第一部分 --- 构造递归下降分析器
1.在上面这个例子中则是子程序序A先调用子程序B,本程序结束完调用之后再返回来继续调用下一个符号
如果下一个符号是终结符的话那就直接进行匹配,不进行调用,匹配完后继续调用下一个符号
如果不是的话则调用这个非终结符对应的子程序,并重复步骤 1 
1.ADVANCE是一个字程序,作用是输入下一个符号
2.SYM则是指向当前输入的单词符号
1.一个非终结符的展开就等价于调用这个非终结符对应的语法分析子程序
1.一个非终结符对应的子程序就用这个非终结符本身来命名,比如非终结符A的子程序的命名就是A本身
2.上面这个设计中的Begin A ;B End 的意思是对于给定的候选式(假定候选式中有A和B,且A在B的前面(一般都将A设为候选式的开头,B设为候选式的结尾)),从候选式的A开始进行匹配,一直到匹配完B后结束匹配
3.如果待匹配字符属于非终结符的FEKKOW集合,且非终结符具有首符集合中具有空字医婆塞洛的候选式的话,我们就要选择这个候选式来进行匹配
选择空字候选式进行匹配在程序中的体现就是直接匹配成功,但是SYM不发生改变,ADVANCE不调用,而匹配程序继续往下执行
简单来说就是匹配程序执行一次什么都不做,然后继续执行后面的程序
第二部分 --- 梯度下降子程序设计示例

1.写出每个非终结符的递归下降子程序

1.绿色部分是在检验当前输入符号是不是属于非终结符的FELLOW集合
上面那种实现方式是在给定的字符不属于当前终结符的首字符集的时候,假设它属于当前非终结符的FELLOW集合,这就等价于假设这个字符是下一个非终结符 / 终结符的某个首字符集中的元素
到下一个非终结符进行匹配的时候,如果是的话那就正常匹配成功,如果不是的话就会匹配失败
此时采用上面那种方式和采用下面那种方式得到的结果都是一样的
1.主程序设计:读入字符,调用开始符号
2.主程序执行完毕之后,承接当前读取符号的SYM应该等于语句结束符号 ‘ # ’ ,如果不是的话就代表语法分析错误,返回REEOR
第三部分 --- 扩充的巴克斯范式和语法图
1.{α} --- α表示的是一个字符或者是字符串 , { α } 表示的则是阿尔法的闭包运算
2.上面那个任意重复0次至n次的意思是α的闭包运算可以任意重复0次到n次(重复0次就是不进行闭包运算,重复一次就是执行一次闭包运算)
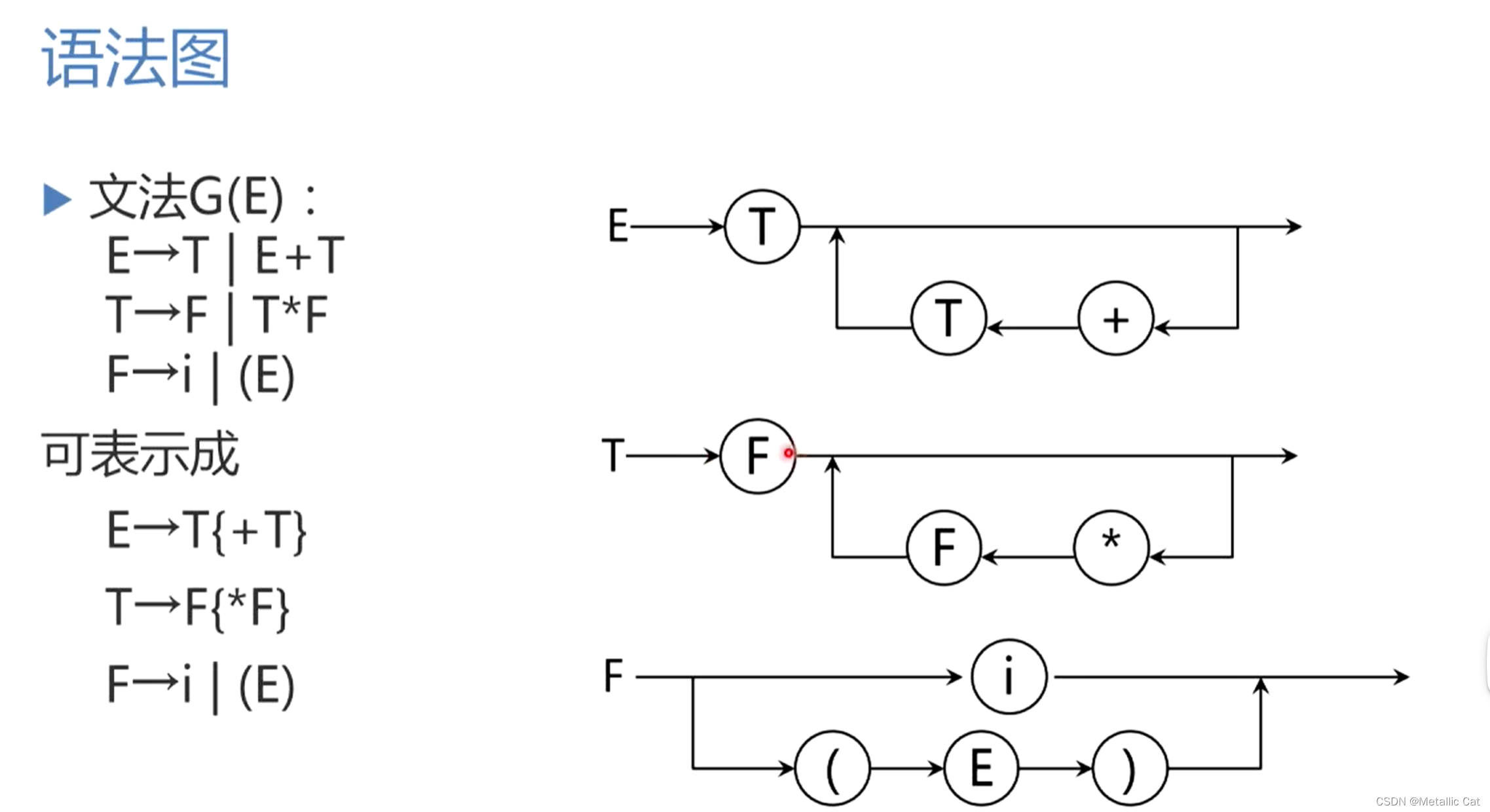
1.左边上面那种文法表示形式是没有进行扩充时的巴克斯范式的表示方式
2.下面这种文法表示形式就是进行了扩充后的巴克斯范式的表示方式
3.右边则是各个非终结符的语法树
4.对于E非终结符而言,如果递归能够停止的话,得到的字符串的开头字符一定是T,而T的后面一定跟着若干个 +T ---- 这种形式等价于 T然后后面跟着 +T的闭包 --- 其实就是扩充后的巴克斯范式的表示 --- 而扩充后的巴克斯范式的语法图就是上图右边那样
1.上图是扩充后的巴克斯范式的程序实现:
首先匹配一次开头符号,然后是开始进行“闭包运算”,闭包运算的过程是:如果现在输入的符号是 闭包运算中的第一个符号的话(进入循环),那就将闭包运算中第一个符号后面的字符依次进行匹配,匹配成功之后如果现在输入的符号的依然等于闭包运算的第一个符号的话,那就继续进行闭包运算(循环判断条件)
最后
以上就是忧虑夕阳最近收集整理的关于编译原理 --- 递归下降分析器的全部内容,更多相关编译原理内容请搜索靠谱客的其他文章。








发表评论 取消回复