spark的前世今生
一、spark是什么?(介绍)
Spark,是一种"OneStack to rule them all"的大数据计算框架,是一种基于内存的分布式计算框架,于2009年诞生于加州大学伯克利分校AMPLab(AMP:Algorithms,Machines,People),它最初属于伯克利大学的研究性项目,后来在2010年正式开源,并于 2013 年成为了 Apache 基金项目,到2014年便成为 Apache 基金的顶级项目,该项目整个发展历程刚过六年时间,但其发展速度非常惊人。是一种通用的大数据快速处理引擎。
OneStack to rule them all:使用一个技术堆栈就完美地解决大数据领域的各种计算任务
spark的框架包括Spark Core(用于离线批处理)、Spark SQL(交互式查询)、Spark Streaming(实时流计算)、MLlib(机器学习)、GraphX(图计算)等重要处理组件。
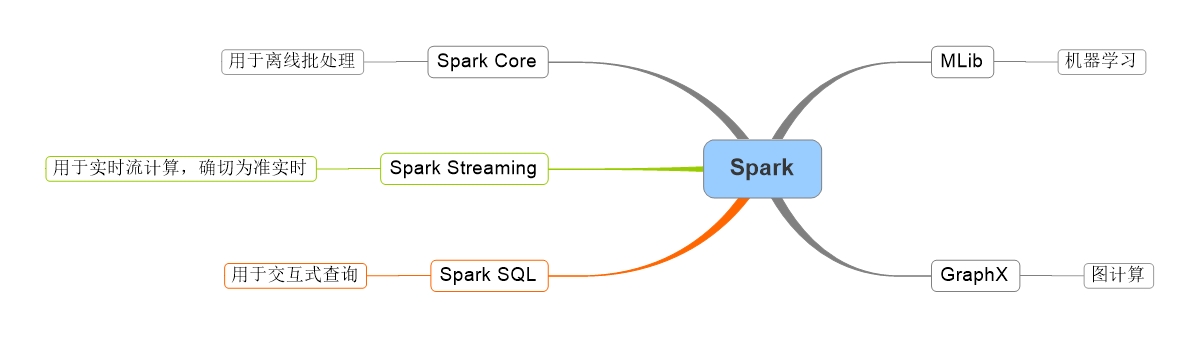
spark最终要的特点是基于内存进行计算的!!!
spark最终要的特点是基于内存进行计算的!!!
spark最终要的特点是基于内存进行计算的!!!
重要的事情说3遍。
二、spark的整体架构
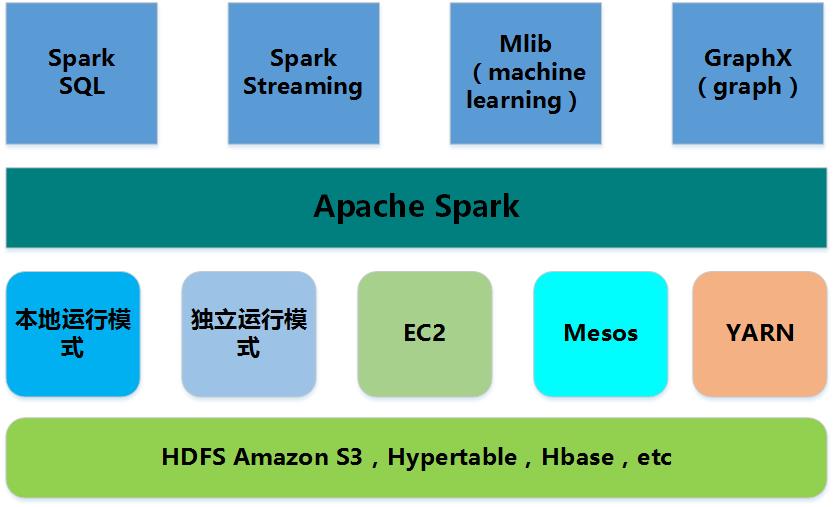
上面介绍了spark包括Spark Core,Spark Streaming, Spark SQL,Mlib和GraphX。
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
三、spark的发展历史
-
2009年,Spark诞生于伯克利大学的AMPLab实验室。最出Spark只是一个实验性的项目,代码量非常少,属于轻量级的框架。
-
2010年,伯克利大学正式开源了Spark项目。
-
2013年,Spark成为了Apache基金会下的项目,进入高速发展期。第三方开发者贡献了大量的代码,活跃度非常高。
-
2014年,Spark以飞快的速度称为了Apache的顶级项目。
-
2015年~,Spark在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架。
这有一个版本迭代的发展过程
四、spark的特点
轻量级快速处理:Spark基于内存进行计算(当然也有部分计算基于磁盘,比如shuffle)。Spark通过减少磁盘IO来达到性能的提升,它们将中间处理数据全部放到了内存中。Spark使用了RDD(Resilient Distributed Datasets)数据抽象,这允许它可以在内存中存储数据,只在需要时才持久化到磁盘。这种做法大大的减少了数据处理过程中磁盘的读写,大幅度的降低了运行时间。
容易上手开发:Spark支持多语言。Spark允许Java、Scala、Python及R(Spark 1.4版最新支持),这允许更多的开发者在自己熟悉的语言环境下进行工作,普及了Spark的应用范围,它自带80多个高等级操作符,允许在shell中进行交互式查询,它多种使用模式的特点让应用更灵活。
支持复杂查询
除了简单的map及reduce操作之外,Spark还支持filter、foreach、reduceByKey、aggregate以及SQL查询、流式查询等复杂查询。Spark更为强大之处是用户可以在同一个工作流中无缝的搭配这些功能,例如Spark可以通过Spark Streaming(1.2.2小节对Spark Streaming有详细介绍)获取流数据,然后对数据进行实时SQL查询或使用MLlib库进行系统推荐,而且这些复杂业务的集成并不复杂,因为它们都基于RDD这一抽象数据集在不同业务过程中进行转换,转换代价小,体现了统一引擎解决不同类型工作场景的特点。有关Streaming技术以及MLlib库和RDD将会这之后几个章节进行详述。
超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务。
与已存Hadoop数据整合
Spark不仅可以独立的运行(使用standalone模式),还可以运行在当下的YARN管理集群中。它还可以读取已有的任何Hadoop数据,这是个非常大的优势,它可以运行在任何Hadoop数据源上,比如HBase、HDFS、Hive等。如果合适的话,这个特性让用户可以轻易迁移已有Hadoop应用。
极高的活跃度:Spark目前是Apache基金会的顶级项目,全世界有大量的优秀工程师是Spark的committer。并且世界上很多顶级的IT公司都在大规模地使用Spark。
五、spark VS MapReduce
MapReduce存在的问题
- MapReduce框架局限性
1)仅支持Map和Reduce两种操作
2)处理效率低效。
a)Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据; 任务调度和启动开销大;
b)无法充分利用内存
c)Map端和Reduce端均需要排序
3)不适合迭代计算(如机器学习、图计算等),交互式处理(数据挖掘) 和流式处理(点击日志分析)
- MapReduce编程不够灵活
1)尝试scala函数式编程语言
Spark
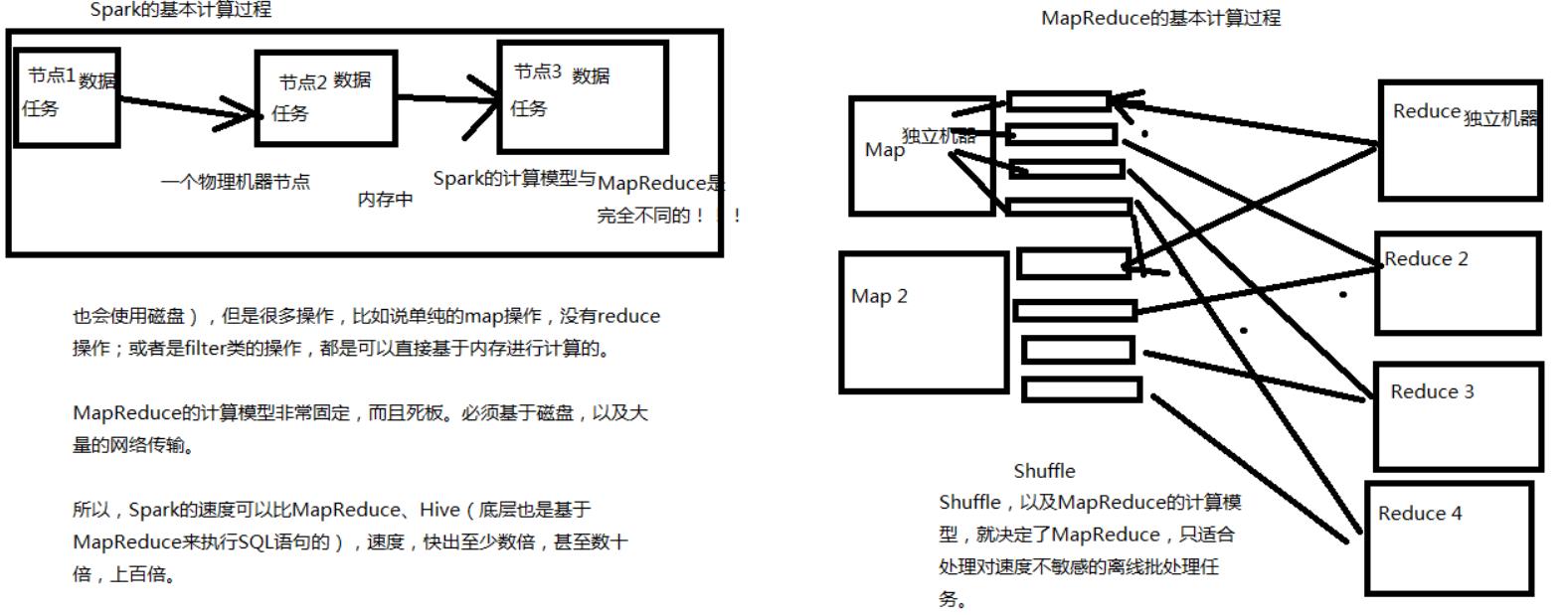
- 高效(比MapReduce快10~100倍)
1)内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
2)DAG引擎,减少多次计算之间中间结果写到HDFS的开销
3)使用多线程池模型来减少task启动开稍,shuffle过程中避免 不必要的sort操作以及减少磁盘IO操作
- 易用
1)提供了丰富的API,支持Java,Scala,Python和R四种语言
2)代码量比MapReduce少2~5倍
- 与Hadoop集成 读写HDFS/Hbase 与YARN集成
但是Spark也有其劣势。由于Spark基于内存进行计算,虽然开发容易,但是真正面对大数据的时候(比如一次操作针对10亿以上级别),在没有进行调优的情况下,可能会出现各种各样的问题,比如OOM内存溢出等等。导致Spark程序可能都无法完全运行起来,就报错挂掉了,而MapReduce即使是运行缓慢,但是至少可以慢慢运行完。
六、Spark SQL VS Hive
Hive本质是是什么
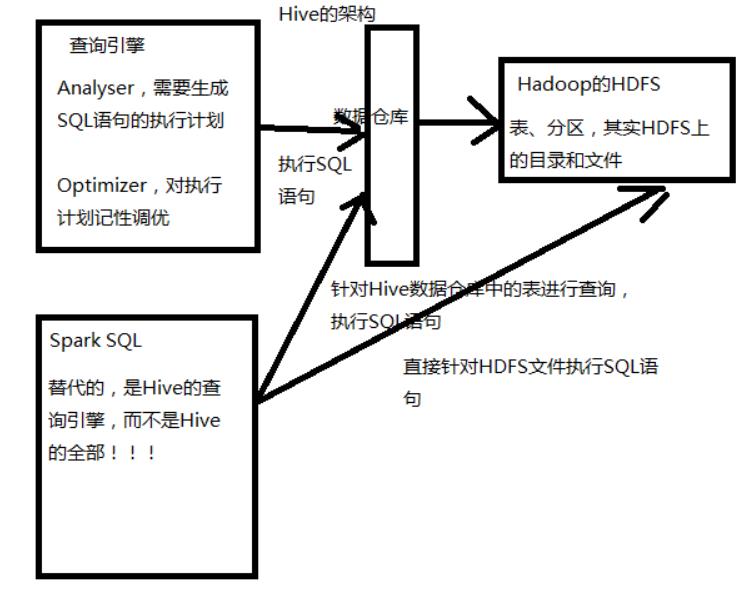
1:hive是分布式又是数据仓库,同时又是查询引擎,Spark SQL只是取代的HIVE的查询引擎这一部分,企业一般使用Hive+spark SQL进行开发
2:hive的主要工作
1> 把HQL翻译长map-reduce的代码,并且有可能产生很多mapreduce的job
2> 把生产的Mapreduce代码及相关资源打包成jar并发布到Hadoop的集群当中并进行运行
3:hive架构
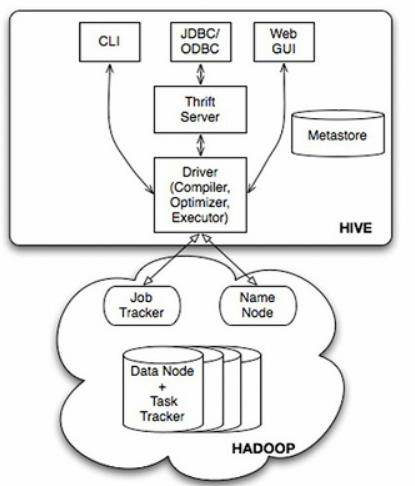
4:hive默认情况下用derby存储元数据,所以在生产环境下一般会采用多用户的数据库进行元数据的存储,并可以读写分离和备份,一般使用主节点写,从节点读,一般使用mysql
5:hive数据仓库数据的具体存储
SparkSQL 和DataFrame
1:处理一切存储介质和各种格式的数据(可以扩展sparksql来读取更多类型的数据)
2:Spark SQL把数据仓库的计算速度推向了新的高度(Tungsten成熟之后会更厉害)
3:Spark SQL 推出的Dataframe可以让数据仓库直接使用机器学习,图计算等复杂算法
4:HIVE+Spark SQL+DataFrame:
i> Hive:负责廉价的数据仓库存储
ii>Spark Sql:负责高速的计算
iii> DataFrame:负责复杂的数据挖掘
综上,严格的来说,Spark SQL实际上并不能完全替代Hive,因为Hive是一种基于HDFS的数据仓库,并且提供了基于SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎。SparkSQL能够替代的,是Hive的查询引擎,而不是Hive本身,实际上即使在生产环境下,Spark SQL也是针对Hive数据仓库中的数据进行查询,Spark本身自己是不提供存储的,自然也不可能替代Hive作为数据仓库的这个功能。
七、Spark Streaming Vs Storm
Storm和Spark Streaming都是分布式流处理的开源框架,但是它们之间还是有一些区别的,这里将进行比较并指出它们的重要的区别。
- 处理模型以及延迟
虽然这两个框架都提供可扩展性(Scalability)和可容错性(Fault Tolerance),但是它们的处理模型从根本上说是不一样的。Storm处理的是每次传入的一个事件,而Spark Streaming是处理某个时间段窗口内的事件流。因此,Storm处理一个事件可以达到亚秒级的延迟,而Spark Streaming则有秒级的延迟。
- 容错和数据保证
在容错数据保证方面的权衡方面,Spark Streaming提供了更好的支持容错状态计算。在Storm中,当每条单独的记录通过系统时必须被跟踪,所以Storm能够至少保证每条记录将被处理一次,但是在从错误中恢复过来时候允许出现重复记录,这意味着可变状态可能不正确地被更新两次。而Spark Streaming只需要在批处理级别对记录进行跟踪处理,因此可以有效地保证每条记录将完全被处理一次,即便一个节点发生故障。虽然Storm的 Trident library库也提供了完全一次处理的功能。但是它依赖于事务更新状态,而这个过程是很慢的,并且通常必须由用户实现。
简而言之,如果你需要亚秒级的延迟,Storm是一个不错的选择,而且没有数据丢失。如果你需要有状态的计算,而且要完全保证每个事件只被处理一次,Spark Streaming则更好。Spark Streaming编程逻辑也可能更容易,因为它类似于批处理程序,特别是在你使用批次(尽管是很小的)时。
- 实现和编程API
Storm主要是由Clojure语言实现,Spark Streaming是由Scala实现。如果你想看看这两个框架是如何实现的或者你想自定义一些东西你就得记住这一点。Storm是由BackType和 Twitter开发,而Spark Streaming是在UC Berkeley开发的。
Storm提供了Java API,同时也支持其他语言的API。 Spark Streaming支持Scala和Java语言(其实也支持Python)。另外Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以想使用其他批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询。这就减少了单独编写流批量处理程序和历史数据处理程序。
- 生产支持
Storm已经出现好多年了,而且自从2011年开始就在Twitter内部生产环境中使用,还有其他一些公司。而Spark Streaming是一个新的项目,并且在2013年仅仅被Sharethrough使用(据作者了解)。
Storm是 Hortonworks Hadoop数据平台中流处理的解决方案,而Spark Streaming出现在 MapR的分布式平台和Cloudera的企业数据平台中。除此之外,Databricks是为Spark提供技术支持的公司,包括了Spark Streaming。
- 集群管理集成
尽管两个系统都运行在它们自己的集群上,Storm也能运行在Mesos,而Spark Streaming能运行在YARN 和 Mesos上。
| 对比 | Storm | Spark Streaming |
|---|---|---|
| 实时计算模型 | 纯实时,来一条数据,处理一条数据 | 准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
| 实时计算延迟 | 毫秒级 | 秒级 |
| 吞吐量 | 低 | 高 |
| 事务机制 | 支持完善 | 支持,但不够完善 |
| 健壮性/容错性 | Zookeeper,Acker,非常强 | Checkpoint,WAL,一般 |
| 动态调整并行度 | 支持 | 不支持 |

参考
Spark入门教程(1)——spark是什么及发展趋势概述
Spark相对于MapReduce的优势
Spark(一): 基本架构及原理
spark hive区别
Storm介绍及与Spark Streaming对比
Spark Streaming与Storm的对比分析
最后
以上就是时尚往事最近收集整理的关于spark的前世今生spark的前世今生的全部内容,更多相关spark内容请搜索靠谱客的其他文章。








发表评论 取消回复