用python正则表达式实现简单的词形统计
需求如下:
交流了好长时间才知道她要的是词形统计,如AA.AAB,AABB...
编码如下
import re
from matplotlib import font_manager
import matplotlib.pyplot as plt
import numpy as np
def read_file_gbk(filename):
with open(filename,'r',encoding='GBK') as f:
s = f.read()
s = re.sub('/C', '', s)
s = re.sub('r|n|s','',s)
return s
def read_file_utf8(filename):
with open(filename,'r',encoding='utf-8') as f:
s = f.read()
s = re.sub('/C', '', s)
s = re.sub('r|n|s','',s)
return s
def dict_sort(dictname):
dictlist = sorted(dictname.items(),key=lambda x:x[1],reverse=True)
return dict(dictlist)
def main():
# 读取文本,输出为长串字符
s = read_file_gbk('zz.txt')
# 通过标点符合进行切分,同时去掉特殊字符
sentences = re.split(r' *[.?!,。…… —— oo ll 99]['")]]* *', s)
#初始化《主角》 数量
SIZE_AA_ZZ = 0;
SIZE_AABB_ZZ = 0;
SIZE_ABB_ZZ = 0;
SIZE_ABAB_ZZ = 0;
for stuff in sentences:
# print(stuff)
# 原理解析
# "(.)1(.)2"这个正则,
# .表示除换行外任意字符
# 1 表示第一个括号里面的字符重复,默认重复一次,想重复4次加{4} 即(.)1{4}
# 2 表示第二个括号里面的字符重复
# 开始匹配AA
strings = re.finditer(r'(.)1', stuff)
# print(type(strings))
for i in strings:
print(i)
SIZE_AA_ZZ = SIZE_AA_ZZ+1
strings = re.finditer(r'(.)1(.)2', stuff)
for i in strings:
print(i)
SIZE_AABB_ZZ =SIZE_AABB_ZZ+1
strings = re.finditer(r'(.)1(.)2', stuff)
for i in strings:
print(i)
SIZE_ABB_ZZ =SIZE_ABB_ZZ+1
strings = re.finditer(r'(..)1', stuff)
for i in strings:
print(i)
SIZE_ABAB_ZZ =SIZE_ABAB_ZZ+1
s = read_file_utf8('qq.txt')
print(s)
sentences = re.split(r' *[.?!,。…… —— oo ll 99 00 44 66 11 一一 tt // ww]['")]]* *', s)
#初始化《秦腔》 数量
SIZE_AA_QQ = 0
SIZE_AABB_QQ = 0
SIZE_ABB_QQ = 0
SIZE_ABAB_QQ = 0
for stuff in sentences:
# print(stuff)
# 开始匹配AA
strings = re.finditer(r'(.)1', stuff)
# print(type(strings))
for i in strings:
print(i)
SIZE_AA_QQ = SIZE_AA_QQ+1
strings = re.finditer(r'(.)1(.)2', stuff)
for i in strings:
print(i)
SIZE_AABB_QQ =SIZE_AABB_QQ+1
strings = re.finditer(r'(.)1(.)2', stuff)
for i in strings:
print(i)
SIZE_ABB_QQ =SIZE_ABB_QQ+1
strings = re.finditer(r'(..)1', stuff)
for i in strings:
print(i)
SIZE_ABAB_QQ =SIZE_ABAB_QQ+1
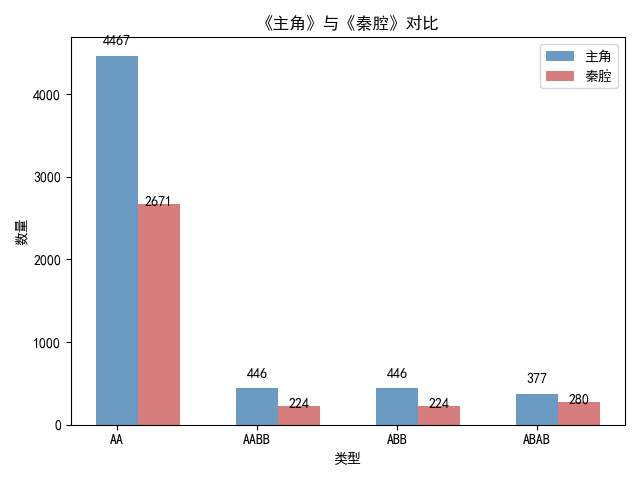
print("《主角》中的AA形式有"+str(SIZE_AA_ZZ)+"个")
print("《主角》中的AABB形式有"+str(+SIZE_AABB_ZZ)+"个")
print("《主角》中的ABB形式有"+str(SIZE_ABB_ZZ)+"个")
print("《主角》中的ABAB形式有"+str(SIZE_ABAB_ZZ)+"个")
print("《秦腔》中的AA形式有"+str(SIZE_AA_QQ)+"个")
print("《秦腔》中的AABB形式有"+str(SIZE_AABB_QQ)+"个")
print("《秦腔》中的ABB形式有"+str(SIZE_ABB_QQ)+"个")
print("《秦腔》中的ABAB形式有"+str(SIZE_ABAB_QQ)+"个")
# start draw
# 构建数据
x_data = ['AA', 'AABB', 'ABB', 'ABAB']
y_data = [SIZE_AA_ZZ, SIZE_AABB_ZZ,SIZE_ABB_ZZ, SIZE_ABAB_ZZ]
y_data2 = [SIZE_AA_QQ, SIZE_AABB_QQ,SIZE_ABB_QQ, SIZE_ABAB_QQ]
bar_width = 0.3
my_font = font_manager.FontProperties(fname='C:WindowsFontssimkai.ttf', size=12)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 将X轴数据改为使用range(len(x_data), 就是0、1、2...
plt.bar(x=x_data, height=y_data, label='主角',
color='steelblue', alpha=0.8, width=bar_width)
# 将X轴数据改为使用np.arange(len(x_data))+bar_width,
# 就是bar_width、1+bar_width、2+bar_width...这样就和第一个柱状图并列了
plt.bar(x=np.arange(len(x_data)) + bar_width, height=y_data2,
label='秦腔', color='indianred', alpha=0.8, width=bar_width)
# 在柱状图上显示具体数值, ha参数控制水平对齐方式, va控制垂直对齐方式
for x, y in enumerate(y_data):
plt.text(x, y + 100, '%s' % y, ha='center', va='bottom')
for x, y in enumerate(y_data2):
plt.text(x + bar_width, y + 100, '%s' % y, ha='center', va='top')
# 设置标题
plt.title("《主角》与《秦腔》对比")
# 为两条坐标轴设置名称
plt.xlabel("类型")
plt.ylabel("数量")
# 显示图例
plt.legend()
plt.show()
if __name__=="__main__":
main()
调试结果
总结
思路很简单,就是读文件-->分句-->正则提取-->统计-->绘图。话不多说,继续我的java搬砖大业了哈哈
最后
以上就是风趣路人最近收集整理的关于python实现简单的词形统计的全部内容,更多相关python实现简单内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![[Swift]LeetCode451. 根据字符出现频率排序 | Sort Characters By Frequency](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)
发表评论 取消回复