C语言
实验环境:Visual Studio 2019
author:zoxiii
利用LL(1)分析表实现语法分析
- 1、实验内容
- 2、前期准备
- 2.1 LL(1)分析法分析过程
- 2.2 增设分析过程的相关变量和函数
- 3、分析过程
- 3.1 输入串分析过程
- 3.2 主程序分析
- 3.3 子程序分析
- 3.4 源代码
- 3.5 运行结果
- 4、遇到问题
1、实验内容
利用前面构造得到的LL(1)预测分析表,分析一个输入语句,输出具体的分析过程。
2、前期准备
2.1 LL(1)分析法分析过程
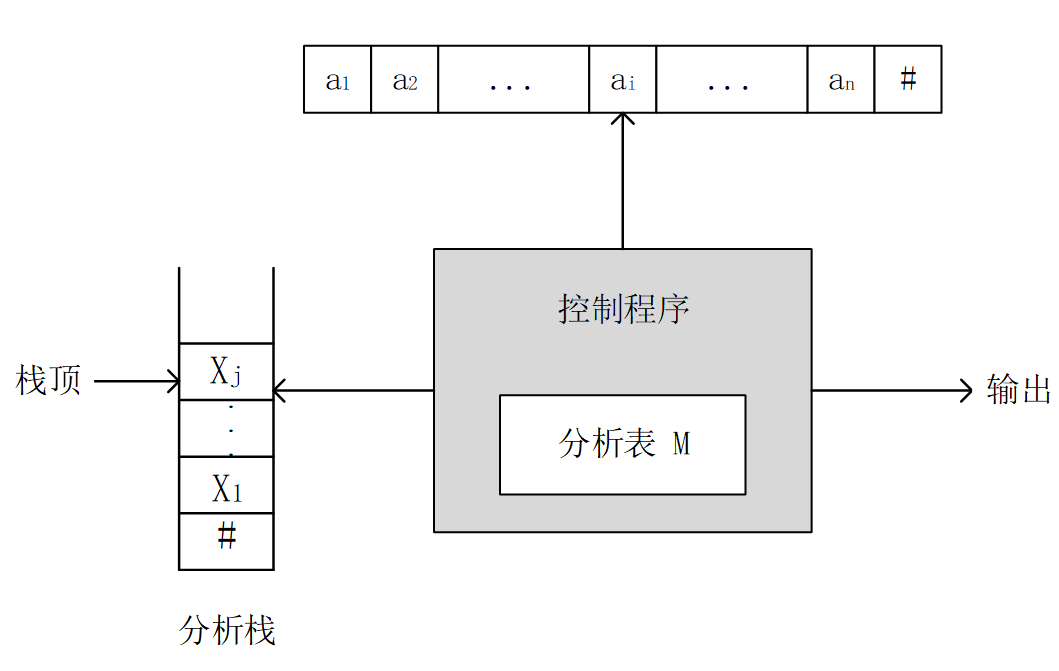
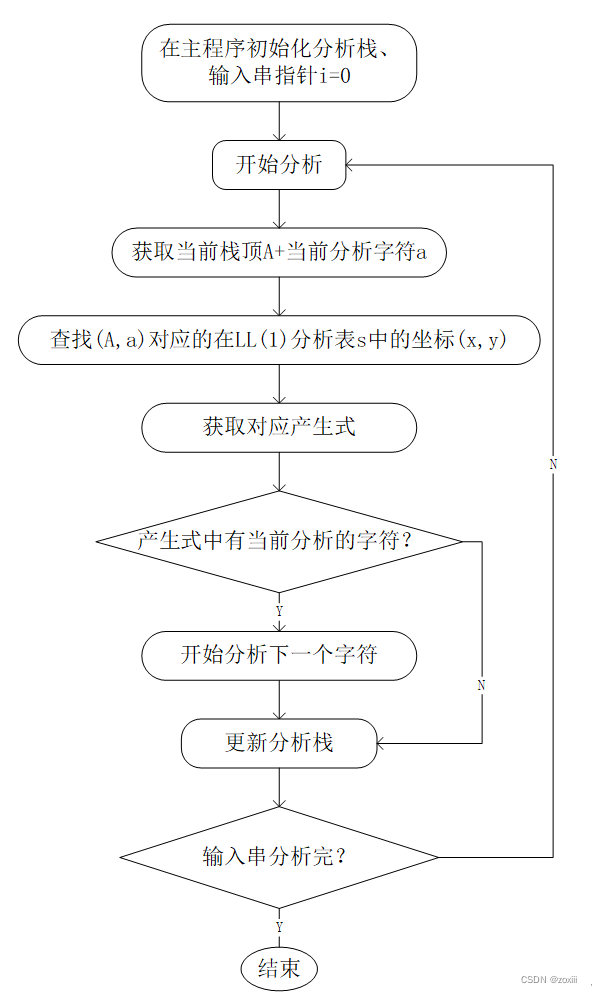
对图1所示的LL(1)分析器说明如下:
(1)输入串是待分析的符号串,它以界符“#”作为结束标志(注:#∈
V
T
V_T
VT但不是文法符号,是由分析程序自动添加的)。
(2)分析栈中存放分析过程中的文法符号。分析开始时栈底先放一个“#”,然后再压入文法的开始符号;当分析栈中仅剩“#”,输入串指针也指向串尾的“#”时,分析成功。
(3)分析表用一个二维数组
M
M
M表示,它概括了相应文法的全部信息。数组的每一行与文法的一个非终结符相关联,而每一列与文法的一个终结符或界符“#”相关联。对
M
[
A
,
a
]
M[A,a]
M[A,a]来说,
A
A
A为非终结符,而
a
a
a为终结符或“#”。分析表元素
M
[
A
,
a
]
M[A,a]
M[A,a]中的内容为一条关于
A
A
A的产生式,表明当
A
A
A面临输入符号
a
a
a时当前推到所应采用的候选式;当元素内容为空白(空白表示“出错标志”)时,则表明
A
A
A不应该面临这个输入符号
a
a
a,即输入串含有语法错误。
(4)控制程序根据分析栈顶符号
x
x
x和当前输入符号
a
a
a来决定分析器的动作:
- 1)若 x = a = x=a= x=a=“#”,则分析成功,分析器停止工作。
- 2)若 x = a ≠ x=a≠ x=a=“#”,即栈顶符号 x x x与当前扫描的输入符号 a a a、匹配;则将 x x x从栈顶弹出,输入指针指向下一个输入符号,继续对下一个字符进行分析。
- 3)若
x
x
x为一非终结字符
A
A
A,则查
M
[
A
,
a
]
M[A,a]
M[A,a];
①若 M [ A , a ] M[A,a] M[A,a]中为一个 A A A的产生式,则将 A A A自栈顶弹出,并将 M [ A , a ] M[A,a] M[A,a]中的产生式右部符号串按逆序逐一压入栈中;如果 M [ A , a ] M[A,a] M[A,a]中的产生式为 A − > ε A->ε A−>ε,则只将A自栈顶弹出。
②若 M [ A , a ] M[A,a] M[A,a]中为空,则发现语法错误,调用出错处理程序进行处理。
2.2 增设分析过程的相关变量和函数
对于分析输入串的过程参照实验三的递归下降分析法,使用string类型的变量来模拟栈,然后对其中的分析过程代码进行编写。
变量和函数如下:
string str, stackStr;//str:输入串、stackStr : 模拟栈
int i;//输入串的索引(指针)
string ch;//当前分析字符
vector<string> v;//字符串类型的向量(文法+分析栈)
vector<string> vnote;//说明调用的是哪一个产生式
int check();//验证是否已经到栈底
void push(string pre, string value);//将字符串存入输出栈
void analyze(); //分析文法的语句
void Print_analyze(); //打印分析过程
3、分析过程
3.1 输入串分析过程
根据书上的例子,我们选择实验三中递归下降分析法所选择的文法G[E]如下:
G[E]: E->TG
G->+TG|ε
T->FS
S->*FS|ε
F->(E)|i
按照实验四的方法分析可以得到对应的LL(1)分析表如下:
| # | ( | ) | * | + | i | |
|---|---|---|---|---|---|---|
| E | E->TG | E->TG | ||||
| F | F->(E) | F->i | ||||
| G | G->$ | G->$ | G->+TG | |||
| S | S->$ | S->$ | S->*FS | S->$ | ||
| T | T->FS | T->FS |
接下来根据LL(1)分析器的输入串分析方法,对输入串i+i*i进行分析过程如下表所示:
| 符号栈 | 当前输入符号 | 输入串 | 说明 |
|---|---|---|---|
| E# | i | +i*i# | 弹出栈顶E,M[E,i]中产生式逆序压栈 |
| TG# | i | +i*i# | 弹出栈顶T,M[T,i]中产生式逆序压栈 |
| FSG# | i | +i*i# | 弹出栈顶F,M[F,i]中产生式逆序压栈 |
| iSG# | i | +i*i# | 匹配,弹出i,读入+ |
| SG# | + | i*i# | 弹出栈顶S,M[S,+]中产生式逆序压栈 |
| G# | + | i*i# | 弹出栈顶G,M[G,+]中产生式逆序压栈 |
| +TG# | + | i*i# | 匹配,弹出+,读入i |
| TG# | i | *i# | 弹出栈顶T,M[T,i]中产生式逆序压栈 |
| FSG# | i | *i# | 弹出栈顶F,M[F,i]中产生式逆序压栈 |
| iSG# | i | *i# | 匹配,弹出i,读入* |
| SG# | * | i# | 弹出栈顶S,M[S,*]中产生式逆序压栈 |
| *FSG# | * | i# | 匹配,弹出*,读入i |
| FSG# | i | # | 弹出栈顶F,M[F,i]中产生式逆序压栈 |
| iSG# | i | # | 匹配,弹出i,读入# |
| SG# | # | 弹出栈顶S,M[S,3]中产生式逆序压栈 | |
| G# | # | 弹出栈顶G,M[G,#]中产生式逆序压栈 | |
| # | # | 匹配,分析成功 |
3.2 主程序分析
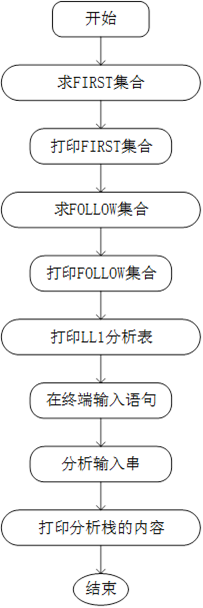
主程序在实验四的基础上增加了输入要分析的语句和分析的子函数过程。
其中要对输入串的指针、分析栈的内容进行初始化赋值,为后面的分析过程做准备。
因此得到主程序的流程图如下:
3.3 子程序分析
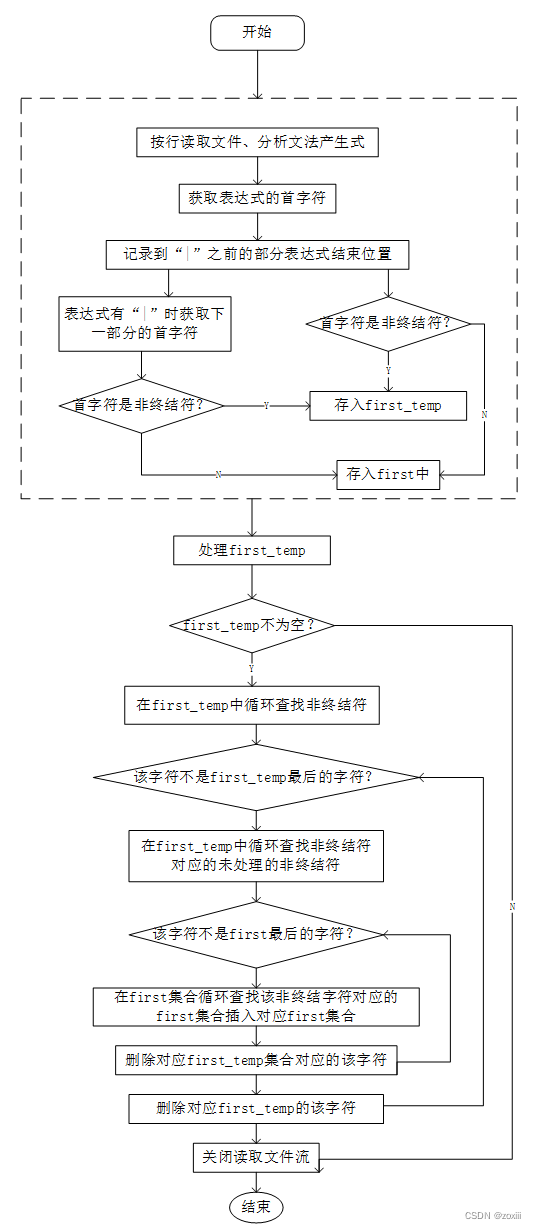
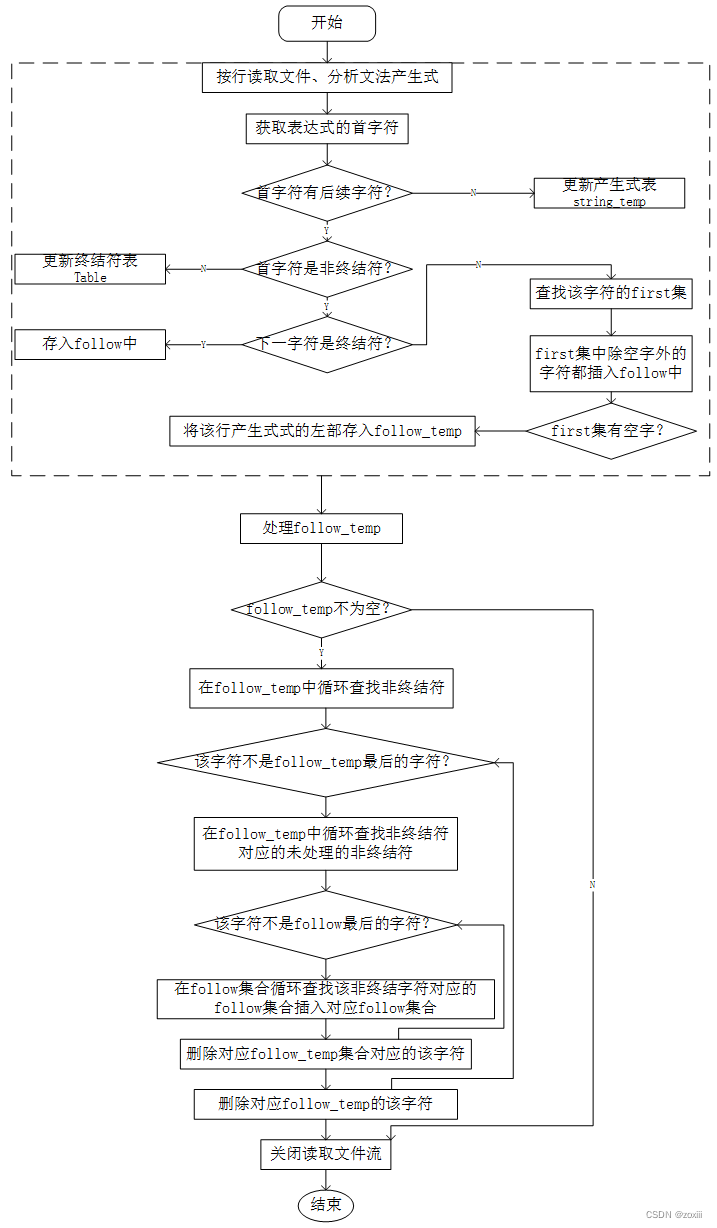
子程序中最重要的就是求解FIRST、FOLLOE集合的过程,其中求解FIRST集、FOLLOW集的流程图如下图所示。
另外对于LL(1)分析器对输入串分析的过程参照递归下降分析法的步骤,添加了压栈和检查输入串是否结束的两个辅助函数来控制分析栈的存储。
这两个函数的过程比较简单,主要是运用了下面这些C++自带的函数:
(1) substr(a,b):a:起始位置、b:字符串长度;
(2) str.find_first_of(ch):从str开始查找ch的位置;
(3) erase(idx, n):删除从位置idx开始的n个字符;
(4) v.push_back():将字符串压入向量v中;
3.4 源代码
✅⬇️代码传送地址
3.5 运行结果
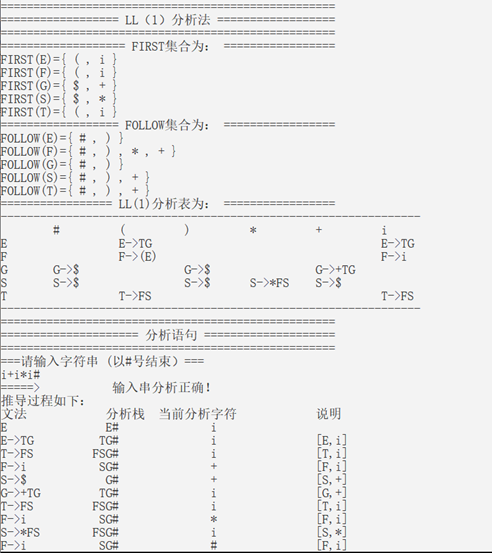
测试时首先使用前面分析过的文法和输入串进行测试的输出结果如下图所示,其中可以观察到相对于前面的分析过程分析栈的输出结果中都略去了匹配成功的那一步,直接进行了下一步的分析。
“说明”中的内容为每一步所选择的文法产生式在分析表中的位置。
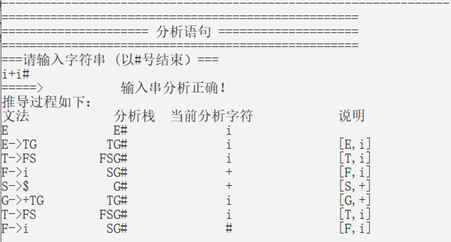
再对输入串i+i#进行分析,得到的结果如下图所示,其中分析步骤共有8步,得到了每一步分析栈中的内容。
而如果是不符合文法的语句,就没有任何输出结果,程序直接退出。
比如下图对输入串i-i进行分析,但该输入串并不符合该文法。

4、遇到问题
(1)对于更新后栈顶是终结符是,无法在预测分析表中查找到对应的文法表达式而出错,所以在压栈时对于栈顶进行处理,保证栈顶为非终结符,这样就不会出错了。
(2)使用string类型的二维数组来存储预测分析表,只能设置固定的大小,浪费了很多内存空间,使代码运行速度变慢。
最后
以上就是英勇火最近收集整理的关于【编译原理】【C语言】实验五:利用LL(1)分析表实现语法分析1、实验内容2、前期准备3、分析过程4、遇到问题的全部内容,更多相关【编译原理】【C语言】实验五内容请搜索靠谱客的其他文章。








发表评论 取消回复