# CalHamletV1.py
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\]^_‘{|}~':
txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格
return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))items.sorted( key=lambda x: x[1]) 中 items为待排序的对象;key=lambda x: x[1] 为对前面的对象中的第二维数据(即value)的值进行排序。 key=lambda 变量:变量[维数] 。维数可以按照自己的需要进行设置。
还可以直接写成:sorted(counts.items(), key=lambda x: x[1], reverse=True)
{0:<10}表示左对齐,{1:>5}:右对齐,0表示第一个参数,1表示第二个参数
参考:format用法详解
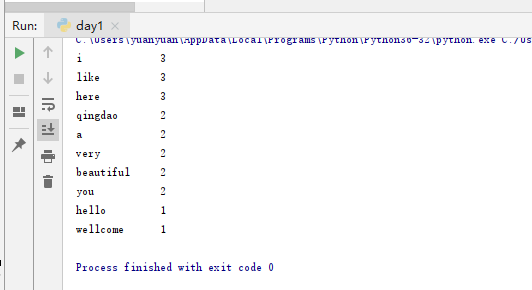
最后
以上就是细心画笔最近收集整理的关于Python-统计词频的全部内容,更多相关Python-统计词频内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。
![python 热词分析_Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)







发表评论 取消回复