参考文档:http://pda.readthedocs.io/en/latest/chp5.html
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.reindex.html
DataFrame.reindex(index=None, columns=None, **kwargs)
reindex 函数的参数
| 参数 | 说明 |
|---|---|
| method | 插值填充方法 |
| fill_value | 引入的缺失数据值 |
| limit | 填充间隙 |
| copy | 如果新索引与就的相等则底层数据不会拷贝。默认为True(即始终拷贝) |
| level | 在多层索引上匹配简单索引 |
pandas的reindex对象,是数据符合新的索引来构造一个新的对象
import pandas as pd
obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c'])
obj
d 4.5
b 7.2
a -5.3
c 3.6
dtype: float64
Series的reindex使它符合新的索引,如果索引的值不存在就填入缺失值
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
obj2
a -5.3
b 7.2
c 3.6
d 4.5
e NaN
dtype: float64
obj.reindex(['a', 'b', 'c', 'd', 'e'], fill_value=0)
a -5.3
b 7.2
c 3.6
d 4.5
e 0.0
dtype: float64method选项来控制填充值或内插值:
method : {None, ‘backfill’/’bfill’, ‘pad’/’ffill’, ‘nearest’}, optional。
ffill/pad 向前或进位填充,bfill/backfill 向后或进位填充
obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
obj3.reindex(range(6), method='ffill')
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object向后填充
obj3.reindex(range(6), method='bfill')
0 blue
1 purple
2 purple
3 yellow
4 yellow
5 NaN
dtype: object对于DataFrame, reindex 可以改变(行)索引,列或两者。当只传入一个序列时,结果中的行被重新索引:
frame = pd.DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'],columns=['Ohio', 'Texas', 'California'])
frame
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
frame2 = frame.reindex(['a', 'b', 'c', 'd'])
frame2
Ohio Texas California
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0使用column可以将列进行重新索引
states = ['Texas', 'Utah', 'California']
frame.reindex(columns=states)
Texas Utah California
a 1 NaN 2
c 4 NaN 5
d 7 NaN 8此时的frame依然是原样
frame
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8也可以同时读列和index进行reindex,可是插值只在行侧
frame.reindex(index=['a', 'b', 'c', 'd'], method='ffill',columns=states)
Texas Utah California
a 1 NaN 2
b 1 NaN 2
c 4 NaN 5
d 7 NaN 8
level
关于level可能大家不太理解。level主要在多层索引上用到。举例:
继续之前的话题,我想看到新生儿名字中最后一位字母的变化.
get_last_letter=lambda x:x[-1]
last_letters=names.name.map(get_last_letter)
last_letters.name='last_letter'
table=pd.pivot_table(names,index=[last_letters],values='births',columns=['sex','year'],aggfunc=sum)
table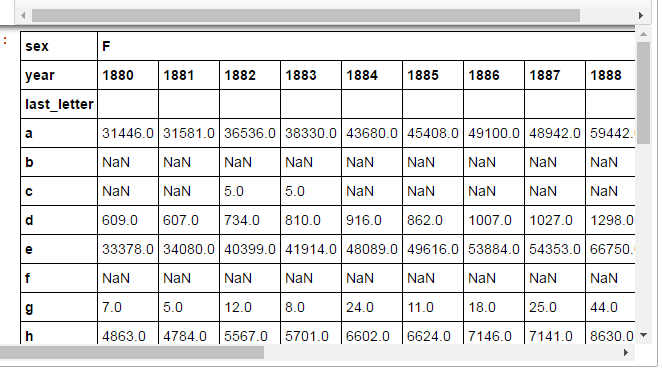
比如我想看其中三年的数据,改怎么办。
按照之前的做法,需要table[‘column name’],但是你会发现table[‘F’]或者table[‘M’]还行,但是还有一层column可怎么办。
正确做法如下:
subtable=table.reindex(columns=[1910,1960,2010],level='year')
subtable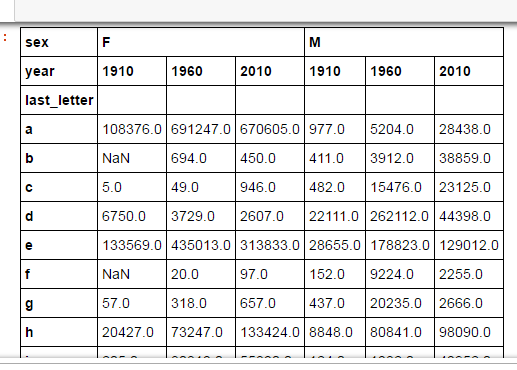
请细细体会。
subtable.index
Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'],
dtype='object', name='last_letter')
In [7]:
subtable.columns
MultiIndex(levels=[['F', 'M'], [1910, 1960, 2010]],
labels=[[0, 0, 0, 1, 1, 1], [0, 1, 2, 0, 1, 2]],
names=['sex', 'year'])下一章讲MultiIndex
最后
以上就是平常板凳最近收集整理的关于利用python做数据分析(六)-reindex的全部内容,更多相关利用python做数据分析(六)-reindex内容请搜索靠谱客的其他文章。








发表评论 取消回复