员工工资:
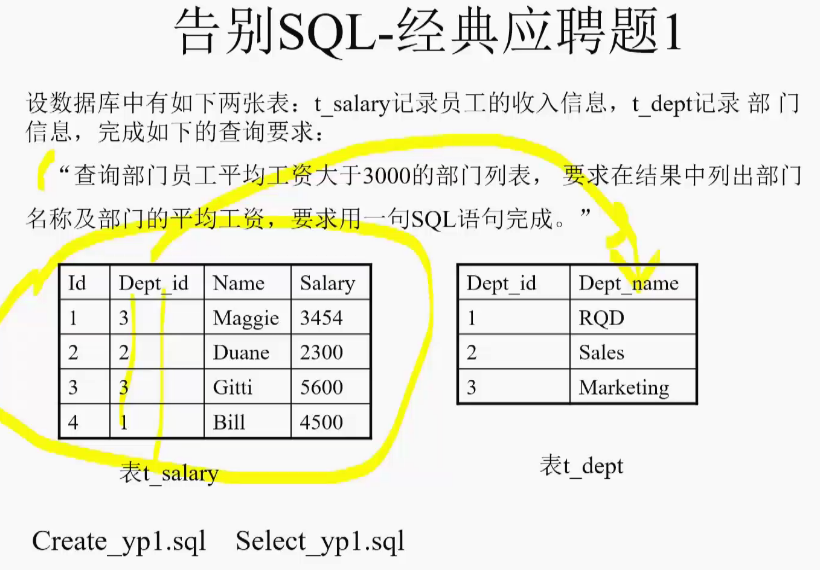
实现:
drop table t_salary;
drop table t_dept;--部门信息
create table t_salary(
id varchar(2),
dept_id varchar(2),
name varchar(20),
salary number(7,2)
);
insert into t_salary values('1','1','Maggie',3454);
insert into t_salary values('2','2','Jerry',2300);
insert into t_salary values('3','3','Gitti',5600);
insert into t_salary values('1','1','Bill',4500);
create table t_dept(
dept_id varchar(2),
dept_name varchar(20)
);
insert into t_dept values('1','RQD');
insert into t_dept values('2','Sales');
insert into t_dept values('3','Markting');
select
dept_name "部门名字",
t_salary.dept_id "部门编号",
avg(salary) "平均工资" --分组内的平均值
from t_salary,t_dept
where t_salary.dept_id=t_dept.dept_id
group by t_salary.Dept_id,dept_name --用两个作为分组依据:如果只有id的话,部门名无法显示,而只有部门名字可能会重复。
having avg(salary)>3000;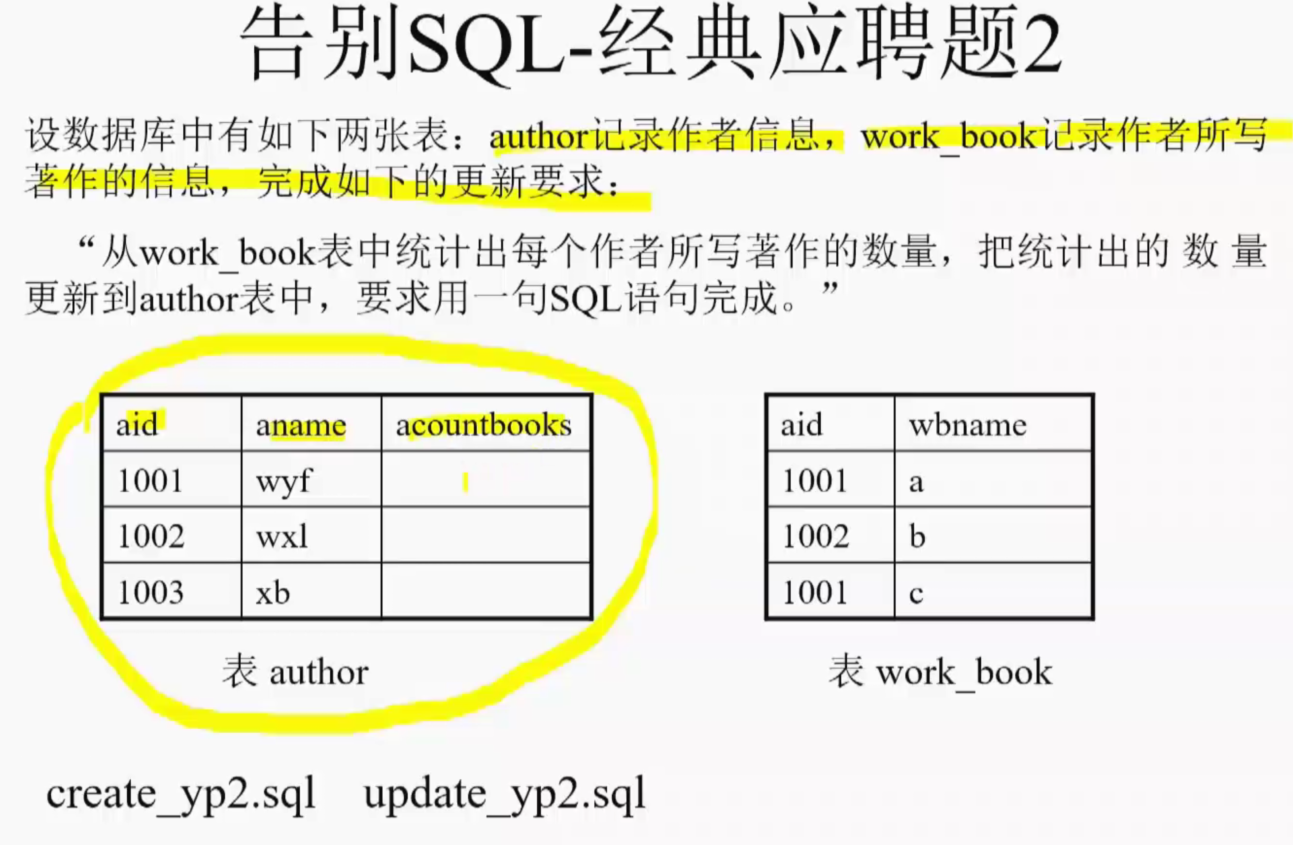
drop table author;
drop table work_book;
create table author(
aid varchar(5),
aname varchar(20),
acountbooks number(4)
);
insert into author values('1001','wyf',null);
insert into author values('1002','jhl',null);
insert into author values('1003','lm',null);
insert into author values('1004','zn',null);
create table work_book(
aid varchar(5),
wbname varchar(20)
);
insert into work_book values('1001','a');
insert into work_book values('1002','b');
insert into work_book values('1003','c');
insert into work_book values('1001','d');
update author aa --给author起别名
set acountbooks=
NVL(
(select count(aid) from work_book
group by aid
having aid=aa.aid
),
0
);注:sql中where和having的使用场景与区别
TOPN分析:取检索结果的前n条记录(或第A条到第B条)。
方式:配合使用嵌套和ROWNUM 伪列。
drop table course;--因为与学生表建立关联,两表也可能与S_C表有外键关系。
drop table student;
create table student(
sid char(5),
sname varchar2(20),
sage number(2)
);
insert into student values('10001','Tom',18);
insert into student values('10002','Jerry',22);
insert into student values('10003','Lili',19);
insert into student values('10004','Hank',20);
insert into student values('10005','Kevin',23);
insert into student values('10006','Carl',20);
insert into student values('10007','Tucas',21);
insert into student values('10008','Joan',20);
insert into student values('10009','Emma',18);
insert into student values('10010','Paul',19);
insert into student values('10011','Ben',22);
select * from student;
select sid,sname,sage from student --所有信息倒排序打印
order by sage Desc;
select sid,sname,sage,mrw from --检索大到小第5到第7
(
select sid,sname,sage,rownum mrw from --select查出的rownum只会从一开始排序(但显示结果不一定有序)
(
select sid,sname,sage from student
order by sage desc
)
)
where mrw<=7 and mrw>=5;
注:如果是要前几名,在第二层循环就可以实现,不用最外层,
因为检索条件中不可以有rownum大于多少(返回false),所以作为一个列输出后在检索。
select sid,sname,sage,rownum mrw from --前7行
(
select sid,sname,sage from student
order by sage desc
)
where rownum<=7; 

使用case语句替代多个查询
drop table student;
create table student
(
sno char(5),
sname varchar(20),
sage number(2)
);
insert into student values('10001','Tom',18);
insert into student values('10002','Jerry',28);
insert into student values('10003','Lili',29);
insert into student values('10004','Hank',20);
insert into student values('10005','Kevin',33);
insert into student values('10006','Carl',34);
insert into student values('10007','Tucas',21);
commit;
select count(*) "25岁及以下" from student
where sage<=25;
select count(*) "25岁以上30岁以下" from student
where sage>25 and sage<=30;
select count(*) "30岁以上" from student
where sage>25;
合成一句后:
select
count(case when sage<=25 then 1 else null end) "25岁及以下",
count(case when sage>25 and sage<=30 then 1 else null end) "25岁以上30岁及以下",
count(case when sage>30 then 1 else null end) "30岁以上"
from student; 使用exists 而不是 distinct
distinct 用于禁止重复行的显示,exist用于检查子 查询结果的返回行的存在性。尽量少用distinct,因为distinct使用前会先将结果排序(耗资源)在去除重复
使用exists而不是in(前提:都可实现)
drop table product;
drop table purchase;
create table product
(
pid char(5),
pname varchar(40)
);
create table purchase
(
pid char(5),
pcount number(3) --售卖量
);
insert into product values('10001','佳洁士牙膏');
insert into product values('10002','海飞丝洗发水');
insert into product values('10003','可口可乐');
insert into product values('10004','王老吉');
insert into product values('10005','碧浪洗衣粉');
insert into purchase values('10001',1);
insert into purchase values('10002',2);
insert into purchase values('10003',3);
insert into purchase values('10004',4);
insert into purchase values('10004',4);
commit;
--没有消除重复
select product.pid,product.pname --检索卖出的项
from product,purchase
where product.pid=purchase.pid;
--用distinct去重
select distinct product.pid,product.pname --检索卖出的项
from product,purchase
where product.pid=purchase.pid;
--用exists去重
select pid,pname --检索卖出的项
from product outer
where exists
(
select 1 from purchase inner
where inner .pid=outer.pid
);
--用in
select pid,pname
from product
where pid in
(
select pid from purchase
);
课后作业:



数据库设计图(OMT)举例:
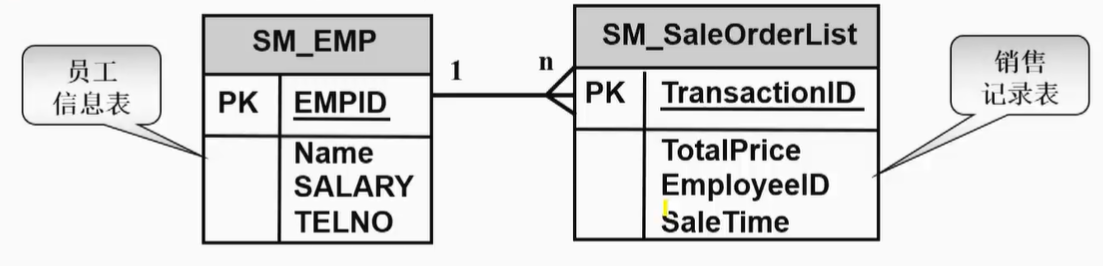
最后
以上就是甜甜手链最近收集整理的关于经典数据库面试题--员工部门平均工资&作者出书问题&Topn分析的全部内容,更多相关经典数据库面试题--员工部门平均工资&作者出书问题&Topn分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复