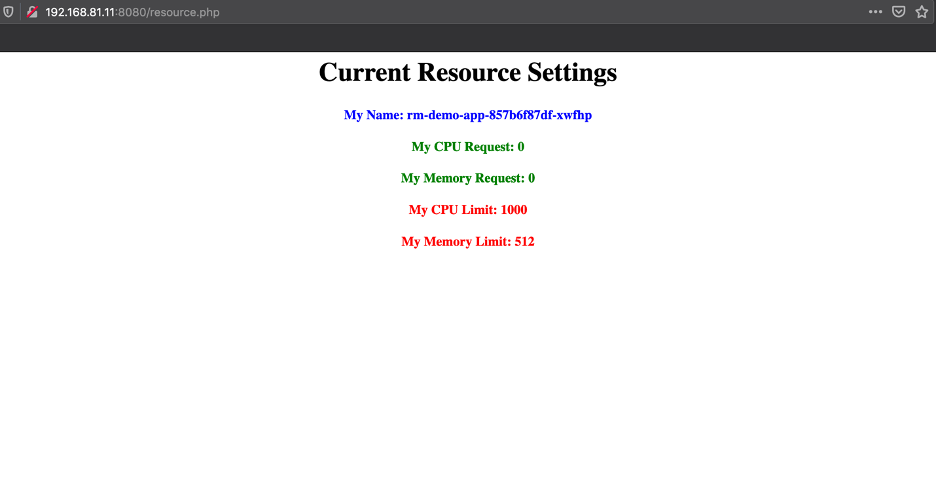
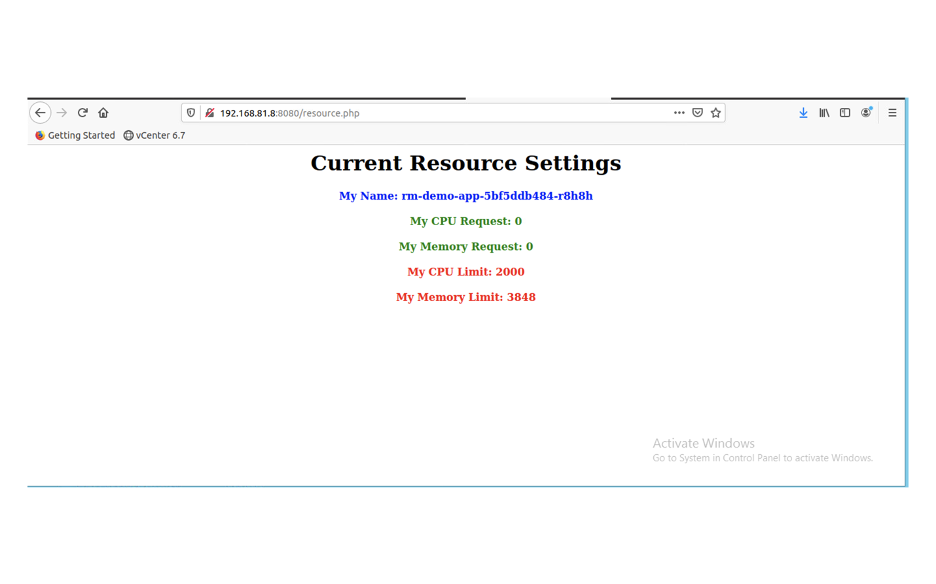
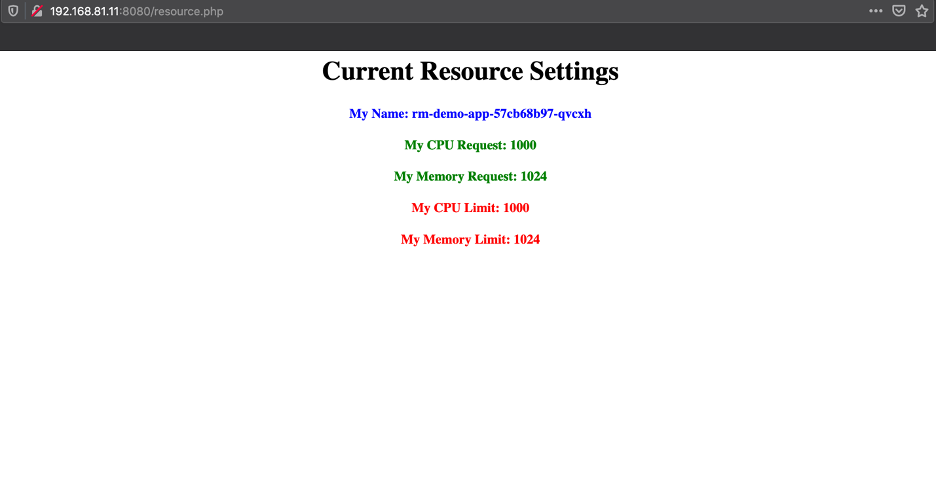
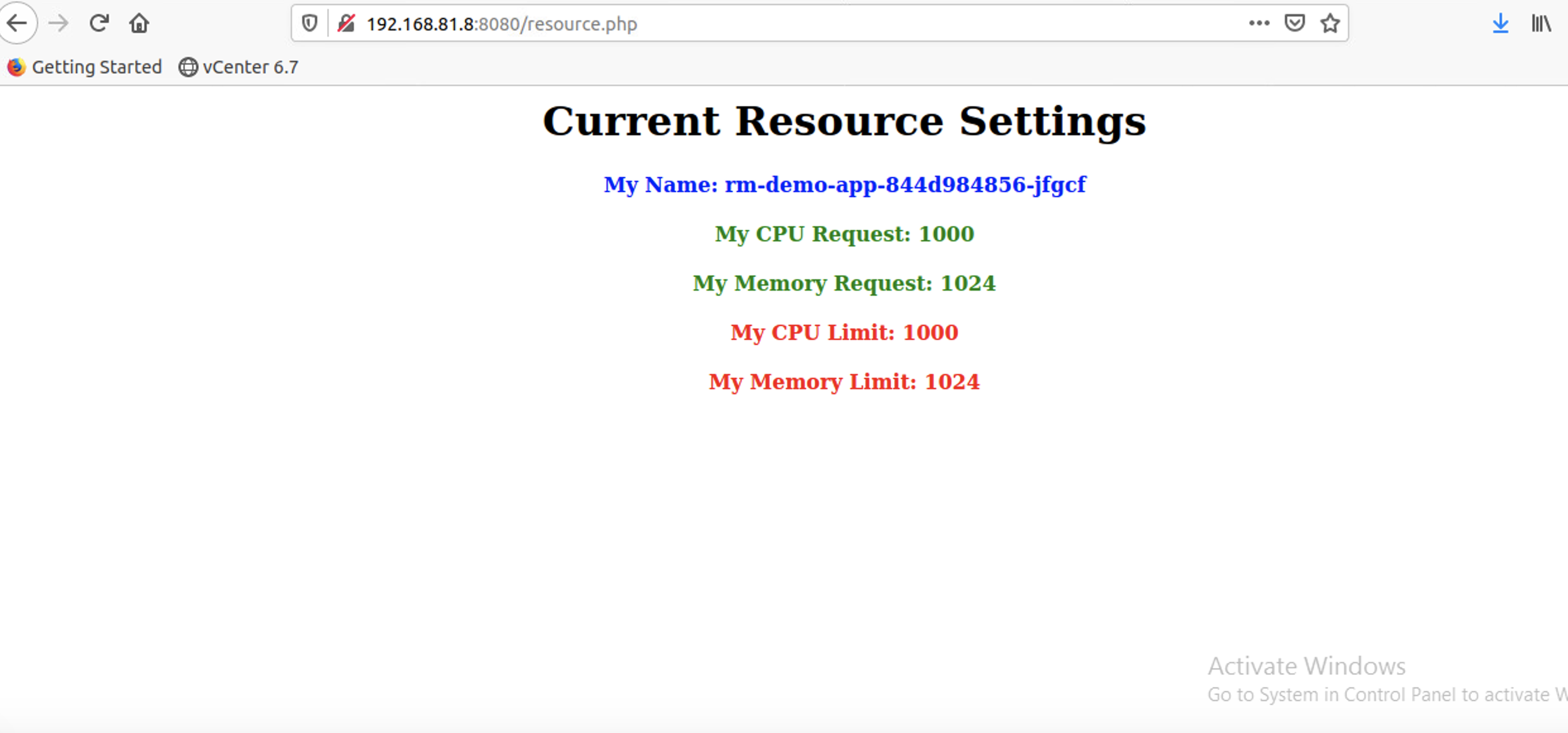
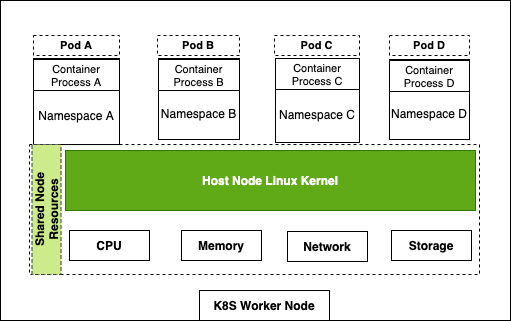
vsphere 混杂模式 Back in VMWorld 2019, VMware made an exciting announcement — Project Pacific — to bring the best of the proven enterprise virtualization platform vSphere and the defacto Container Orchestration engine Kubernetes into an integrated Modern Application Platform. The new platform, vSphere7 or commonly refers as vSphere with Kubernetes, is generally available since April 2020. 其他回在2019的VMworld,VMware的取得了令人振奋公告-项目区-把最好的成熟的企业虚拟化平台vSphere和事实上的集装箱业务流程引擎Kubernetes于一体的综合现代应用平台。 新平台vSphere7或通常称为带有Kubernetes的vSphere,自2020年4月开始普遍可用。 To keep up the real sense of Kubernetes is a “Platform Platform,” vSphere 7 with Kubernetes gives a Platform for its users to run multi form-factor modern workloads, say…Kubernetes Clusters (Tanzu Kubernetes Cluster Service), Container Workloads as Native vSphere Pods, and VMs. 为了保持Kubernetes的真正意义,它是一个“平台平台”,带有Kubernetes的vSphere 7为用户提供了一个平台,可以运行多种形式的现代工作负载,例如… Pod和VM。 The Kubernetes APIs gives additional flexibility for the vSphere Admins to define Name Space as a Unit of Management and provision it to the platform users to consume the resources via the Kubernetes declarative model. Kubernetes API为vSphere管理员提供了更大的灵活性,可以将名称空间定义为管理单位,并将其提供给平台用户以通过Kubernetes声明模型使用资源。 Since the new Construct called vSphere Pod, which gives the flexibility to run Kubernetes Native Workload (Container Pods) directly on Esxi, is a new kid in the block, it may be a good idea to explore its unique use cases. 由于名为vSphere Pod的新Constructor 具有灵活性,可以直接在Esxi上直接运行Kubernetes Native Workload(容器Pods) ,因此是一个新生事物,因此探索其独特的用例可能是个好主意。 In this Multi-Part Series, I am trying to declutter the Compute resource characteristics of vSphere Pods in vSphere with Kubernetes platform. Understanding the Compute resource patterns in vSphere Pods is one of the essential criteria to choose the right workloads to deploy as vSphere Pods. 在这个由多个部分组成的系列文章中,我试图在带有Kubernetes平台的vSphere中整理 vSphere Pods的Compute资源特征。 了解vSphere Pods中的Compute资源模式是选择正确的工作负载以部署为vSphere Pods的基本条件之一。 To analyze the characteristics of the Native vSphere Pod object of the vSphere with Kubernetes platform, I am impersonating a DevOps engineer than a vSphere Admin. As a DevOps persona, I walk through the resource model of the vSphere Pods to do some fact checks and recommend it as the best platform for specific containerized workloads. 为了分析带有Kubernetes平台的vSphere的Native vSphere Pod对象的特征,我模拟的是DevOps工程师而不是vSphere Admin。 作为DevOps角色,我将逐步介绍vSphere Pods的资源模型,以进行一些事实检查,并将其推荐为特定容器化工作负载的最佳平台。 What is a vSphere Pod? 什么是vSphere Pod? The all-new Object in vSphere with Kubernetes, which enables the users to run Containers natively on ESXi hosts, is called vSphere Native Pod, a.k.a vSphere Pod. vSphere中具有Kubernetes的全新对象(使用户能够在ESXi主机上本地运行容器)称为vSphere Native Pod,又称为vSphere Pod。 In a nutshell, vSphere Pod is a virtual machine that is highly optimized to boot a Linux kernel — Container Runtime Executive (CRX) to run containers. The CRX agent includes only just enough para-virtualized devices like vSCSI and VMXNET3. During the Pod initialization, the super-thin `kernel` (CRX) does a fast and secure boot process. After the CRX initialization. the containers, part of the Pod, will run in quick succession 简而言之,vSphere Pod是经过高度优化以启动Linux内核的虚拟机- 容器运行时执行程序(CRX)以运行容器。 CRX代理仅包含足够的半虚拟设备,例如vSCSI和VMXNET3。 在Pod初始化期间,超薄内核(CRX)进行了快速而安全的启动过程。 在CRX初始化之后。 作为Pod一部分的容器将快速连续运行 Fig:1 vSphere Pod 图:1 vSphere Pod Considering the objective of the article, doing a quick cut to dissect the compute resource characteristic of the vSphere Pod. You may follow the referral URLs for a deep dive into vSphere Pod internals. 考虑到本文的目的,请快速剖析vSphere Pod的计算资源特征。 您可以按照引荐URL深入了解vSphere Pod内部。 What is the default resource allocation of a vSphere Pod? vSphere Pod的默认资源分配是什么? Let’s take the Kubernetes native way to check the compute resources `visible` from the Containers is using the Kubernetes downwardAPIs. 让我们以Kubernetes土办法检查计算资源`从容器visible`使用Kubernetes downwardAPI秒。 I created a tiny (also a bit crude!!!) `PHP web app,` which could display its compute resource Request and Limits from the downward API. 我创建了一个很小的(也有点粗糙!!)PHP Web应用程序,它可以从向下的API显示其计算资源“ 请求和限制 ”。 Requests are what the Container is guaranteed while scheduling it to a node. Limit limits the Container from goes above a configurable value of the resources. 请求是容器在计划到节点时所保证的。 限制限制容器从高于资源的可配置值开始。 Since the Test Pod is a single Container Pod, the resource values are quite easy to correlate as the Pod resource. 由于测试Pod是单个容器Pod,因此资源值很容易与Pod资源相关联。 CPU and Memory resource `request` and `limit` parameters of the Container can get via the following downward API `resourceField Ref.’ 容器的CPU和内存资源“ request”和“ limit”参数可以通过以下向下的API“ resourceField Ref。”获得。 . requests.cpu 。 request.cpu . requests.memory 。 request.memory . limits.cpu 。 Limits.cpu . limits.memory 。 限制记忆 The data from the downwardAPIs can consume as an environment variable or as downward API volume inside the Pod. 来自DownwardAPI的数据可以作为环境变量或Pod内部的向下API卷使用。 Scenario 1: 方案1: In the first scenario, the test app deploys as a vSphere Pod and has no custom resource request or limit configured. It means the Container can use the default resources allocated to the vSphere Pod. 在第一种情况下,测试应用程序将部署为vSphere Pod,并且未配置自定义资源请求或限制。 这意味着容器可以使用分配给vSphere Pod的默认资源。 Since each of the vSphere Pod has its own `kernel,` to schedule the resources between its processes, the Pod’s resource limit is the limit of the resources the Containers of the Pod can consume. 由于每个vSphere Pod都有自己的“内核”以在其进程之间调度资源,因此Pod的资源限制是Pod的容器可以消耗的资源的限制。 The following command will deploy the test application in a namespace, `vsphere-pod-resource-test`: ( What a meaningful name!!!) 以下命令将测试应用程序部署在名称空间“ vsphere-pod-resource-test”中:(真有意义!!!) kubectl create -f https://raw.githubusercontent.com/emailtovinod/vsphere-pod-resource/master/resource-test-app-deploy.yaml -n vsphere-pod-resource-test kubectl创建-f https://raw.githubusercontent.com/emailtovinod/vsphere-pod-resource/master/resource-test-app-deploy.yaml -n vsphere-pod-resource-test To access the Application externally using the browser, use the following command to create a service of type `loadbalancer`: 要使用浏览器从外部访问应用程序,请使用以下命令创建类型为“ loadbalancer”的服务: kubectl create -f https://raw.githubusercontent.com/emailtovinod/vsphere-pod-resource/master/resource-test-app-svc.yaml -n vsphere-pod-resource-test kubectl创建-f https://raw.githubusercontent.com/emailtovinod/vsphere-pod-resource/master/resource-test-app-svc.yaml -n vsphere-pod-resource-test Find the IP of the loadbalancer service : 找到负载均衡器服务的IP: kubectl get svc -n vsphere-pod-resource-test kubectl获取svc -n vsphere-pod-resource-test The test Application has the necessary instrumentation to display the resources allocated to the Pod via the URL: 测试应用程序具有必要的工具来显示通过URL分配给Pod的资源: http://<loadbalancer ip>/resource.php http:// <loadbalancer ip> /resource.php Fig:2 vSphere Pod Resources 图:2 vSphere Pod资源 As you can see here, since there is no `resource request,` the value of CPU and Memory values are showing as Zero. 如您所见,由于没有“资源请求”,因此CPU和内存的值显示为零。 vSphere Pod default value of CPU is `1000 millicores` ( 1 Core) or in plain, 1CPU Core, and the memory limit is 512 MB. If there is no custom/default resource specification for the Containers, it is the limit of the resources the containerized processes run as the vSphere Pod could consume. vSphere Pod CPU的默认值为“ 1000 millicores”(1个核心)或普通的1CPU核心,内存限制为512 MB。 如果没有针对容器的自定义/默认资源规范,则这是容器化进程运行的资源的限制,因为vSphere Pod可能会消耗这些资源。 Scenario 2: 方案2: Let us do a second scenario to check the default resource allocation of a Pod deployed in a Kubernetes Conformant cluster. 让我们做第二种情况来检查在Kubernetes Conformant集群中部署的Pod的默认资源分配。 Create an application deployment using the same manifest in a Tanzu Kubernetes Cluster (TKC) service or any other conformant Kubernetes Cluster. It provides us a clear distinction between the resource patterns of vSphere Pods and Pods running on a conformant cluster. 在Tanzu Kubernetes群集(TKC)服务或任何其他符合要求的Kubernetes群集中使用相同的清单创建应用程序部署。 它为我们明确区分了vSphere Pods的资源模式和在一致群集上运行的Pod的资源模式。 Follow the steps to deploy a test Application Pod in a Kubernetes Conformant cluster. 请按照以下步骤在Kubernetes Conformant群集中部署测试Application Pod。 Create a Namespace to deploy the Application: 创建一个名称空间来部署应用程序: kubectl create namespace pod-resource-test kubectl创建命名空间pod-resource-test The following command deploys the test Application: 以下命令部署测试应用程序: kubectl create -f https://raw.githubusercontent.com/emailtovinod/vsphere-pod-resource/master/resource-test-app-svc.yaml kubectl创建-f https://raw.githubusercontent.com/emailtovinod/vsphere-pod-resource/master/resource-test-app-svc.yaml Access the test application WebUI via the loadbalancer IP: 通过负载平衡器IP访问测试应用程序WebUI: http://<loadbalancer ip>/resource.php http:// <loadbalancer ip> /resource.php The following diagram shows the default resource of the Pod showing via the downward APIs of Tanzu Kubernetes Cluster. 下图显示了Pod的默认资源,该资源通过Tanzu Kubernetes Cluster的向下API进行显示。 Fig:3 Default Pod Resources 图:3默认Pod资源 As discussed earlier, there is no resource request for the Container, hence the value `0` for both CPU and Memory request. 如前所述,没有容器的资源请求,因此CPU和内存请求的值都为“ 0”。 But the CPU and Memory limit of the Pod in the conformant cluster is showing significantly higher value. If you carefully observe the limit values of CPU and Memory, you could find that these values are nothing but the total resources available in the Node on which the Pod is running. 但是,一致性群集中Pod的CPU和内存限制显示出明显更高的值。 如果您仔细观察CPU和内存的限制值,您会发现这些值不过是运行Pod的节点中可用的总资源。 What does that mean? Can the Pod use all the Node resources? The Obvious answer is `It depends.` 那是什么意思? Pod可以使用所有Node资源吗? 显而易见的答案是“ 取决于 。” To further declutter the `depends` clause, we need to go a little bit deeper. 为了进一步简化` depends`子句,我们需要更深入一些。 The Resource Quality of Service (QoS) 资源服务质量(QoS) Kubernetes’ resource allocation model classifies the resource Quality of Service (QoS) of the Pods deployed without any resources specification as `Best Effort.` `Best Effort` is the lowest priority resource QoS. Kubernetes的资源分配模型将没有任何资源规范的已部署Pod的资源服务质量(QoS)分类为“ 尽力而为 ”。“ 尽力而为 ”是优先级最低的资源QoS。 [Ref.https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/] [参考 https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/ ] The other two levels of resource QoS are `Burstable` and `Best Effort.` 资源QoS的其他两个级别是“ 突发 ”和“ 尽力而为” 。 The second most resource allocation priority goes to Burstable QoS, where the Containers have requests and optional limits (not equal to 0) specification. 第二大资源分配优先级分配给可突发 QoS,其中容器具有请求和可选限制 (不等于0)规范。 The highest resource priority — Guaranteed QoS` assigns to Container Pods deployed with limit and optional requests (not equal to 0) values. 最高的资源优先级-“ 保证的 QoS”分配给已部署的带有限制值和可选请求 (不等于0)值的Container Pod。 At a high level, the Completely Fair Scheduler (CFS ) C-Group bandwidth controller of the Linux kernel enforces the CPU `limit ` of the Containers. If the Node doesn’t have enough CPU resources to share with the Pods scheduled in it, Pods with `best effort QoS Class` are the ones suffer first from CPU throttling or even Pod eviction from the Node. 在较高级别上,Linux内核的完全公平调度程序 (CFS) C组带宽控制器强制执行容器的CPU“限制”。 如果节点没有足够的CPU资源与在其中安排的Pod共享,则具有“尽力而为QoS类”的Pod是首先受到CPU节流甚至从Node驱逐Pod的Pod。 If there is not enough memory to allocate to all the Pods scheduled in a node, the Applications running as `Best Effort Class` Pods get terminated by OOM (Out of Memory) killer. 如果没有足够的内存分配给节点中调度的所有Pod,则以“尽力而为类” Pods运行的应用程序将被OOM(内存不足)终止程序终止。 Linux CGroup and Application Behaviour Linux CGroup和应用程序行为 Linux Application containers rely on the Linux Kernel CGroup subsystem to manage the compute resources. The CGroup provides a unified interface for the Containers to limit, audit, and control the resources. It means the CGroup subsystem in Linux configures the resource allocation of the processes as per the Pod template specifications. Linux应用程序容器依靠Linux Kernel CGroup子系统 来管理计算资源 。 CGroup为容器提供了一个统一的界面,以限制,审核和控制资源。 这意味着Linux中的CGroup子系统根据Pod模板规范配置进程的资源分配。 Applications and CGroup Awareness 应用程序和CGroup意识 In the third scenario, update the vSphere Pod deployment with a custom resource parameter. 在第三种情况下,使用自定义资源参数更新vSphere Pod部署。 Scenario 3: 方案3: The following command will set a custom resource limit of 1 CPU and 1 GiB of Memory for the vSphere Pod: 以下命令将为vSphere Pod设置1个CPU和1 GiB内存的自定义资源限制: Note: If you are specifying only limit and no request values for the Containers, the limit assigns as request value too. 注意:如果您仅指定容器的限制,而没有指定请求值,则限制也将分配为请求值。 kubectl set resources deployment rm-demo-app limits=cpu=1,memory=1Gi -n vsphere-pod-resource-test kubectl设置资源部署rm-demo-app limit = cpu = 1,memory = 1Gi -n vsphere-pod-resource-test You may verify the values from the WebUI of the Application, which is displaying using the downwardAPIs. 您可以从应用程序的WebUI验证值,该WebUI使用downdownAPI显示。 Fig:4 vSphere Pod Resources with the Limit spec. 图:4具有限制规格的vSphere Pod资源。 Here we use Native Linux Tools to check the Compute Resources of the Pod to explore some interesting facts. 在这里,我们使用本机Linux工具检查Pod的计算资源,以探索一些有趣的事实。 As you see in the earlier steps, hence the test Application Pod has only one Container, its resource Specification is equal to that of the Pod. 正如您在前面的步骤中看到的那样,因此测试应用程序Pod只有一个容器,其资源规格等于Pod的资源。 Use `nproc` and `free` commands to check the memory and CPU resources of the Container of the vSphere Pod: 使用nproc和free命令检查vSphere Pod容器的内存和CPU资源: You may see the following Output, showing the CPU and Memory resources of the vSphere Pod. 您可能会看到以下输出,显示了vSphere Pod的CPU和内存资源。 Fig 5: nproc command output from the vSphere Pod 图5:vSphere Pod的nproc命令输出 Fig 6: free command output from the vSphere Pod 图6:vSphere Pod的免费命令输出 You may note that the output of the Linux Native tools and the Application displayed via Kubernetes downwardAPI are the same as the values, we set as the Container Resource Limits. Since the test application Pod has only one Container, it is equal to the resource availability of the Containerized process. 您可能会注意到,通过Kubernetes downAPI显示的Linux Native工具和Application的输出与这些值相同,我们将其设置为Container Resource Limits 。 由于测试应用程序Pod仅具有一个容器,因此它等于容器化过程的资源可用性。 As the last scenario in the series go ahead and set the resource limit for Pod deployed in the conformant Kubernetes Cluster. 作为本系列的最后一个场景,继续并设置在一致的Kubernetes集群中部署的Pod的资源限制。 Scenario 4: 方案4: To check the resource behavior of the Pods running in the Conformant cluster, set a resource limit of 1 CPU and 1 GiB of Memory using the following command: 要检查在合格群集中运行的Pod的资源行为,请使用以下命令将资源限制设置为1 CPU和1 GiB内存: kubectl set resources deployment rm-demo-app limits=cpu=1,memory=1Gi -n pod-resource-test kubectl设置资源部署rm-demo-app limit = cpu = 1,memory = 1Gi -n pod-resource-test The command will update the Pod template and a new Pod will create. After a few seconds, the new resource values will appear in the test Application WebUI. 该命令将更新Pod模板,并创建一个新的Pod。 几秒钟后,新的资源值将出现在测试应用程序WebUI中。 Fig 7: Pod Resources with the Limit spec. 图7:具有“限制”规格的Pod资源。 As did with vSphere Pod, use native Linux tools `nproc` and `free` to check the CPU and Memory showing inside the Container 与使用vSphere Pod一样,使用本地Linux工具`nproc`和`free`检查容器中显示的CPU和内存。 Fig 8: nproc command output from the Pod 图8:从Pod输出的nproc命令 Fig 9: free command output from the vSphere Pod 图9:vSphere Pod的免费命令输出 Although we set the same resource parameters for the Container of the vSphere Pod and the Container of the Pod running in the Conformant cluster, nproc and free Commands showing 2CPU and 3947 MiB of Memory, respectively for the later. Why are the Native Linux tools showing a vast difference between its output from vSphere Pod and the Pod in the Tanzu Kubernetes Cluster? Here comes the `CGroup Awareness` factor of the tools and applications running within a Linux Application Container. 尽管我们为在Conformant群集中运行的vSphere Pod的容器和Pod的容器设置了相同的资源参数,但稍后的 nproc和free命令分别显示2CPU和3947 MiB的内存 。 为什么本机Linux工具在vSphere Pod和Tanzu Kubernetes集群中的Pod的输出之间显示出巨大的差异? 这是Linux应用程序容器中运行的工具和应用程序的“ CGroup Awareness ”因素。 As you already know, Containers resource parameters configured via the Cgroup subsystem. Both `free ` and `nproc` using `Procfs` to find the information, not the Cgroup subsystem. For those who new to Linux, Procfs or “/proc” is a particular filesystem under Linux that presents process information and kernel parameters. 如您所知,Containers资源参数是通过Cgroup子系统配置的。 free和nproc都使用Procfs查找信息,而不是Cgroup子系统 。 对于Linux的新手来说,Procfs或“ / proc”是Linux下的一个特殊文件系统,它提供进程信息和内核参数。 Fig 10: K8S Node Resource Share Model 图10:K8S节点资源共享模型 In simple term, the tools which are not Cgroup_Aware( Since those tools came into existence much before Cgroup) give a skip to the Cgroup settings and show the total compute resources of the Node on which it currently scheduled. 简而言之,不是Cgroup_Aware的工具(由于这些工具早在Cgroup之前就已经存在),跳过了Cgroup设置,并显示了当前计划在其上的Node的总计算资源。 Is that the ` legacy tools` problem alone? 仅仅是“传统工具”问题吗? Not really. Consider a typical example of Java Virtual Machines (JVM)- Version 8 and below. While the JVM is running as Container or otherwise, JVM ergonomics sets the default values for the garbage collector, heap size, and runtime compiler. These values are consuming from Linux `sysfs` of the Node, not from the CGroup subsystem of Linux. 并不是的。 考虑Java虚拟机(JVM)-版本8及以下的典型示例。 当JVM以容器或其他方式运行时,JVM 人体工程学设置了垃圾收集器,堆大小和运行时编译器的默认值。 这些值是从节点的Linux的sysfs而不是Linux的CGroup子系统消耗的。 Sysfs is a bit modern and structured than procfs in which “sysfs” mounted on /sys as a way of exporting information from the kernel to various applications. Sysfs比procfs有点现代和结构化,在procfs中,“ sysfs”安装在/ sys上 ,是一种将信息从内核导出到各种应用程序的方法。 As a workaround, you can provide custom JVM settings as per the Container resource using Kubernetes API objects like Config Map and downWard APIs. ( Demonstration of it is not in the scope of this article). But the fact of the matter is, these additional requirements adds overhead in the deployment process. To avoid complexity, most of the production environments do not bother to adopt that pattern. 解决方法是,您可以使用Config Map和downWard API等Kubernetes API对象根据Container资源提供自定义JVM设置。 (它的演示不在本文的范围之内)。 但事实是,这些额外的要求增加了部署过程的开销。 为了避免复杂性,大多数生产环境都不会采用这种模式。 But the caveat here is, even though JVM configures its default values as per the resource information fetch from sysfs, the Linux Kernel resource scheduler will enforce the compute resource parameters allocated to the Container using CGroup subsystem. It commonly leads to frequent `OOM` errors in the application execution environment. Even worse, the cluster Operators end up in Over allocation of resources to the Container to mitigate the OOM errors. 但是需要注意的是,即使JVM根据从sysfs获取的资源信息配置其默认值,Linux内核资源调度程序也将使用CGroup 子系统 强制执行分配给Container的计算资源参数 。 通常会在应用程序执行环境中导致频繁的“ OOM”错误。 更糟糕的是,集群操作员最终会在过度分配资源到容器中以减轻OOM错误。 How vSphere Pod helps here? vSphere Pod如何为您提供帮助? As we observed, since there is a dedicated Linux Kernel to manage, each of the vSphere Pods’ resource scheduling, the compute resource values reported via Linux sysfs and Procfs are the same as that of the total Compute resources configure using Linux CGroup. ( In case of multi-container pods, the sum of the resources specification of all its Containers provides the Pod’s resource). 正如我们所观察到的,由于有一个专用的Linux内核来管理,每个vSphere Pods的资源调度,通过Linux sysfs和Procfs报告的计算资源值与使用Linux CGroup配置的全部Compute资源的值相同 。 (如果是多容器吊舱,则其所有容器的资源说明的总和将提供吊舱的资源)。 It is a huge advantage for the SREs /DevOps engineers planning to run the non- CGroup aware application as Containers and manages them using Kubernetes APIs. Whenever a Critical workload has precious resource requirements, vSphere Pod is an ideal destination without the concerns of the CGroup based resource control model. It is apart from the other unique resource allocation characteristics of vSphere Pods like NUMA node placement etc. Probably a subject for another article. 对于计划将非CGroup感知的应用程序作为容器运行并使用Kubernetes API进行管理的SRE / DevOps工程师而言,这是一个巨大的优势。 每当关键工作负载有宝贵的资源需求时,vSphere Pod都是理想的目的地,而无需担心基于CGroup的资源控制模型 。 它与vSphere Pods的其他独特资源分配特性(例如NUMA节点放置等)不同 。 可能是另一篇文章的主题。 Conclusion 结论 The article’s objective is to demonstrate one of the resource patterns of the vSphere Pod and how it makes it an idle solution for some of the Workloads. 本文的目的是演示vSphere Pod的一种资源模式,以及如何使它成为某些工作负载的空闲解决方案。 Now, you may ask, Well, Is it an `Anti-Pattern` of sort for some other workloads? You guessed it, right !!! 现在,您可能会问,嗯,这是否是针对其他一些工作负载的“反模式”? 你猜对了! If you look at the default minimum resource allocation of the vSphere Pod, it is 1 CPU and 512 MB of Memory. ( Not considering the storage aspect here). At least in the current version of the platform, though you can configure the default CPU and Memory values for the container, the vSphere Pod level resources cannot set less than the default ones. 如果查看vSphere Pod的默认最小资源分配,则为1 CPU和512 MB内存 。 (这里不考虑存储方面)。 至少在平台的当前版本中,尽管您可以为容器配置默认的CPU和内存值,但是vSphere Pod级别的资源设置不能小于默认值。 vSphere Pods only supports increasing the values higher than the default one using the resource request and limits. You may notice that the defaults compute resources of the vSphere Pods turn out to be over-provisioning for most of the Cloud Native stateless workloads and could easily overshoot the `resource budget` of the cluster. vSphere Pods仅支持使用资源请求和限制将值增加到高于默认值 。 您可能会注意到,对于大多数Cloud Native无状态工作负载,vSphere Pods的默认计算资源被过度配置,并且很容易超出集群的“资源预算”。 Here comes the flexibility of `vSphere with Kubernetes` platform. To run more optimized Cloud Native workloads and the Developer Environments, you can deploy Tanzu Kubernetes Cluster (TKC) Services — a conformant Kubernetes cluster — in a Supervisor cluster Namespace and use it side by side with the vSphere Pods. 这是vSphere with Kubernetes平台的灵活性。 要运行更多优化的Cloud Native工作负载和开发人员环境,您可以在Supervisor群集命名空间中部署Tanzu Kubernetes群集(TKC)服务(一个兼容的Kubernetes群集),并将其与vSphere Pods一起使用。 https://frankdenneman.nl/2020/03/06/initial-placement-of-a-vsphere-native-pod/ https://frankdenneman.nl/2020/03/06/initial-placement-of-a-vsphere-native-pod/ [Ref.https://kubernetes.io/docs/tasks/inject-data-application/downward-api-volume-expose-pod-information/] [参考 https://kubernetes.io/docs/tasks/inject-data-application/downward-api-volume-expose-pod-information/ ] https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ 翻译自: https://medium.com/@vinothecloudone/vsphere-pod-deep-dive-into-use-case-patterns-part-1-84888beff301 vsphere 混杂模式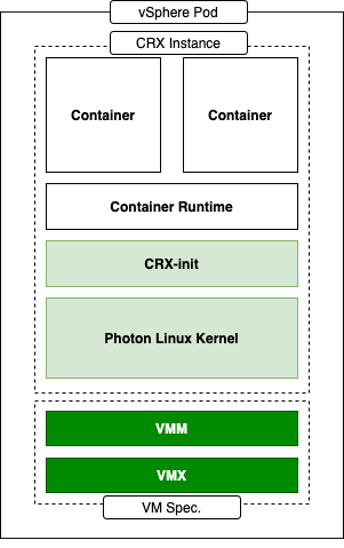




最后
以上就是精明日记本最近收集整理的关于vsphere 混杂模式_vSphere Pod:深入研究用例模式-第1部分的全部内容,更多相关vsphere内容请搜索靠谱客的其他文章。








发表评论 取消回复