Raft 是一种为了管理复制日志的一致性算法。
复制状态机
一致性算法是从复制状态机的背景下提出的。在这种方法中,一组服务器上的状态机产生相同状态的副本,并且在一些机器宕掉的情况下也可以继续运行。复制状态机在分布式系统中被用于解决很多容错的问题。例如,大规模的系统中通常都有一个集群领导者,像 GFS、HDFS 和 RAMCloud,十分典型的使用一个单独的复制状态机去管理领导选举和存储配置信息并且在领导人宕机的情况下也要存活下来。比如 Chubby 和 ZooKeeper。
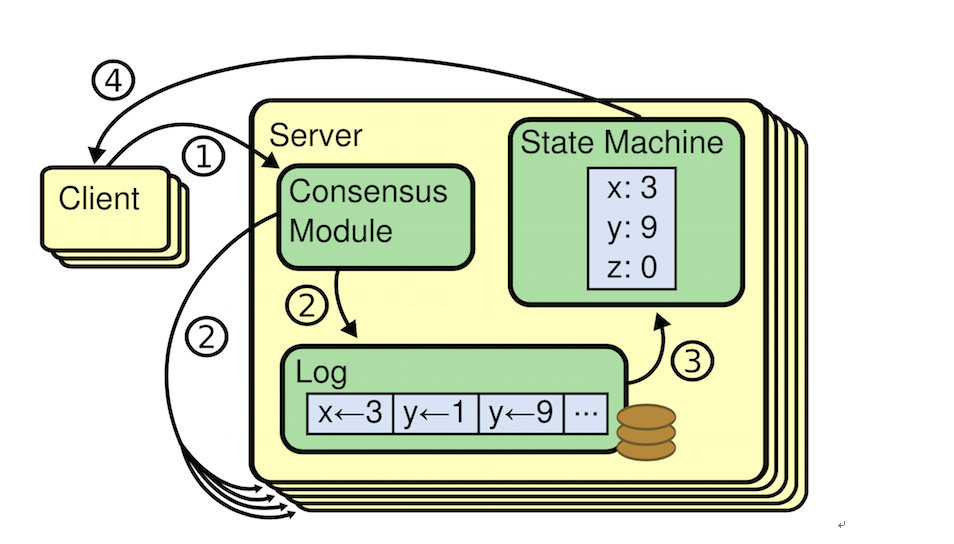
复制状态机的结构。一致性算法管理着来自客户端指令的复制日志。状态机从日志中处理相同顺序的相同指令,所以产生的结果也是相同的。
复制状态机通常都是基于复制日志实现的,如图 。每一个服务器存储一个包含一系列指令的日志,并且按照日志的顺序进行执行。每一个日志都按照相同的顺序包含相同的指令,所以每一个服务器都执行相同的指令序列。因为每个状态机都是确定的,每一次执行操作都产生相同的状态和同样的序列。
保证复制日志相同就是一致性算法的工作了。在一台服务器上,一致性模块接收客户端发送来的指令然后增加到自己的日志中去。它和其他服务器上的一致性模块进行通信来保证每一个服务器上的日志最终都以相同的顺序包含相同的请求,尽管有些服务器会宕机。一旦指令被正确的复制,每一个服务器的状态机按照日志顺序处理他们,然后输出结果被返回给客户端。因此,服务器集群看起来形成一个高可靠的状态机。
一致性算法特性
-
安全性保证(绝对不会返回一个错误的结果):
在非拜占庭错误情况下,包括网络延迟、分区、丢包、冗余和乱序等错误都可以保证正确。 -
可用性:
集群中只要有大多数的机器可运行并且能够相互通信、和客户端通信,就可以保证可用。因此,一个典型的包含 5 个节点的集群可以容忍两个节点的失败。服务器被停止就认为是失败。他们当有稳定的存储的时候可以从状态中恢复回来并重新加入集群。 -
不依赖时序来保证一致性:
物理时钟错误或者极端的消息延迟在可能只有在最坏情况下才会导致可用性问题。
通常情况下,一条指令可以尽可能快的在集群中大多数节点响应一轮远程过程调用时完成。小部分比较慢的节点不会影响系统整体的性能。
Raft 一致性算法
Raft 将一致性算法分解成了几个关键模块,例如领导人选举、日志复制和安全性。同时它通过实施一个更强的一致性来减少需要考虑的状态的数量。
Raft 通过选举一个高贵的领导人,然后给予他全部的管理复制日志的责任来实现一致性。领导人从客户端接收日志条目,把日志条目复制到其他服务器上,并且当保证安全性的时候告诉其他的服务器应用日志条目到他们的状态机中。拥有一个领导人大大简化了对复制日志的管理。例如,领导人可以决定新的日志条目需要放在日志中的什么位置而不需要和其他服务器商议,并且数据都从领导人流向其他服务器。一个领导人可以宕机,可以和其他服务器失去连接,这时一个新的领导人会被选举出来。
Raft 将一致性问题分解成了三个相对独立的子问题:
- 领导选举:一个新的领导人需要被选举出来,当先存的领导人宕机的时候。
- 日志复制: 领导人必须从客户端接收日志然后复制到集群中的其他节点,并且强制要求其他节点的日志保持和自己相同。
- 安全性: 在 Raft 中安全性的关键是在图 中展示的状态机安全:如果有任何的服务器节点已经应用了一个确定的日志条目到它的状态机中,那么其他服务器节点不能在同一个日志索引位置应用一个不同的指令。
Raft集群中角色有三种, 分为Leader, Candidate,Follower. 其中Candidate是一个中间状态, 只发生在发生领导人选举的过程中。
对于写请求
- Leader负责接受用户的请求(如 set key = value),给请求包装成一条日志, 并且分配一个单调递增编号Index, 并且分发这个请求日志到集群中所有其他机器上, 等到集群中的大多数机器确认收到了这个请求后,Raft就会调整自己的commitIndex(代表可以提交到状态机中的序号), 异步向本地状态机内提交这个请求(执行set key = value),并且向集群中其他机器发送commitIndex, 要求其他机器提交这个请求。
- 需要注意的是, 这里并不是一个完整的两阶段提交。
对于读请求
- Leader在收到读请求后, 记录下此时的commitIndex, 并且向集群中其他机器发送心跳广播, 如果确认多数派相应成功, 证明自己还是Leader, 再确定已经执行的Index(applyIndex) >= commitIndex, 然后在从状态机中取出结果返回给客户端。
- 如果是Follower收到了读请求, 需要向Leader请求当前的commitIndex(Leader收到请求后, 也会和上述行为一样,发送心跳确定自己的Leader地位), 并且保证Follower上的applyIndex > commitIndex.再返回读请求。
如果集群中的一台机器在一段时间内没有收到心跳, 就会把自己的Term加一, 并且向其他机器发送选举请求.所以任期的增加来自于选主.如果没有发生选主, 那么集群内并不会发生任期升级。
Raft协议能够保证在一个Term内, 只有一个Leader, 手段就是:
- 成为Leader需要经过集群中大多数机器赞成
- 任何一台机器, 在一个Term内, 只能给一台机器投票
最后
以上就是能干摩托最近收集整理的关于MIT 6.824 分布式课程 Raft算法简介的全部内容,更多相关MIT内容请搜索靠谱客的其他文章。








发表评论 取消回复