)
begin{aligned} P E_{(p o s, 2 i)} &=sin left(operatorname{pos} / 10000^{2i / operatorname{d_{model}}}right) \ P E_{(p o s, 2 i+1)} &=cos left(operatorname{pos} / 10000^{2 i / d_{mathrm{model}}}right) end{aligned}
PE(pos,2i)PE(pos,2i+1)=sin(pos/100002i/dmodel)=cos(pos/100002i/dmodel)
其中
p
o
s
pos
pos为位置,
i
i
i为维度,之所以选择这个函数,是因为任意位置
P
E
p
o
s
+
k
PE_{pos+k}
PEpos+k可以表示为
P
E
p
o
s
PE_{pos}
PEpos的线性函数,这个主要是三角函数的特性:
sin
(
α
+
β
)
=
sin
(
α
)
cos
(
β
)
+
cos
(
α
)
sin
(
β
)
cos
(
α
+
β
)
=
cos
(
α
)
cos
(
β
)
−
sin
(
α
)
sin
(
β
)
begin{aligned} sin (alpha+beta) &=sin (alpha) cos (beta)+cos (alpha) sin (beta) \ cos (alpha+beta) &=cos (alpha) cos (beta)-sin (alpha) sin (beta) end{aligned}
sin(α+β)cos(α+β)=sin(α)cos(β)+cos(α)sin(β)=cos(α)cos(β)−sin(α)sin(β)
需要注意的是,Transformer中的Positional Encoding不是通过网络学习得来的,而是直接通过上述公式计算而来的,论文中也实验了利用网络学习Positional Encoding,发现结果与上述基本一致,但是论文中选择了正弦和余弦函数版本,因为三角公式不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。
2.Transformer Decoder端的输入具体是什么?
见上述Encoder端 & Decoder端总览中,对Decoder端的输入有详细的分析
3.Transformer中一直强调的self-attention是什么?self-attention的计算过程?为什么它能发挥如此大的作用?self-attention为什么要使用Q、K、V,仅仅使用Q、V/K、V或者V为什么不行?
**self-attention,**也叫 intra-attention,是一种通过自身和自身相关联的attention机制,从而得到一个更好的 representation 来表达自身,self-attention可以看成一般attention的一种特殊情况。在self-attention中, Q = K = V Q=K=V Q=K=V,序列中的每个单词(token)和该序列中其余单词(token)进行attention计算。self-attention的特点在于无视词(token)之间的距离直接计算依赖关系,从而能够学习到序列的内部结构,实现起来也比较简单,值得注意的是,在后续一些论文中,self-attention可以当成一个层和RNN,CNN等配合使用,并且成功应用到其他NLP任务。
关于self-attention的计算过程问题1中有详细的解答
关于self-attention为什么它能发挥如此大的作用,在上述self-attention的介绍中实际上也有所提及,self-attention是一种自身和自身相关联的attention机制,这样能够得到一个更好的 representation 来表达自身,在多数情况下,自然会对下游任务有一定的促进作用,但是Transformer效果显著及其强大的特征抽取能力是否完全归功于其self-attention模块,还是存在一定争议的,参见论文:How Much Attention Do You Need?A Granular Analysis of Neural Machine Translation Architectures,如下例子可以大概探知self-attention的效果:
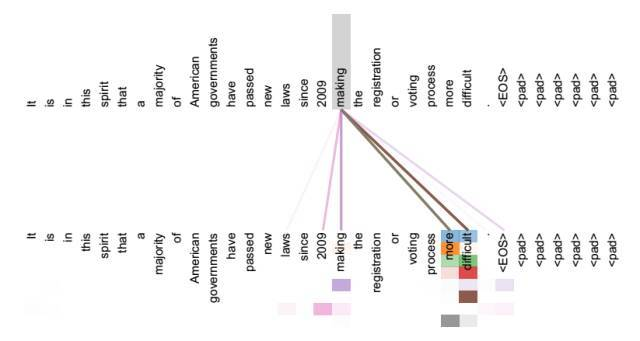
图1 可视化self-attention实例
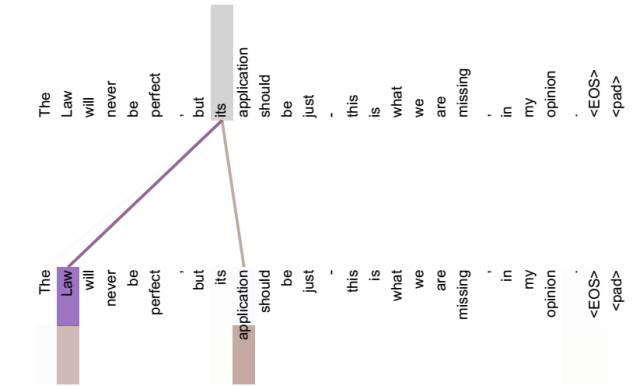
图2 可视化self-attention实例
从两张图(图1、图2)可以看出,self-attention可以捕获同一个句子中单词之间的一些句法特征(比如图1展示的有一定距离的短语结构)或者语义特征(比如图1展示的its的指代对象Law)。
很明显,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
关于self-attention为什么要使用Q、K、V,仅仅使用Q、V/K、V或者V为什么不行?
这个问题我觉得并不重要,self-attention使用Q、K、V,这样三个参数独立,模型的表达能力和灵活性显然会比只用Q、V或者只用V要好些,当然主流attention的做法还有很多种,比如说seq2seq with attention也就只有hidden state来做相似性的计算,处理不同的任务,attention的做法会有细微的不同,但是主体思想还是一致的,不知道有没有论文对这个问题有过细究,有空去查查~
其实还有个小细节,因为self-attention的范围是包括自身的(masked self-attention也是一样),因此至少是要采用Q、V或者K、V的形式,而这样“询问式”的attention方式,个人感觉Q、K、V显然合理一些。
4.Transformer为什么需要进行Multi-head Attention?这样做有什么好处?Multi-head Attention的计算过程?各方论文的观点是什么?
原论文中说到进行Multi-head Attention的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。其实直观上也可以想到,如果自己设计这样的一个模型,必然也不会只做一次attention,多次attention综合的结果至少能够起到增强模型的作用,也可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力**有助于网络捕捉到更丰富的特征/信息。**关于Multi-head Attention的计算过程在1中也有详细的介绍,但是需要注意的是,论文中并没有对Multi-head Attention有很强的理论说明,因此后续有不少论文对Multi-head Attention机制都有一定的讨论,一些相关工作的论文如下(还没看,先攒着):
Multi-head Attention机制相关的论文:
A Structured Self-attentive Sentence Embedding
对Multi-head Attention机制进行分析的论文:
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Are Sixteen Heads Really Better than One?
What Does BERT Look At? An Analysis of BERT’s Attention
A Multiscale Visualization of Attention in the Transformer Model
Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention
5.Transformer相比于RNN/LSTM,有什么优势?为什么?
(1).RNN系列的模型,并行计算能力很差
RNN系列的模型 T T T时刻隐层状态的计算,依赖两个输入,一个是 T T T时刻的句子输入单词 X t X_t Xt,另一个是 T − 1 T-1 T−1时刻的隐层状态 S t − 1 S_{t-1} St−1的输出,是最能体现RNN本质特征的一点,RNN的历史信息是通过这个信息传输渠道往后传输的。而RNN并行计算的问题就出在这里,因为 T T T时刻的计算依赖 T − 1 T-1 T−1时刻的隐层计算结果,而 T − 1 T-1 T−1时刻的计算依赖 T − 2 T-2 T−2时刻的隐层计算结果,如此下去就形成了所谓的序列依赖关系。
(2).Transformer的特征抽取能力比RNN系列的模型要好
上述结论是通过一些主流的实验来说明的,并不是严格的理论证明,具体实验对比可以参见:
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较
但是值得注意的是,并不是说Transformer就能够完全替代RNN系列的模型了,任何模型都有其适用范围,同样的,RNN系列模型在很多任务上还是首选,熟悉各种模型的内部原理,知其然且知其所以然,才能遇到新任务时,快速分析这时候该用什么样的模型,该怎么做好。
6.Transformer是如何训练的?测试阶段如何进行测试呢?
- Transformer训练过程与seq2seq类似,首先Encoder端得到输入的encoding表示,并将其输入到Decoder端做交互式attention,之后在Decoder端接收其相应的输入(见1中有详细分析),经过多头self-attention模块之后,结合Encoder端的输出,再经过FFN,得到Decoder端的输出之后,最后经过一个线性全连接层,就可以通过softmax来预测下一个单词(token),然后根据softmax多分类的损失函数,将loss反向传播即可,所以从整体上来说,Transformer训练过程就相当于一个有监督的多分类问题。
- 需要注意的是,Encoder端可以并行计算,一次性将输入序列全部encoding出来,但Decoder端不是一次性把所有单词(token)预测出来的,而是像seq2seq一样一个接着一个预测出来的。
而对于测试阶段,其与训练阶段唯一不同的是Decoder端最底层的输入,详细分析见问题1。
7.Transformer中的Add & Norm模块,具体是怎么做的?
见1其他模块的叙述,对Add & Norm模块有详细的分析
8.为什么说Transformer可以代替seq2seq?
这里用代替这个词略显不妥当,seq2seq虽已老,但始终还是有其用武之地,seq2seq最大的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失Encoder端的很多信息,而且这样一股脑的把该固定向量送入Decoder端,Decoder端不能够关注到其想要关注的信息。上述两点都是seq2seq模型的缺点,后续论文对这两点有所改进,如著名的Neural Machine Translation by Jointly Learning to Align and Translate,虽然确确实实对seq2seq模型有了实质性的改进,但是由于主体模型仍然为RNN(LSTM)系列的模型,因此模型的并行能力还是受限,而transformer不但对seq2seq模型这两点缺点有了实质性的改进(多头交互式attention模块),而且还引入了self-attention模块,让源序列和目标序列首先“自关联”起来,这样的话,源序列和目标序列自身的embedding表示所蕴含的信息更加丰富,而且后续的FFN层也增强了模型的表达能力(ACL 2018会议上有论文对Self-Attention和FFN等模块都有实验分析,见论文:How Much Attention Do You Need?A Granular Analysis of Neural Machine Translation Architectures),并且Transformer并行计算的能力是远远超过seq2seq系列的模型,因此我认为这是transformer由于seq2seq模型的地方。
9.Transformer中句子的encoder表示是什么?如何加入词序信息的?
Transformer Encoder端得到的是整个输入序列的encoding表示,其中最重要的是经过了self-attention模块,让输入序列的表达更加丰富,而加入词序信息是使用不同频率的正弦和余弦函数,具体见1中叙述。
10.Transformer如何并行化的?
Transformer的并行化我认为主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,在self-attention模块,对于某个序列 x 1 , x 2 , … , x n x_{1}, x_{2}, dots, x_{n} x1,x2,…,xn,self-attention模块可以直接计算 x i , x j x_{i}, x_{j} xi,xj的点乘结果,而RNN系列的模型就必须按照顺序从 x 1 x_{1} x1计算到 x n x_{n} xn。
11.self-attention公式中的归一化有什么作用?
首先说明做归一化的原因,随着 d k d_k dk的增大, q ⋅ k q cdot k q⋅k点积后的结果也随之增大,这样会将softmax函数推入梯度非常小的区域,使得收敛困难(可能出现梯度消失的情况)(为了说明点积变大的原因,假设 q q q和 k k k的分量是具有均值0和方差1的独立随机变量,那么它们的点积 q ⋅ k = ∑ i = 1 d k q i k i q cdot k=sum_{i=1}^{d_k} q_{i} k_{i} q⋅k=∑i=1dkqiki均值为0,方差为 d k d_k dk),因此为了抵消这种影响,我们将点积缩放 1 d k frac{1}{sqrt{d_{k}}} dk1,对于更详细的分析,参见(有空再来总结,哈哈~):transformer中的attention为什么scaled?
写在后面
17年提出的Transformer模型,在当时确实引起了很大的轰动,但是到现在事后看来,Transformer模型也确实能力很强,但是我觉得并不想论文题目说的那样《attention is all you need》,反而我觉得论文最大的贡献在于它第一次做到了在自然语言处理任务中把网络的深度堆叠上去还能取得很好的效果,而机器翻译恰好也是一个目前数据量非常丰富且问题本身难度不大的一个任务了,这样充分发挥了 Transformer 的优势。另外**self-attention 其实并不是 Transformer 的全部(是否self-attention的思想首次出现于该论文中也不得而知,Google也总是喜欢将以前没有明确定义的概念(但是做法已经很明显了),给出一个明确的定义或者做集大成者的工作,如bert!),实际上从深度 CNN 网络中借鉴而来的 FFN 可能更加重要。**所以,理智看待Transformer,面对不同的任务,选择最合适自己任务的模型就好了~
参考(下述参考可能没有展示完全,如果有疏漏,请联系我):
The Illustrated Transformer
The Annotated Transformer
BERT大火却不懂Transformer?读这一篇就够了(注意该博客为The Illustrated Transformer的中文翻译版本)
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较
为什么Transformer 需要进行 Multi-head Attention?
transformer中的attention为什么scaled?
【NLP】Transformer详解
transformer和LSTM对比的设想?
目前主流的attention方法都有哪些?
谷歌论文《Attention is all you need》里Transformer模型的一些疑问?
《Attention is All You Need》浅读(简介+代码)
最后
以上就是害羞白昼最近收集整理的关于关于Transformer的若干问题整理记录& 思考的全部内容,更多相关关于Transformer的若干问题整理记录&内容请搜索靠谱客的其他文章。





![[Android官方Demo系列] PageTransformer缩放](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)


发表评论 取消回复