开始使用 Keras Sequential 顺序模型
顺序模型是多个网络层的线性堆叠。
你可以通过将网络层实例的列表传递给 Sequential 的构造器,来创建一个 Sequential 模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])也可以简单地使用 .add() 方法将各层添加到模型中:
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))指定输入数据的尺寸
模型需要知道它所期望的输入的尺寸。出于这个原因,顺序模型中的第一层(且只有第一层,因为下面的层可以自动地推断尺寸)需要接收关于其输入尺寸的信息。有几种方法来做到这一点:
- 传递一个
input_shape参数给第一层。它是一个表示尺寸的元组 (一个由整数或None组成的元组,其中None表示可能为任何正整数)。在input_shape中不包含数据的 batch 大小。 - 某些 2D 层,例如
Dense,支持通过参数input_dim指定输入尺寸,某些 3D 时序层支持input_dim和input_length参数。 - 如果你需要为你的输入指定一个固定的 batch 大小(这对 stateful RNNs 很有用),你可以传递一个
batch_size参数给一个层。如果你同时将batch_size=32和input_shape=(6, 8)传递给一个层,那么每一批输入的尺寸就为(32,6,8)。
因此,下面的代码片段是等价的:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model = Sequential()
model.add(Dense(32, input_dim=784))模型编译
在训练模型之前,您需要配置学习过程,这是通过 compile 方法完成的。它接收三个参数:
- 优化器 optimizer。它可以是现有优化器的字符串标识符,如
rmsprop或adagrad,也可以是 Optimizer 类的实例。详见:optimizers。 - 损失函数 loss,模型试图最小化的目标函数。它可以是现有损失函数的字符串标识符,如
categorical_crossentropy或mse,也可以是一个目标函数。详见:losses。 - 评估标准 metrics。对于任何分类问题,你都希望将其设置为
metrics = ['accuracy']。评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数。
# 多分类问题
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 二分类问题
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 均方误差回归问题
model.compile(optimizer='rmsprop',
loss='mse')
# 自定义评估标准函数
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])模型训练
Keras 模型在输入数据和标签的 Numpy 矩阵上进行训练。为了训练一个模型,你通常会使用 fit 函数。文档详见此处。
# 对于具有 2 个类的单输入模型(二进制分类):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 生成虚拟数据
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# 训练模型,以 32 个样本为一个 batch 进行迭代
model.fit(data, labels, epochs=10, batch_size=32)Epoch 1/10
1000/1000 [==============================] - 0s 255us/step - loss: 0.7057 - accuracy: 0.5310
Epoch 2/10
1000/1000 [==============================] - 0s 40us/step - loss: 0.6923 - accuracy: 0.5420
Epoch 3/10
1000/1000 [==============================] - 0s 42us/step - loss: 0.6866 - accuracy: 0.5690
Epoch 4/10
1000/1000 [==============================] - 0s 44us/step - loss: 0.6825 - accuracy: 0.5630
Epoch 5/10
1000/1000 [==============================] - 0s 48us/step - loss: 0.6804 - accuracy: 0.5600
Epoch 6/10
1000/1000 [==============================] - 0s 46us/step - loss: 0.6746 - accuracy: 0.5720
Epoch 7/10
1000/1000 [==============================] - 0s 46us/step - loss: 0.6744 - accuracy: 0.5790
Epoch 8/10
1000/1000 [==============================] - 0s 48us/step - loss: 0.6696 - accuracy: 0.5870
Epoch 9/10
1000/1000 [==============================] - 0s 50us/step - loss: 0.6682 - accuracy: 0.5880
Epoch 10/10
1000/1000 [==============================] - 0s 48us/step - loss: 0.6632 - accuracy: 0.6090
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 生成虚拟数据
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# 将标签转换为分类的 one-hot 编码
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# 训练模型,以 32 个样本为一个 batch 进行迭代
model.fit(data, one_hot_labels, epochs=10, batch_size=32)Epoch 1/10
1000/1000 [==============================] - 0s 173us/step - loss: 2.3313 - accuracy: 0.1140
Epoch 2/10
1000/1000 [==============================] - 0s 33us/step - loss: 2.3126 - accuracy: 0.0990
Epoch 3/10
1000/1000 [==============================] - 0s 31us/step - loss: 2.3012 - accuracy: 0.1110
Epoch 4/10
1000/1000 [==============================] - 0s 30us/step - loss: 2.2929 - accuracy: 0.1210
Epoch 5/10
1000/1000 [==============================] - 0s 30us/step - loss: 2.2833 - accuracy: 0.1420
Epoch 6/10
1000/1000 [==============================] - 0s 36us/step - loss: 2.2740 - accuracy: 0.1400
Epoch 7/10
1000/1000 [==============================] - 0s 32us/step - loss: 2.2673 - accuracy: 0.1470
Epoch 8/10
1000/1000 [==============================] - 0s 35us/step - loss: 2.2580 - accuracy: 0.1540
Epoch 9/10
1000/1000 [==============================] - 0s 31us/step - loss: 2.2505 - accuracy: 0.1560
Epoch 10/10
1000/1000 [==============================] - 0s 37us/step - loss: 2.2441 - accuracy: 0.1710样例
这里有几个可以帮助你起步的例子!
在 examples 目录 中,你可以找到真实数据集的示例模型:
- CIFAR10 小图片分类:具有实时数据增强的卷积神经网络 (CNN)
- IMDB 电影评论情感分类:基于词序列的 LSTM
- Reuters 新闻主题分类:多层感知器 (MLP)
- MNIST 手写数字分类:MLP & CNN
- 基于 LSTM 的字符级文本生成
基于多层感知器 (MLP) 的 softmax 多分类:
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# 生成虚拟数据
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# Dense(64) 是一个具有 64 个隐藏神经元的全连接层。
# 在第一层必须指定所期望的输入数据尺寸:
# 在这里,是一个 20 维的向量。
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)Epoch 1/20
1000/1000 [==============================] - 0s 252us/step - loss: 2.3638 - accuracy: 0.1150
Epoch 2/20
1000/1000 [==============================] - 0s 17us/step - loss: 2.3619 - accuracy: 0.1040
Epoch 3/20
1000/1000 [==============================] - 0s 17us/step - loss: 2.3307 - accuracy: 0.1080
Epoch 4/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.3192 - accuracy: 0.1050
Epoch 5/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.3044 - accuracy: 0.1260
Epoch 6/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.3141 - accuracy: 0.1040
Epoch 7/20
1000/1000 [==============================] - 0s 20us/step - loss: 2.3065 - accuracy: 0.1150
Epoch 8/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.3047 - accuracy: 0.1140
Epoch 9/20
1000/1000 [==============================] - 0s 20us/step - loss: 2.3123 - accuracy: 0.1110
Epoch 10/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.3075 - accuracy: 0.1120
Epoch 11/20
1000/1000 [==============================] - 0s 17us/step - loss: 2.3060 - accuracy: 0.1200
Epoch 12/20
1000/1000 [==============================] - 0s 19us/step - loss: 2.3011 - accuracy: 0.1080
Epoch 13/20
1000/1000 [==============================] - 0s 19us/step - loss: 2.2964 - accuracy: 0.1150
Epoch 14/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.2976 - accuracy: 0.1230
Epoch 15/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.3007 - accuracy: 0.1230
Epoch 16/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.3073 - accuracy: 0.1190
Epoch 17/20
1000/1000 [==============================] - 0s 18us/step - loss: 2.2943 - accuracy: 0.1210
Epoch 18/20
1000/1000 [==============================] - 0s 19us/step - loss: 2.2996 - accuracy: 0.1170
Epoch 19/20
1000/1000 [==============================] - 0s 19us/step - loss: 2.2941 - accuracy: 0.1140
Epoch 20/20
1000/1000 [==============================] - 0s 19us/step - loss: 2.2935 - accuracy: 0.1230
100/100 [==============================] - 0s 928us/step
基于多层感知器的二分类:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# 生成虚拟数据
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)Epoch 1/20
1000/1000 [==============================] - 0s 349us/step - loss: 0.7133 - accuracy: 0.5050
Epoch 2/20
1000/1000 [==============================] - 0s 20us/step - loss: 0.7098 - accuracy: 0.5080
Epoch 3/20
1000/1000 [==============================] - 0s 21us/step - loss: 0.7020 - accuracy: 0.4910
Epoch 4/20
1000/1000 [==============================] - 0s 20us/step - loss: 0.6961 - accuracy: 0.5400
Epoch 5/20
1000/1000 [==============================] - 0s 24us/step - loss: 0.7036 - accuracy: 0.5000
Epoch 6/20
1000/1000 [==============================] - 0s 21us/step - loss: 0.7004 - accuracy: 0.4930
Epoch 7/20
1000/1000 [==============================] - 0s 19us/step - loss: 0.6954 - accuracy: 0.5160
Epoch 8/20
1000/1000 [==============================] - 0s 19us/step - loss: 0.6979 - accuracy: 0.4940
Epoch 9/20
1000/1000 [==============================] - 0s 20us/step - loss: 0.7021 - accuracy: 0.4840
Epoch 10/20
1000/1000 [==============================] - 0s 20us/step - loss: 0.6940 - accuracy: 0.5210
Epoch 11/20
1000/1000 [==============================] - 0s 23us/step - loss: 0.6954 - accuracy: 0.5190
Epoch 12/20
1000/1000 [==============================] - 0s 19us/step - loss: 0.6892 - accuracy: 0.5310
Epoch 13/20
1000/1000 [==============================] - 0s 19us/step - loss: 0.6910 - accuracy: 0.5240
Epoch 14/20
1000/1000 [==============================] - 0s 23us/step - loss: 0.6949 - accuracy: 0.5090
Epoch 15/20
1000/1000 [==============================] - 0s 19us/step - loss: 0.6894 - accuracy: 0.5240
Epoch 16/20
1000/1000 [==============================] - 0s 20us/step - loss: 0.6879 - accuracy: 0.5460
Epoch 17/20
1000/1000 [==============================] - 0s 19us/step - loss: 0.6872 - accuracy: 0.5470
Epoch 18/20
1000/1000 [==============================] - 0s 19us/step - loss: 0.6862 - accuracy: 0.5600
Epoch 19/20
1000/1000 [==============================] - 0s 20us/step - loss: 0.6876 - accuracy: 0.5430
Epoch 20/20
1000/1000 [==============================] - 0s 20us/step - loss: 0.6914 - accuracy: 0.5400
100/100 [==============================] - 0s 997us/step类似 VGG 的卷积神经网络:
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# 生成虚拟数据
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# 输入: 3 通道 100x100 像素图像 -> (100, 100, 3) 张量。
# 使用 32 个大小为 3x3 的卷积滤波器。
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)Epoch 1/10
100/100 [==============================] - 2s 20ms/step - loss: 2.4515
Epoch 2/10
100/100 [==============================] - 1s 15ms/step - loss: 2.2862
Epoch 3/10
100/100 [==============================] - 2s 16ms/step - loss: 2.2754
Epoch 4/10
100/100 [==============================] - 2s 16ms/step - loss: 2.2698
Epoch 5/10
100/100 [==============================] - 2s 15ms/step - loss: 2.2889
Epoch 6/10
100/100 [==============================] - 2s 16ms/step - loss: 2.2597
Epoch 7/10
100/100 [==============================] - 2s 18ms/step - loss: 2.2715
Epoch 8/10
100/100 [==============================] - 2s 19ms/step - loss: 2.2686
Epoch 9/10
100/100 [==============================] - 2s 18ms/step - loss: 2.2981
Epoch 10/10
100/100 [==============================] - 2s 19ms/step - loss: 2.2965
20/20 [==============================] - 0s 11ms/step基于 LSTM 的序列分类:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
x_train = np.random.random((1000, 256))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100,256))
y_test = np.random.randint(2, size=(100, 1))
max_features = 1024
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)Epoch 1/10
1000/1000 [==============================] - 12s 12ms/step - loss: 0.6958 - accuracy: 0.5120
Epoch 2/10
1000/1000 [==============================] - 11s 11ms/step - loss: 0.6935 - accuracy: 0.5200
Epoch 3/10
1000/1000 [==============================] - 13s 13ms/step - loss: 0.6928 - accuracy: 0.5190
Epoch 4/10
1000/1000 [==============================] - 12s 12ms/step - loss: 0.6935 - accuracy: 0.5320
Epoch 5/10
1000/1000 [==============================] - 11s 11ms/step - loss: 0.6908 - accuracy: 0.5270
Epoch 6/10
1000/1000 [==============================] - 10s 10ms/step - loss: 0.6942 - accuracy: 0.5170
Epoch 7/10
1000/1000 [==============================] - 10s 10ms/step - loss: 0.6927 - accuracy: 0.5270
Epoch 8/10
1000/1000 [==============================] - 10s 10ms/step - loss: 0.6935 - accuracy: 0.5310
Epoch 9/10
1000/1000 [==============================] - 11s 11ms/step - loss: 0.6929 - accuracy: 0.5240
Epoch 10/10
1000/1000 [==============================] - 11s 11ms/step - loss: 0.6934 - accuracy: 0.5170
100/100 [==============================] - 0s 4ms/step
基于 1D 卷积的序列分类:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
x_train = np.random.random((1000, 64,100))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100,64,100))
y_test = np.random.randint(2, size=(100, 1))
seq_length = 64
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
Epoch 1/10
1000/1000 [==============================] - 1s 996us/step - loss: 0.6983 - accuracy: 0.5090
Epoch 2/10
1000/1000 [==============================] - 0s 493us/step - loss: 0.6965 - accuracy: 0.4880
Epoch 3/10
1000/1000 [==============================] - 1s 513us/step - loss: 0.6976 - accuracy: 0.4870
Epoch 4/10
1000/1000 [==============================] - 1s 505us/step - loss: 0.6945 - accuracy: 0.4960
Epoch 5/10
1000/1000 [==============================] - 0s 495us/step - loss: 0.6939 - accuracy: 0.4990
Epoch 6/10
1000/1000 [==============================] - 1s 530us/step - loss: 0.6951 - accuracy: 0.5040
Epoch 7/10
1000/1000 [==============================] - 1s 592us/step - loss: 0.6949 - accuracy: 0.5090
Epoch 8/10
1000/1000 [==============================] - 1s 647us/step - loss: 0.6967 - accuracy: 0.5140
Epoch 9/10
1000/1000 [==============================] - 1s 756us/step - loss: 0.6941 - accuracy: 0.5040
Epoch 10/10
1000/1000 [==============================] - 1s 888us/step - loss: 0.6948 - accuracy: 0.4990
100/100 [==============================] - 0s 2ms/step基于栈式 LSTM 的序列分类
在这个模型中,我们将 3 个 LSTM 层叠在一起,使模型能够学习更高层次的时间表示。
前两个 LSTM 返回完整的输出序列,但最后一个只返回输出序列的最后一步,从而降低了时间维度(即将输入序列转换成单个向量)。
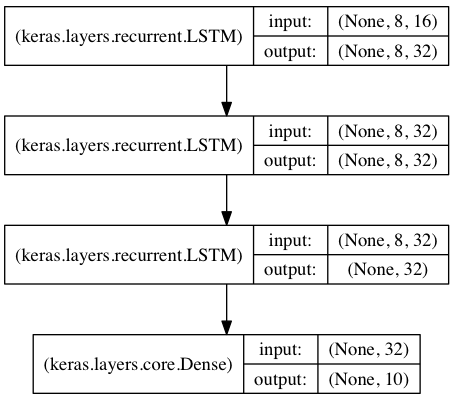
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# 期望输入数据尺寸: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # 返回维度为 32 的向量序列
model.add(LSTM(32, return_sequences=True)) # 返回维度为 32 的向量序列
model.add(LSTM(32)) # 返回维度为 32 的单个向量
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 生成虚拟训练数据
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# 生成虚拟验证数据
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))
Train on 1000 samples, validate on 100 samples Epoch 1/5 1000/1000 [==============================] - 4s 4ms/step - loss: 11.9861 - accuracy: 0.0930 - val_loss: 12.1464 - val_accuracy: 0.0900 Epoch 2/5 1000/1000 [==============================] - 1s 699us/step - loss: 12.7460 - accuracy: 0.0900 - val_loss: 12.4198 - val_accuracy: 0.0900 Epoch 3/5 1000/1000 [==============================] - 1s 669us/step - loss: 12.9024 - accuracy: 0.0900 - val_loss: 12.4619 - val_accuracy: 0.0900 Epoch 4/5 1000/1000 [==============================] - 1s 641us/step - loss: 12.9497 - accuracy: 0.0900 - val_loss: 12.4803 - val_accuracy: 0.0900 Epoch 5/5 1000/1000 [==============================] - 1s 627us/step - loss: 12.9648 - accuracy: 0.0900 - val_loss: 12.4982 - val_accuracy: 0.0900
"stateful" 渲染的的栈式 LSTM 模型
有状态 (stateful) 的循环神经网络模型中,在一个 batch 的样本处理完成后,其内部状态(记忆)会被记录并作为下一个 batch 的样本的初始状态。这允许处理更长的序列,同时保持计算复杂度的可控性。
你可以在 FAQ 中查找更多关于 stateful RNNs 的信息。
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# 期望输入数据尺寸: (batch_size, timesteps, data_dim)
# 请注意,我们必须提供完整的 batch_input_shape,因为网络是有状态的。
# 第 k 批数据的第 i 个样本是第 k-1 批数据的第 i 个样本的后续。
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 生成虚拟训练数据
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# 生成虚拟验证数据
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))
Train on 320 samples, validate on 96 samples Epoch 1/5 320/320 [==============================] - 2s 7ms/step - loss: 11.7630 - accuracy: 0.0906 - val_loss: 12.4489 - val_accuracy: 0.0625 Epoch 2/5 320/320 [==============================] - 0s 880us/step - loss: 12.7446 - accuracy: 0.1063 - val_loss: 13.0136 - val_accuracy: 0.0625 Epoch 3/5 320/320 [==============================] - 0s 972us/step - loss: 13.1789 - accuracy: 0.1063 - val_loss: 13.2969 - val_accuracy: 0.0625 Epoch 4/5 320/320 [==============================] - 0s 1ms/step - loss: 13.3936 - accuracy: 0.1063 - val_loss: 13.4358 - val_accuracy: 0.0625 Epoch 5/5 320/320 [==============================] - 0s 1ms/step - loss: 13.4951 - accuracy: 0.1063 - val_loss: 13.4968 - val_accuracy: 0.0625
最后
以上就是舒服樱桃最近收集整理的关于Sequential 顺序模型指引开始使用 Keras Sequential 顺序模型的全部内容,更多相关Sequential内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复