Dataset库我还有问题没有解决清楚,因此先用feed_dict方法。
首先问题1是需要我们合成特征:
创建一个名为 rooms_per_person 的特征。
df = pd.read_csv('california_housing_train.csv')
df['median_house_value'] /=1000
df['rooms_per_person'] = df['total_rooms']/df['population'].astype('float32')
df = df.reindex(np.random.permutation(df.index))
x1 = df[['rooms_per_person']]
y1 = df[['median_house_value']].astype('float32')这里的df[[]]和 [:, np.newaxis]的效果一样,我们可以自行选择其中的一种方法。
loss依旧使用的RMSE
我构建的框架和上次基本无异。这次只有一个神经元。
import pandas as pd
import tensorflow as tf
import numpy as np
def add_layer(inputs, input_size, output_size, activation_function=None):
weights = tf.Variable(tf.random_normal([input_size, output_size]))
biases = tf.Variable(tf.zeros(output_size)+0.1)
wx_b = tf.matmul(inputs, weights) + biases
if activation_function is None:
outputs = wx_b
else:
outputs = activation_function(wx_b)
return outputs
df = pd.read_csv('california_housing_train.csv')
df['median_house_value'] /= 1000
df['rooms_per_person'] = df['total_rooms']/df['population'].astype('float32')
df = df.reindex(np.random.permutation(df.index))
x1 = df[['rooms_per_person']]
y1 = df[['median_house_value']].astype('float32')
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
l1 = add_layer(xs, 1, 1)
loss = tf.sqrt(tf.reduce_mean(tf.square(l1 - ys)))
train_step = tf.train.AdamOptimizer(0.1).minimize(loss)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(1000):
sess.run(train_step, feed_dict={xs: x1, ys: y1})
if i % 50 == 0:
print(sess.run(loss, feed_dict={xs: x1, ys: y1}))
同样我们也将结果输出为散点图。
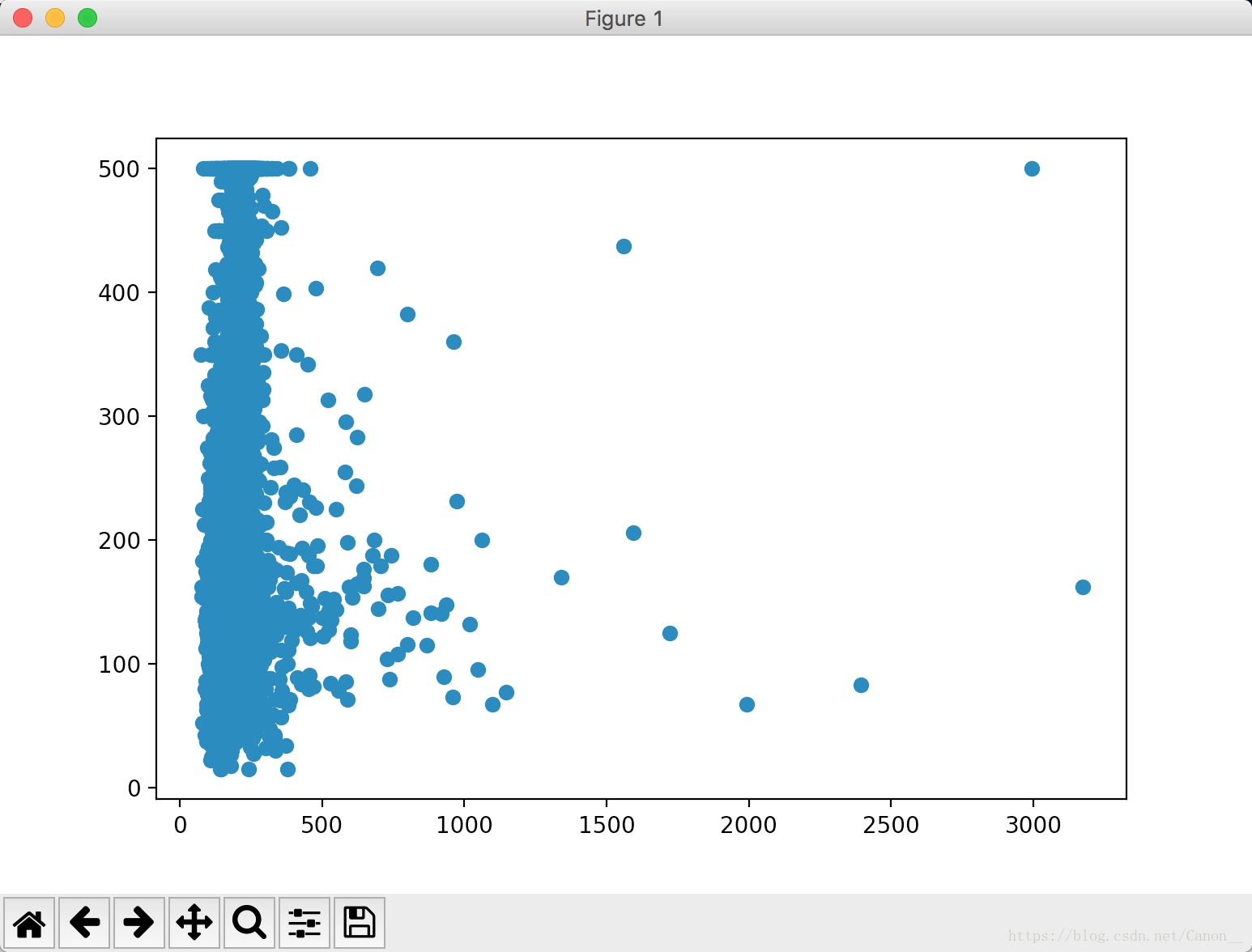
我们看到大部分点都在一条直线上,少量的点偏离的很厉害,我们这时画出输入值的直方图。
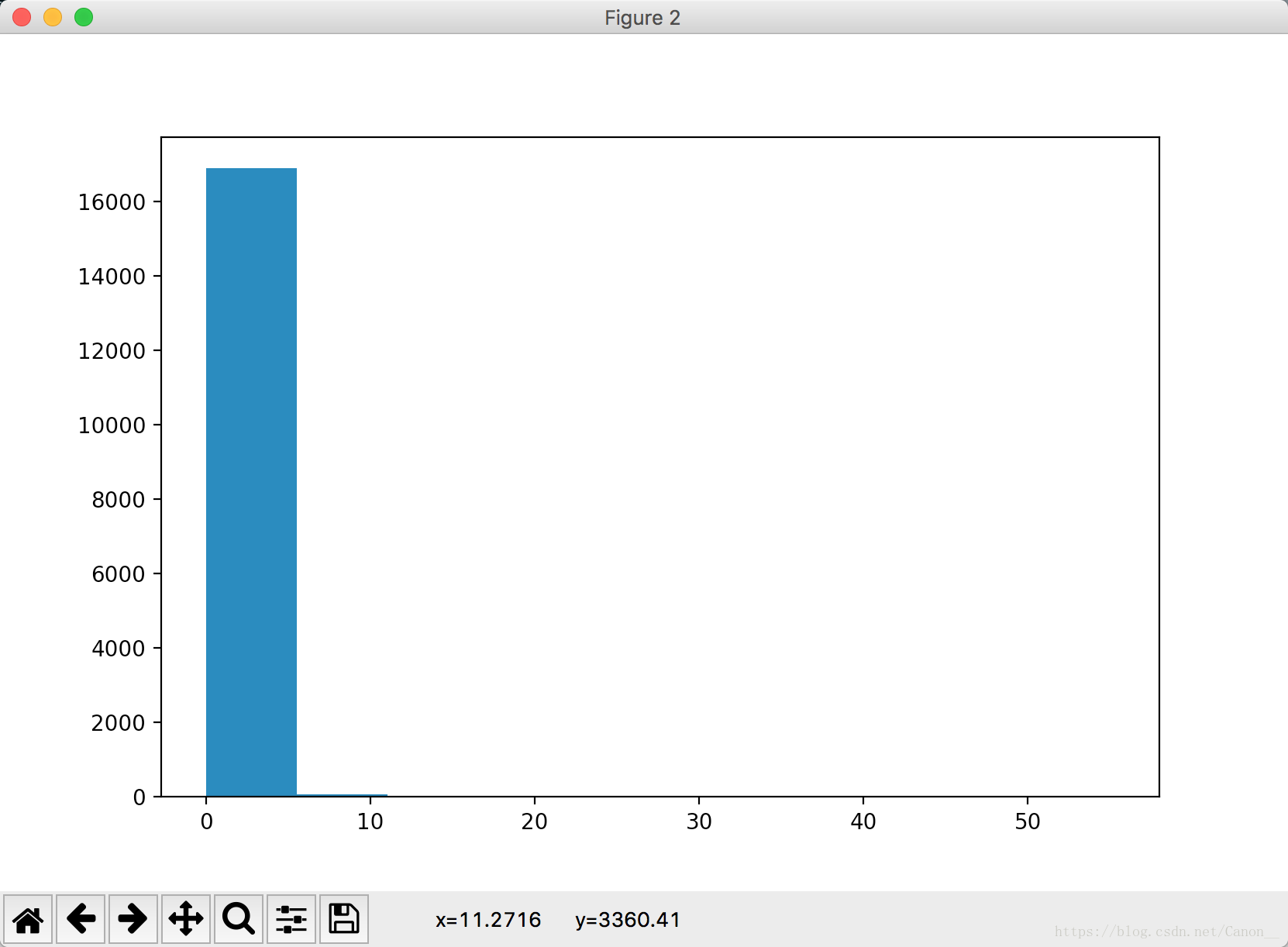
虽然不明显,但是我们还是能看出来我们的数据中有少量的离群值。
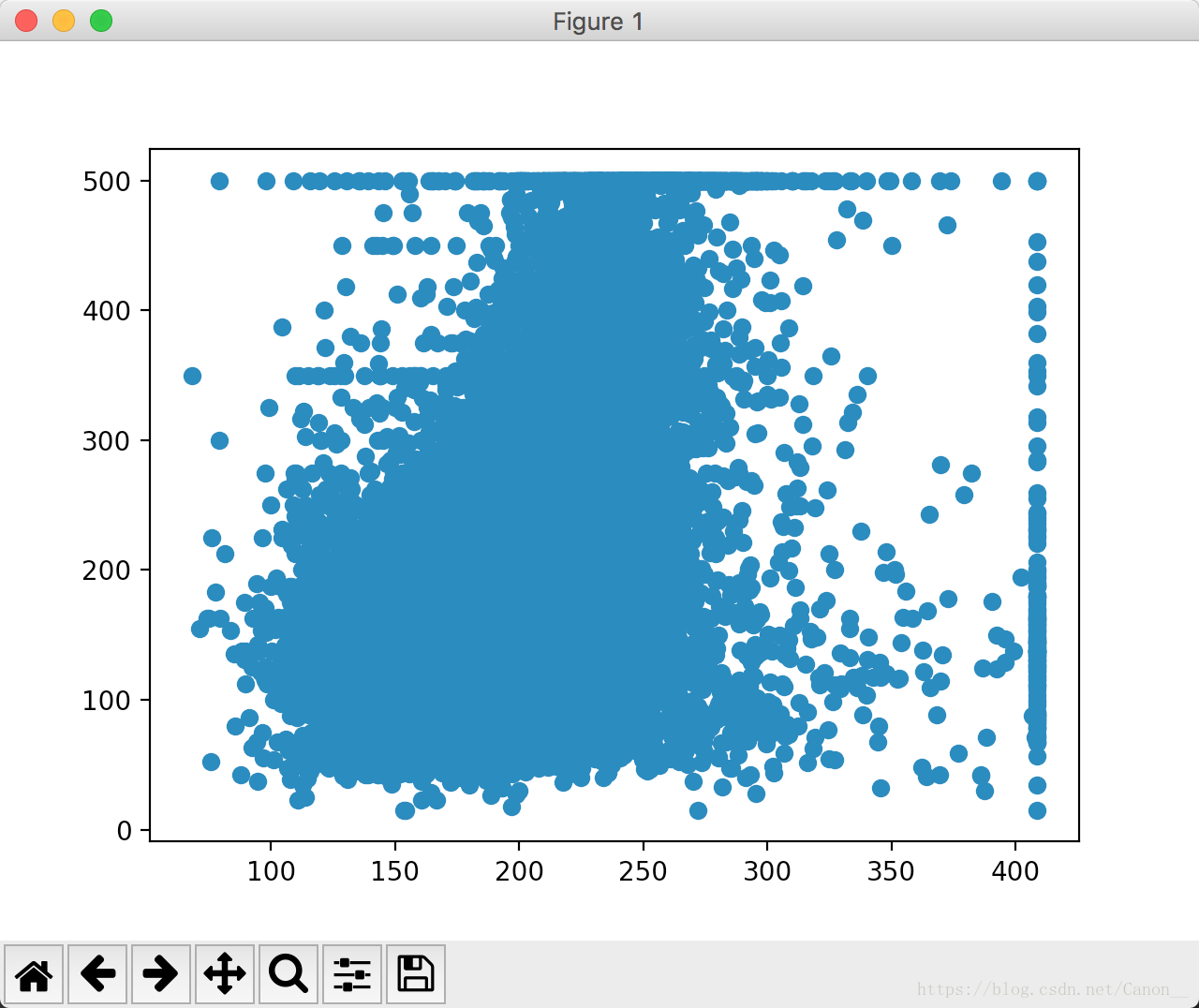
我们按照原文的方法把输入值最大设置为5:
df['rooms_per_person'] = df['rooms_per_person'].apply(lambda x:min(x, 5))也可以
df['rooms_per_person'] = np.clip(df['rooms_per_person'], 0, 5)按照这种方法,我们的确看到了RMSE减少了,同时我画出了预测值和实际值的散点图。
以前一直用numpy 和pandas处理特征,过程很繁琐,并没有使用过Dataset,因此写在这里害怕有错误会误导别人。如果tf为我们提供了特征的处理方法那真是再好不过了,等我弄明白会单独写一个帖子着重去讲Dataset的用法。
最后
以上就是小巧纸鹤最近收集整理的关于【学习笔记】合成特征与离群值的全部内容,更多相关【学习笔记】合成特征与离群值内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复