7.2 Chunking分块
The basic technique we will use for entity detection is chunking, which segments and labels multi-token sequences as illustrated inFigure 7.2. The smaller boxes show the word-level tokenization and part-of-speech tagging, while the large boxes show higher-level chunking. Each of these larger boxes is called a chunk. Like tokenization, which omits whitespace, chunking usually selects a subset of the tokens(标记的子集). Also like tokenization, the pieces produced by a chunker do not overlap in the source text.
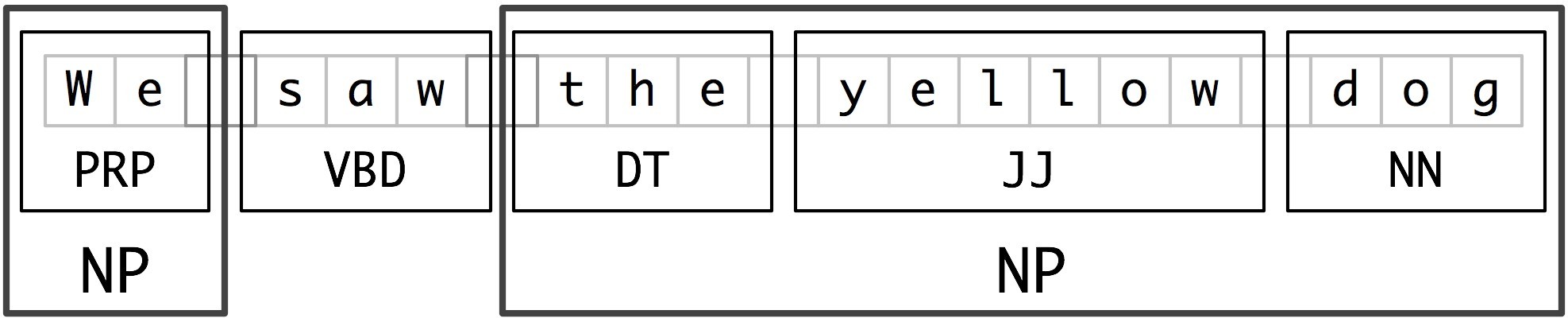
Figure 7.2: Segmentation and Labeling at both the Token and Chunk Levels
In this section, we will explore chunking in some depth, beginning with the definition and representation of chunks. We will see regular expression and n-gram approaches to chunking, and will develop and evaluate chunkers using the CoNLL-2000 chunking corpus. We will then return inSection (5) and Section 7.6 to the tasks of named entity recognition and relation extraction.
Noun Phrase Chunking名词短语分块
(2) [ The/DT market/NN ] for/IN [ system-management/NN software/NN ] for/IN [ Digital/NNP ] [ 's/POS hardware/NN ] is/VBZ fragmented/JJ enough/RB that/IN [ a/DT giant/NN ] such/JJ as/IN [ Computer/NNP Associates/NNPS ] should/MD do/VB well/RB there/RB ./.
As we can see, NP-chunks are often smaller pieces than complete noun phrases. For example, the market for system-management software for Digital's hardware is a single noun phrase (containing two nested noun phrases), but it is captured in NP-chunks by the simpler chunk the market. One of the motivations for this difference is that NP-chunks are defined so as not to contain other NP-chunks. Consequently, any prepositional phrases(介词短语)or subordinate clauses(从句)that modify a nominal(名词性词)will not be included in the corresponding NP-chunk, since they almost certainly contain further noun phrases.
One of the most useful sources of information for NP-chunking is part-of-speech tags. This is one of the motivations for performing part-of-speech tagging in our information extraction system. We demonstrate this approach using an example sentence that has been part-of-speech tagged inExample 7.3. In order to create an NP-chunker, we will first define a chunk grammar(分块语法), consisting of rules that indicate how sentences should be chunked. In this case, we will define a simple grammar with a single regular-expression rule. This rule says that an NP chunk should be formed whenever the chunker finds an optional determiner (DT) followed by any number of adjectives (JJ) and then a noun (NN). Using this grammar, we create a chunk parser, and test it on our example sentence. The result is a tree, which we can either print, or display graphically.
>>>sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),
...("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
>>>grammar = "NP: {
?*}">>>cp = nltk.RegexpParser(grammar)
>>>result = cp.parse(sentence)
>>>printresult
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
>>>result.draw()
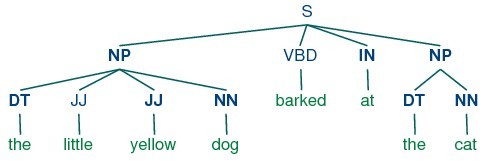
Figure 7.3: Example of a Simple Regular Expression Based NP Chunker.
Tag Patterns标签
another/DT sharp/JJ dive/NN
trade/NN figures/NNS
any/DT new/JJ policy/NN measures/NNS
earlier/JJR stages/NNS
Panamanian/JJ dictator/NN Manuel/NNP Noriega/NNP
We can match these noun phrases using a slight refinement of the first tag pattern above, i.e.
?*+. This will chunk any sequence of tokens beginning with an optional determiner, followed by zero or more adjectives of any type (including relative adjectives like earlier/JJR), followed by one or more nouns of any type. However, it is easy to find many more complicated examples which this rule will not cover:his/PRP$ Mansion/NNP House/NNP speech/NN
the/DT price/NN cutting/VBG
3/CD %/NN to/TO 4/CD %/NN
more/JJR than/IN 10/CD %/NN
the/DT fastest/JJS developing/VBG trends/NNS
's/POS skill/NN
Note
Your Turn:Try to come up with tag patterns to cover these cases. Test them using the graphical interface nltk.app.chunkparser(). Continue to refine your tag patterns with the help of the feedback given by this tool.
Chunking with Regular Expressions用正则表达式分块
To find the chunk structure for a given sentence, the RegexpParser chunker begins with a flat structure in which no tokens are chunked. The chunking rules are applied in turn, successively updating the chunk structure. Once all of the rules have been invoked, the resulting chunk structure is returned.
Example 7.4 shows a simple chunk grammar consisting of two rules. The first rule matches an optional determiner or possessive pronoun(所有格代名词), zero or more adjectives, then a noun. The second rule matches one or more proper nouns(专有名词). We also define an example sentence to be chunked, and run the chunker on this input.
grammar = r"""
NP: {
?*} #chunk determiner/possessive, adjectives and nouns{+}# chunk sequences of proper nouns
"""
cp = nltk.RegexpParser(grammar)
sentence = [("Rapunzel", "NNP"), ("let", "VBD"), ("down", "RP"),
("her", "PP$"), ("long", "JJ"), ("golden", "JJ"), ("hair", "NN")]
>>>printcp.parse(sentence)
(S
(NP Rapunzel/NNP)
let/VBD
down/RP
(NP her/PP$ long/JJ golden/JJ hair/NN))
Example 7.4 (code_chunker1.py): Figure 7.4: Simple Noun Phrase Chunker
Note
The $ symbol is a special character in regular expressions, and must be backslash escaped in order to match the tag PP$.在正则表达式中$是一个特殊符号,必须使用转义符来匹配PP$标志。
If a tag pattern matches at overlapping locations, the leftmost match takes precedence(最左边匹配拥有优先). For example, if we apply a rule that matches two consecutive nouns to a text containing three consecutive nouns, then only the first two nouns will be chunked:
>>>nouns = [("money", "NN"), ("market", "NN"), ("fund", "NN")]
>>>grammar = "NP: {} # Chunk two consecutive nouns"
>>>cp = nltk.RegexpParser(grammar)
>>>printcp.parse(nouns)
(S (NP money/NN market/NN) fund/NN)
Once we have created the chunk for money market, we have removed the context that would have permitted fund to be included in a chunk. This issue would have been avoided with a more permissive(宽容的)chunk rule, e.g. NP: {+}.
Note
We have added a comment to each of our chunk rules. These are optional; when they are present, the chunker prints these comments as part of its tracing output.
Exploring Text Corpora探索文本语料库
In Section 5.2 we saw how we could interrogate(询问)a tagged corpus to extract phrases matching a particular sequence of part-of-speech tags. We can do the same work more easily with a chunker, as follows:
>>>cp = nltk.RegexpParser('CHUNK: {}')
>>>brown = nltk.corpus.brown
>>>forsent in brown.tagged_sents():
...tree = cp.parse(sent)
...for subtree in tree.subtrees():
...if subtree.node == 'CHUNK': print subtree
...
(CHUNK combined/VBN to/TO achieve/VB)
(CHUNK continue/VB to/TO place/VB)
(CHUNK serve/VB to/TO protect/VB)
(CHUNK wanted/VBD to/TO wait/VB)
(CHUNK allowed/VBN to/TO place/VB)
(CHUNK expected/VBN to/TO become/VB)
...
(CHUNK seems/VBZ to/TO overtake/VB)
(CHUNK want/VB to/TO buy/VB)
Note
Your Turn:Encapsulate(封装)the above example inside a function find_chunks() that takes a chunk string like "CHUNK: {}" as an argument. Use it to search the corpus for several other patterns, such as four or more nouns in a row, e.g. "NOUNS: {{4,}}"
Chinking分块
[ the/DT little/JJ yellow/JJ dog/NN ] barked/VBD at/IN [ the/DT cat/NN ]
Chinking is the process of removing a sequence of tokens from a chunk. If the matching sequence of tokens spans(贯穿)an entire chunk, then the whole chunk is removed; if the sequence of tokens appears in the middle of the chunk, these tokens are removed, leaving two chunks where there was only one before. If the sequence is at the periphery(外围)of the chunk, these tokens are removed, and a smaller chunk remains. These three possibilities are illustrated in
` ` Entire chunk Middle of a chunk End of a chunk Input [a/DT little/JJ dog/NN] [a/DT little/JJ dog/NN] [a/DT little/JJ dog/NN]
Operation Chink "DT JJ NN" Chink "JJ" Chink "NN"
Pattern }DT JJ NN{ }JJ{ }NN{
Output a/DT little/JJ dog/NN [a/DT] little/JJ [dog/NN] [a/DT little/JJ] dog/NN
In Example 7.5, we put the entire sentence into a single chunk, then excise the chinks.
grammar = r"""
NP:
{<.*>+} # Chunk everything
}+{ # Chink sequences of VBD and IN
"""
sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),
("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
cp = nltk.RegexpParser(grammar)
>>>printcp.parse(sentence)
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
Example 7.5 (code_chinker.py): Figure 7.5: Simple Chinker
Representing Chunks: Tags vs Trees表示块:标签与树
As befits their intermediate(中间的)status between tagging and parsing (Chapter 8), chunk structures can be represented using either tags or trees. The most widespread file representation uses IOB tags(IOB标记). In this scheme, each token is tagged with one of three special chunk tags, I (inside), O (outside), or B (begin). A token is tagged as B if it marks the beginning of a chunk. Subsequent tokens within the chunk are tagged I. All other tokens are tagged O. The B and I tags are suffixed with the chunk type, e.g. B-NP, I-NP. Of course, it is not necessary to specify a chunk type for tokens that appear outside a chunk, so these are just labeled O. An example of this scheme is shown in

Figure 7.6: Tag Representation of Chunk Structures
IOB tags have become the standard way to represent chunk structures in files, and we will also be using this format. Here is how the information in Figure 7.6 would appear in a file:
We PRP B-NP
saw VBD O
the DT B-NP
little JJ I-NP
yellow JJ I-NP
dog NN I-NP
In this representation there is one token per line, each with its part-of-speech tag and chunk tag. This format permits us to represent more than one chunk type, so long as the chunks do not overlap. As we saw earlier, chunk structures can also be represented using trees. These have the benefit that each chunk is a constituent(组成)that can be manipulated directly. An example is shown in Figure 7.7.
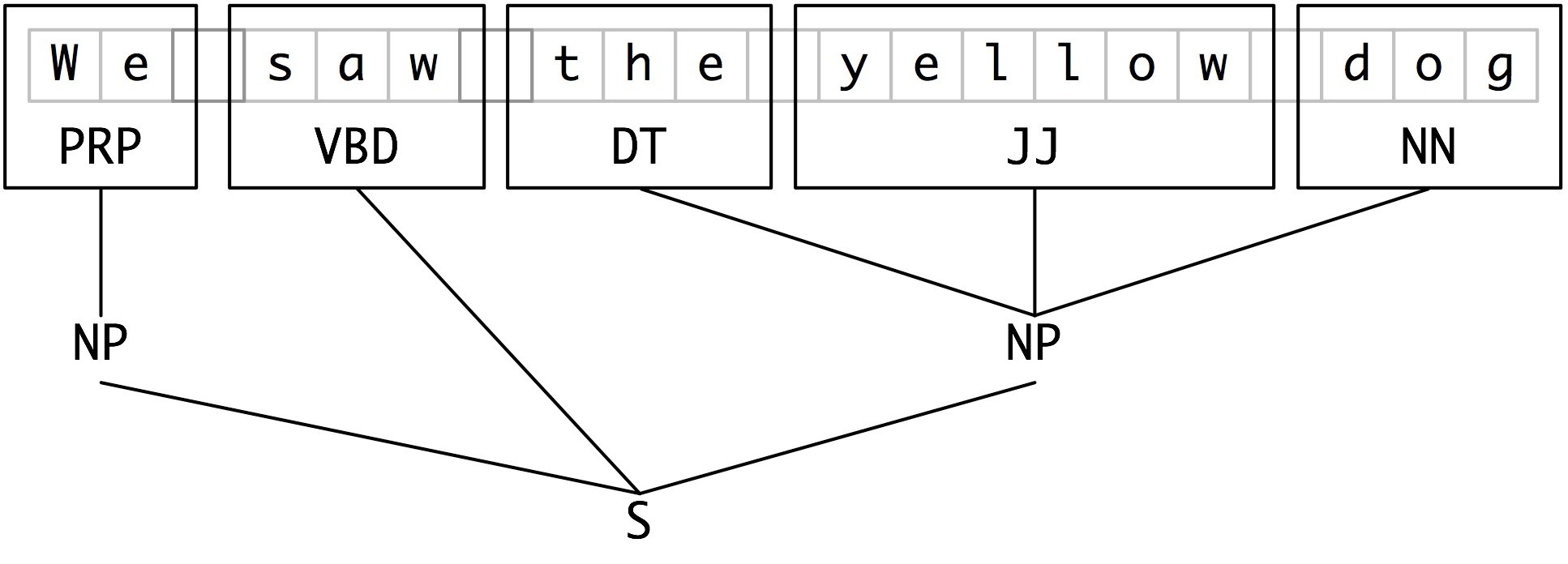
Figure 7.7: Tree Representation of Chunk Structures
Note
NLTK uses trees for its internal representation(内部表示)of chunks, but provides methods for reading and writing such trees to the IOB format.
最后
以上就是精明日记本最近收集整理的关于python分块处理功能_Python自然语言处理学习笔记(61):7.2 分块的全部内容,更多相关python分块处理功能_Python自然语言处理学习笔记(61):7.2内容请搜索靠谱客的其他文章。








发表评论 取消回复