文章目录
- ???? 前言
- ???? 1. 冒泡排序(咕噜咕噜)
- ???? 2. 选择排序
- ???? 3. 插入排序
- ???? 4. 希尔排序
- ???? 5. 堆排序
- ???? 6. 快速排序(重点)
- 6.1 PartSort1 - Hoare法:
- 6.2 Partsort2 - 挖坑法:
- 6.3 PartSort3 - 前后指针法:
- 6.4 递归实现快排:
- 6.5 快排的 时间/空间 复杂度:
- 6.6 快排的优化:
- (1)优化一:(三数取中)
- (2)优化二:(小区间非递归)
- 6.7 非递归实现快排:(用栈来实现)
- ???? 7. 归并排序(重点)
- 7.1 递归实现归并排序:
- 7.2 非递归实现归并排序:(用循环来实现)
- 7.3 归并排序的 时间/空间 复杂度:
- 7.4 归并排序的外排序:
- ???? 8. 计数排序
- 8.1 计数排序的 时间/空间 复杂度:
- ???? 9. 测试排序的性能
- ???? 10. 稳定性 + 总结
- 10.1 稳定性:
- 10.2 总结:
???? 前言
- 排序想必大家都不陌生,在大家学习C语言阶段就已经涉及到了两个经典的排序分别是:冒泡排序 和 选择排序。
- 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
在我们学过数据结构之后,我们知道冒泡排序和选择排序的时间复杂度是非常高的都是:〇(N^2)。这样在处理大数据的排序时就会很慢。
- 本篇将带来几种比较优的排序算法,它们在处理大量数据的排序时表现得很出色,用时很少。
- 下面就让我们来见识一下这几种比较????的排序。
排序分类:
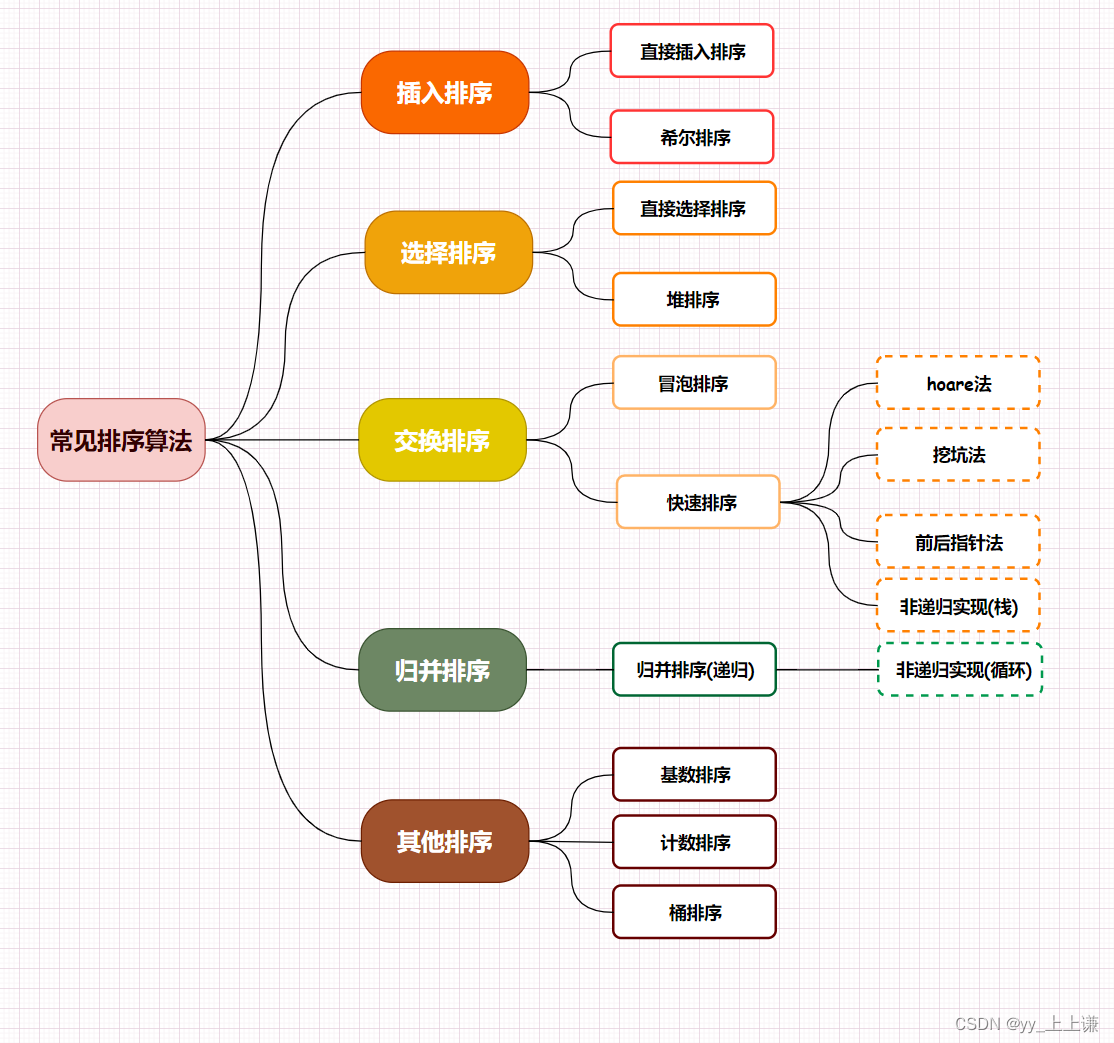
- 准备起飞,精彩即将呈现:????????????????????????
???? 1. 冒泡排序(咕噜咕噜)
排序过程:
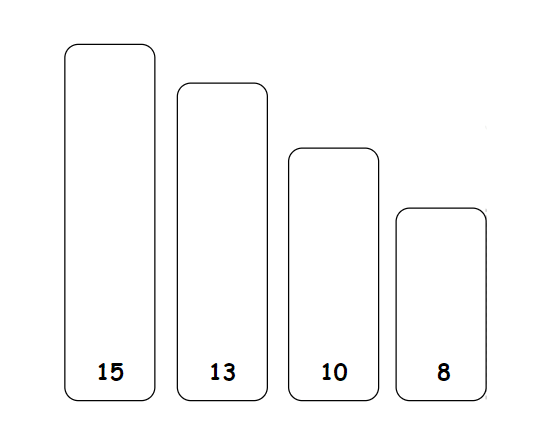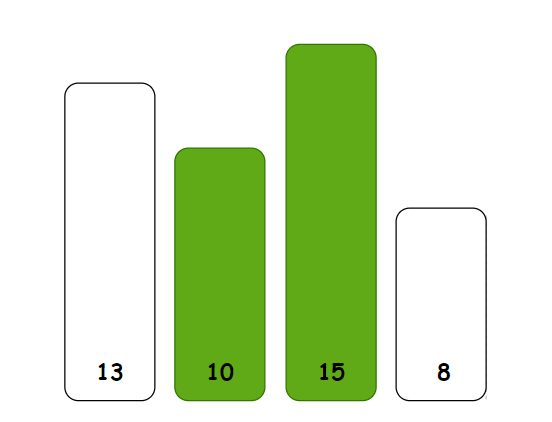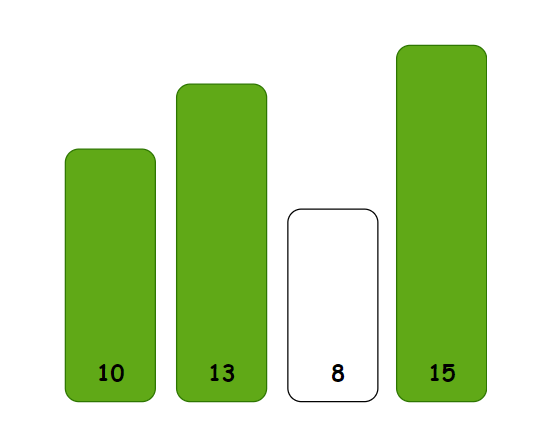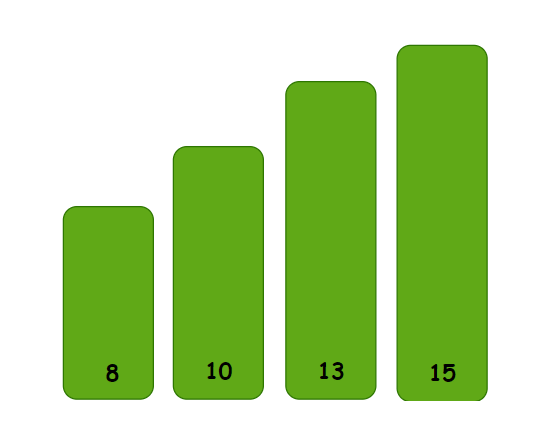
大家肯定非常熟悉这个代码了就直接上代码:
- 这里加了一步判断条件
- 当这个序列已经有序的时候,再对其进行冒泡比较的话只用将数组遍历一遍即可
- 此时的时间复杂度为〇(N),超快(当然也没意义,因为已经有序了)
//冒泡排序
void BubbleSort(int* arr, int len)
{
assert(arr);
for (int i = 0; i < len - 1; i++)
{
int flag = 1;
for (int j = 0; j < len - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 0;
}
}
if (flag == 1)
break;
}
}
1.时间复杂度:
- 无序时 - 时间复杂度为:〇(N^2)
- 当且仅当序列有序时 - 时间复杂度为:〇(N)
2.空间复杂度:
- 没有额外借助空间,所以空间复杂度为:〇(1)
???? 2. 选择排序
这个排序我们也不陌生,这里提两种办法,一种是一次选出一个数据,另一种是一次选出最大和最小两个值分别放到序列的头和尾部。
1.一次选一个:
排序过程:
//选择排序 - 一次选一个
void SelectSort(int* arr, int len)
{
assert(arr);
for (int i = 0; i < len - 1; i++)
{
for (int j = i + 1; j < len; j++)
{
if (arr[i] < arr[j])
{
Swap(&arr[i], &arr[j]);
}
}
}
}
2.一次选两个
排序过程:
//选择排序 - 一次选两个
void SelectSort_(int* arr, int len)
{
int left = 0, right = len - 1;
while (left <= right)
{
int mini = left, maxi = left;
for (int i = left + 1; i <= right; i++)
{
if (arr[i] < arr[mini])
{
mini = i;
}
if (arr[i] > arr[maxi])
{
maxi = i;
}
}
Swap(&arr[left], &arr[mini]);
//如果left和maxi重叠
if (left == maxi)
{
maxi = mini;
}
Swap(&arr[right], &arr[maxi]);
left++;
right--;
}
}
值得注意的是:
- 当最大的数是最左边的时,最小的数不是最左边的时
- 这时先交换的是arr[left], &arr[mini],再去执行交换arr[right] 和 arr[maxi]
- 这时的maxi对应的位置被调包了,已经不是原来的值了,所以要加一个判断条件if (left == maxi) maxi = mini。
3.时间复杂度:
- 选择排序没有优化可言,当对有序序列排序的时候还是会一步步执行代码〇(N^2)
- 总体来说一次选两个的方法更优一点,但是在算时间复杂度粗略计算时
时间复杂度都是:〇(N^2)
4.空间复杂度:
- 没有额外借助空间,所以空间复杂度为:〇(1)
???? 3. 插入排序
1.基本思想:
- 大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为
止,得到一个新的有序序列。
实际中我们玩扑克牌时,就用了插入排序的思想:
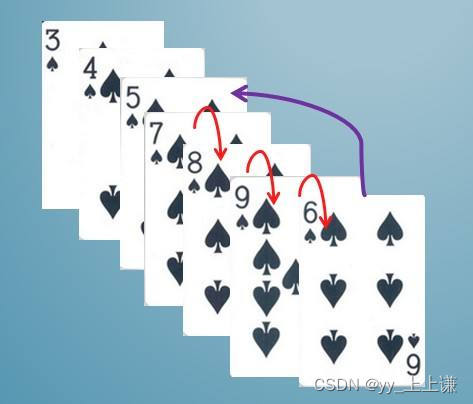
2.实现方法:
- 本质就是有一个有序区间,插入一个数据,依旧保持它有序
- 那么问题来了,我们要怎么保证插入之前的序列中的数都是有序的呢
- 我们不妨将大问题分割成小问题来看,将序列分成小区间来看
- 当我们将问题分成不能再分割的子问题的时候你可能就会恍然大悟
- 当序列只有一个数值的时候,这个序列必然有序
- 我们就从最小有序区间开始排,直到所有的值都是有序的
排序过程:
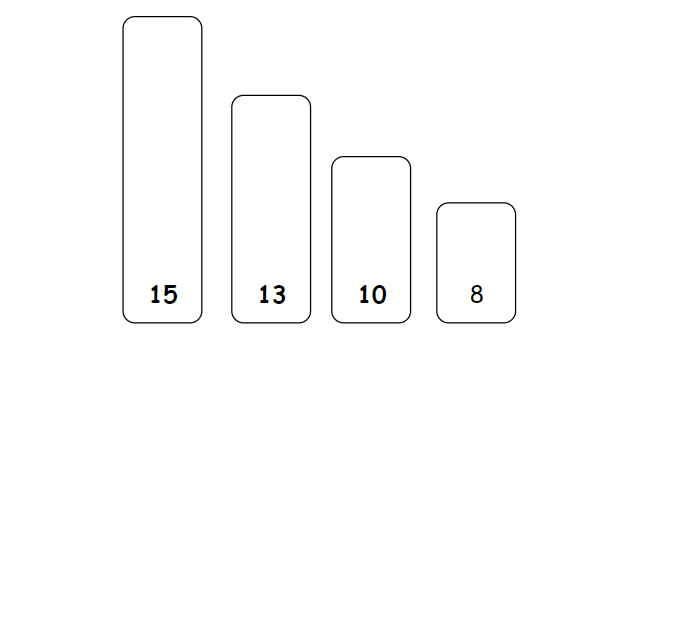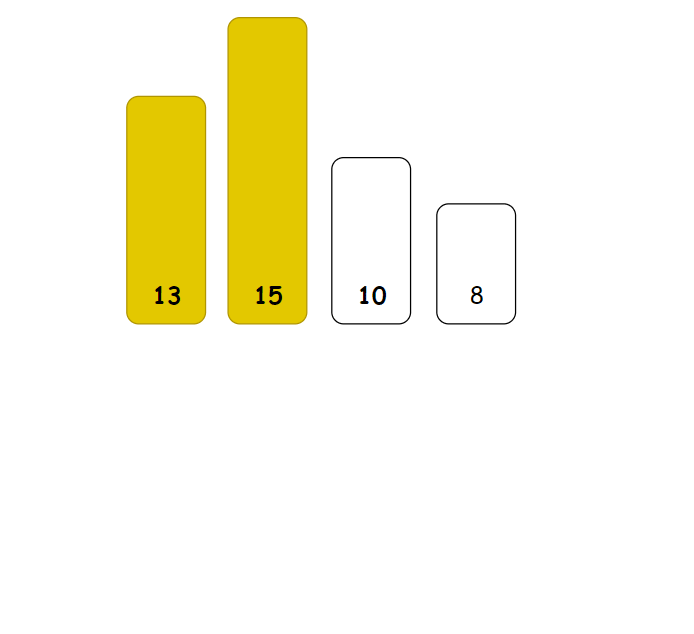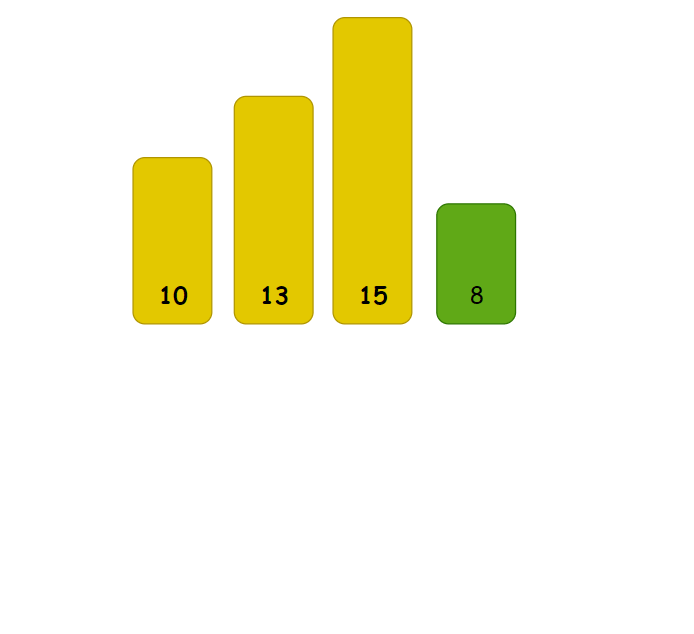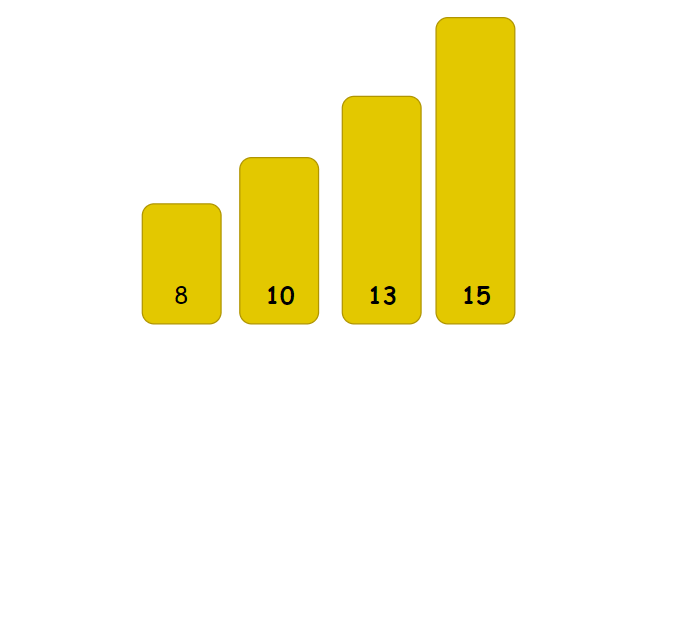
//插入排序
void InsertSort(int* arr, int len)
{
assert(arr);
//单趟排序:[0,end]有序 end + 1 位置的值,插入进去,保持它依旧有序
for (int i = 0; i < len - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
//升序
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
循环条件是i < len - 1是因为当end == len时arr[end + 1]就会越界!
3.时间复杂度:
- 最差 - 时间复杂度:〇(N^2) – 完全逆序排序时
- 最好 - 时间复杂度:〇(N) – 顺序有序 或 接近顺序有序时
综上所述:
插入排序的 时间复杂度:在〇(N) ~ 〇(N^2)之间
4.空间复杂度:
- 没有额外借助空间,所以空间复杂度为:〇(1)
插入排序和冒泡排序比较:
- 完全有序的时候, 插入排序和冒泡排序的时间复杂度一样
- 但是对于那种, 接近有序但是有个别不是有序的,插入排序比较好
- 因为冒泡排序的优化只对全部有序的起作用, 但是插入排序对局部有序也能体现价值
???? 4. 希尔排序
希尔排序是对插入排序的优化,分为两个部分:
1.预排序 – 目的(使序列接近排序)
gap == 3时分组如下:
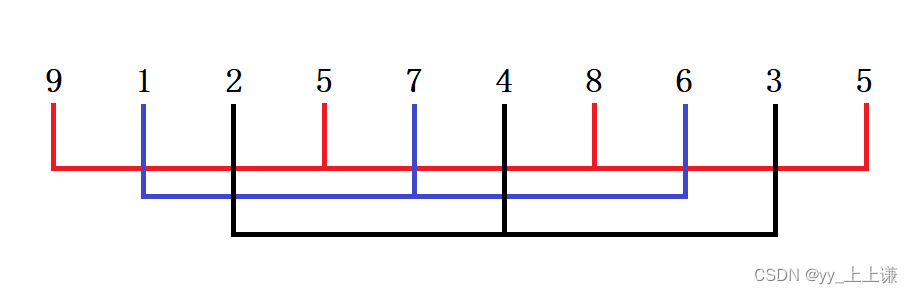
- 如图所示,将这组数分成了3组,一种颜色代表一组
- 预排序使大的数更快的到后面,小的数更快的到前面,整个序列接近有序。
- 分别使用插入排序的思想对这gap组数据进行插入排序(gap为两个数中间的间距)
- 相比于原数据, 大的数据尽可能调到后面去了, 小的数据尽可能调到了前面去了
- 再对其进行直接插入排序, 效果会好一点,逆序排序效果会更好一点
2.对gap的讨论
- 如果gap越小,越接近有序,当gap == 1时排出来的就是有序的
- 如果gap越大,大的数据可以更快的到最后, 小的数据, 可以更快的到前面,但是它越不接近有序
3.预排序可以排多组 - gap处理
- gap为一个值就将整个序列处理一遍,尽量使小的数向数组前方聚集,大的数往数组后面聚集
外层控制一次层循环,不断地缩小gap的值,使得小的数越来越靠进数组前面,大的数越来越靠近数组后面,这样整个数组就接近有序了,最后控制gap == 1,最后一次就是插入排序 - gap /= 3; 官方的一种建议的方式, 并不能保证最后一次gap是1,gap = gap / 3 + 1; 保证了gap最后一定是1,gap为1就是直接插入排序
gap从3减少到1的排序流程:
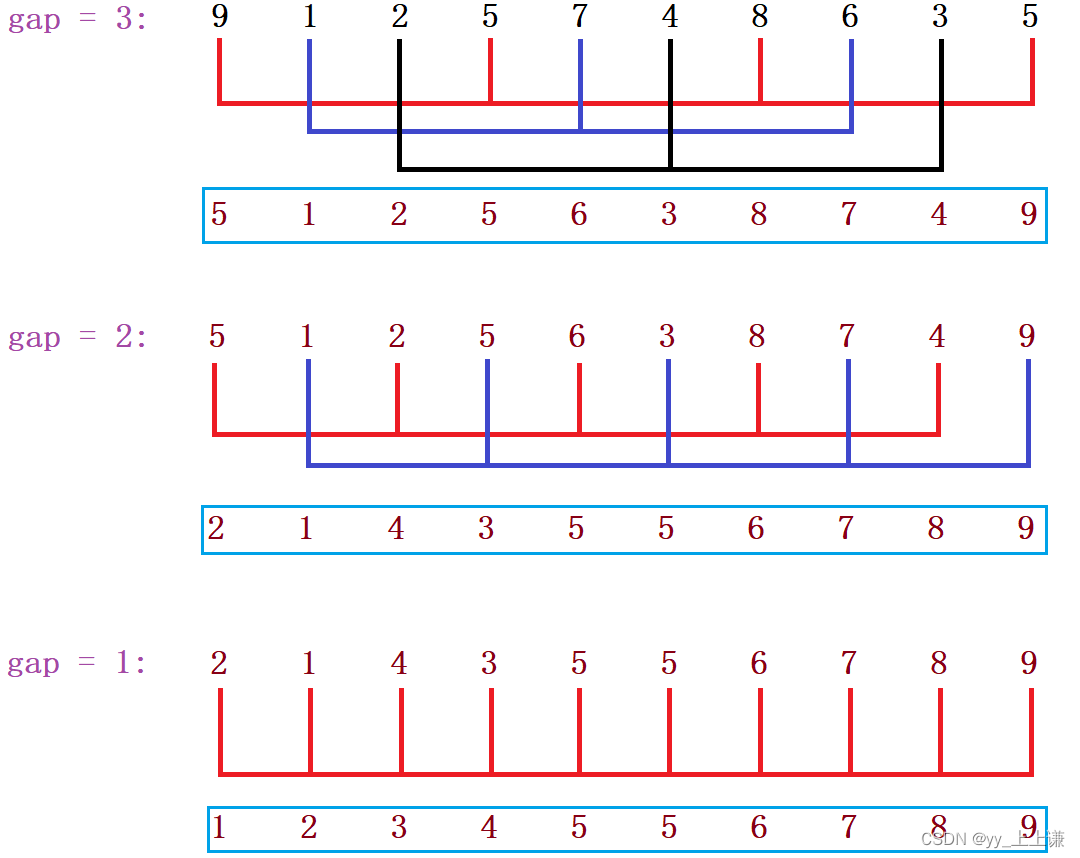
//希尔排序 - 缩小增量排序
void ShellSort(int* arr, int len)
{
assert(arr);
//预排序
//两层循环 -- 多组并排
//1.gap > 1 预排序
//2.gap == 1 直接插入排序
int gap = len;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < len - gap; i++)
{
int end = i;
int tmp = arr[end + gap];
//升序
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}
循环条件是i < len - gap是因为当end == len时arr[end + gap]就会越界!
4.希尔排序的缺陷:
- 对一组数的时候, 当这组数字本来就是近似有序的那么预排序就白做了
- 虽然预排序排近似有序的一串数的时候没什么大的变化,(两下走完了),没什么大的效果,但是这种情况出现的次数很少
5.时间复杂度:
-
希尔排序的时间复杂度很难计算,这里只提供非常粗略的估算
-
先来看预排序的时间复杂度:
当gap很大时 (相对于len还是小的):
内部while循环可以忽略,因为gap跳的很快,i 相比 gap 很小,只用计算外部for循环即可,取大头近似取,时间复杂度:〇(N)。
当gap很小时(gap已经减到了很小):
此时的序列,较大的数已经靠近数组前面,较小的数已经靠近数组后面,也就是说这个数组接近有序,这时候内部while循环也可以忽略,因为几乎不执行,或者执行很少,可以看作只有for循环,时间复杂度:〇(N)。
我们来去一个平均值:
(gap很大的时间复杂度 + gap很小的时间复杂度) / 2 = 平均时间复杂度 = 〇(N) -
外层循环的时间复杂度
就很好算了,忽略 + 1,gap一直除以 3 ,直到gap为1为之
那么执行的次数就是logN次,外层循环的时间复杂度:〇(logN) -
综合来看希尔排序的时间复杂度
时间复杂度:〇(N * logN)
当然上述计算存在不科学之处,下面通过查阅资料得到详情时间复杂度解析:
《数据结构(C语言版)》—— 严蔚敏

《数据结构-用面相对象方法与C++描述》—— 殷人昆

7.空间复杂度:
- 没有额外借助空间,所以空间复杂度为:〇(1)
???? 5. 堆排序
在之前的数据结构的学习中,我们已经学习过堆排序,堆排序是一个非常出色的算法,时间复杂度〇(N*logN),空间复杂度〇(1)。
????不熟悉的小伙伴点这里来复习一下我之前写的博文:
堆排序复习:???? 传送门
???? 6. 快速排序(重点)
快速排序的历史:
它诞生于1960年,首次被英国计算机科学家霍尔 (Sir Charles Antony Richard Hoare) 发现。其发现紧随Shell排序之后,成为又一个突破的算法,但是因为其独树一帜的复杂度分析方式,让其成为一个高级排序算法,并且不断影响后世,成为了众多高级语言库自带的算法。
下面提供三种实现快排的方法:
6.1 PartSort1 - Hoare法:
这个方法是发明快排的大佬(Hoare)提供的,假设一组数最左边的数为基准数key(关键字)。用左右指针来遍历这个数组,在介绍这个方法之前,我们先来做个铺垫。
有序序列:
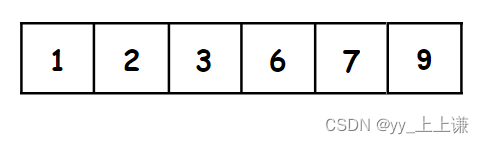 1.有序的特性:
1.有序的特性:
- 如图所示,这是一个有序的序列,我们以升序为例:我们发现,序列中每一个数字都有一个特性,那就是任何一个数的左边的所有数都比该数小,该数右边所有数都比该数大,那么该数就处在它在有序序列中正确的位置。
- 快排就是基于有序序列这样一特性,如果我们就将序列中每一个数都放在了它们的 “正确位置”,那么该序列必然就是有序的序列了。
2.先走一趟 - 排升序
我们先将一个关键字key放在正确位置:
- 对于关键字key的选取,我们通常选取序列最左边或者最右边的值为关键字。
- 我们运用左右两个指针(L,R)
要求:
- key左边的值都比key小,key右边的值都比key大
方法:
- 右边先走,找到小于key的停下来,左边再走,找到大于key的停下来
- 左右指针指向的值交换,右边再走,重复上述过程
- 直到左右指针相遇,将key的值和相遇点的值交换
- 这样key的放在了正确的位置上
示意图:
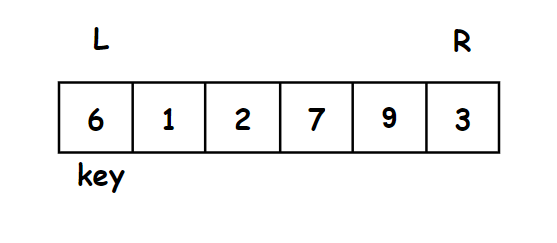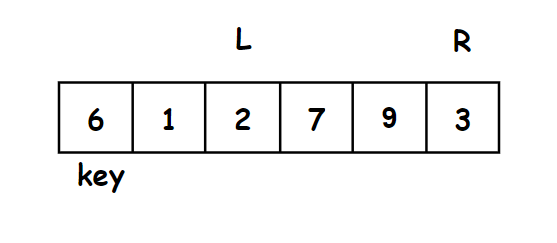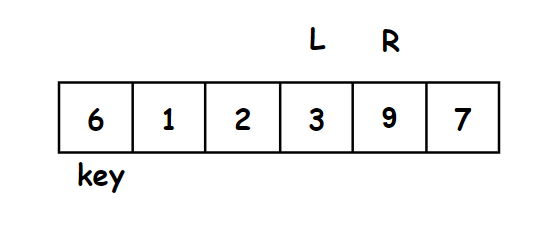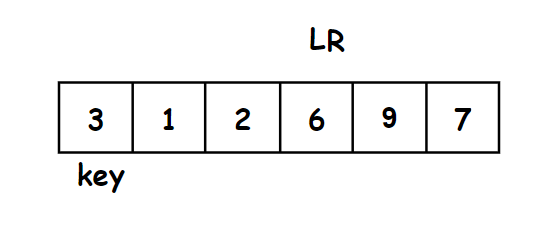
右指针先走找比6小的数,最右边第一个就是比3小的数,左再边走去找比6大的数。
代码如下:
//hoare - 单趟排序
int PartSort1(int* arr, int left, int right)
{
//int midi = GetMidIndex(arr, left, right);
//Swap(&arr[midi], &arr[left]);
int keyi = left;
while (left < right)
{
//右边先走 - 找小
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
//左边先走 - 找大
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
Swap(&arr[left], &arr[right]);
}
Swap(&arr[keyi], &arr[left]);
//返回相遇的位置 - (right == left)
return left;
}
hoare - 单趟排序极端情景思维:
- 5 5 2 3 5 - 内部while循环条件不带等号,外头while循环会死循环
- 1 2 3 4 5 - 内部while循环条件不带left < right会越界
3.常见疑问:(以动图为例)
最后两个指针相遇的时候一定是比key小的吗?答案是一定的。
左边做key,如何保证相遇位置的值比key小呢,右边先走保证的。
分两种情况来说:
- (1)左指针遇右指针,R先停下来,L走去遇到R,相遇的位置的值是比key小的。
- (2)右指针遇左指针,左右刚交换完,R再走,R没有找到比key小的直接和L相遇了,因为这时R指向L的位置,上次交换L的位置放的是比key小的数,相遇的位置的值也是比key小的。
- (3)右指针遇左指针,如果R一直没有找到比key小的值,就一直向左找,直到找到key为止,相遇位置的值是等于key的, key和key交换。
所以哪边指针先走,最后两个指针停下来相遇的位置指向的值,一定是先走的那个指针要找的值。
4.Hoare法小结:
根据序列的有序这一个特性:
- 升序:序列左边的值小,右边的值大
- 降序:序列左边的值大,右边的值小
那我们在用hoare法排序列时,要根据要排的是升序还是降序,再来确定左右指针找的值是大于key还是小于key,最后根据左右指针哪个先走来选定key的位置。
举个栗子:
如果要排降序:(序列前面数值大,后面数值小)
-
那么R要找比key大的数,L要找比key小的数,两数一交换就将大的数放在了前面,小的数放在了后面。
-
如果R先走: 最后两个指针相遇的共同指向的就是比key大的数,因为相遇点要和key交换,又因为是降序比key大的数要放在前面,所以这个key要选在左边。
-
如果L先走: 最后两个指针相遇的共同指向的就是比key小的数,因为相遇点要和key交换,又因为是降序比key小的数要放在后面,所以这个key要选在右边。
-
选key的位置: 总是放在先走那一边的相反的一边,比如先走左指针,key放在右边,先走右指针,key放在左边。
如果要排升序:(序列前面数值小,后面数值大)
大家可以类推,和上面思路是一样的……
6.2 Partsort2 - 挖坑法:
相较于Hoare法而言,挖坑法与它的思路几乎一样,但是理解起来会比Hoare法更容易。
- 相比hoare法:
- 不需要理解为什么最终相遇位置比key小
- 不需要理解为什么左边做key,右指针先走
- 方法:
- 右指针先走,左边有坑,右指针找到符合条件的值,直接将指向的值填到左边的坑中,右指针指向的地方视作新的坑
- 左指针再走,右边有坑,左指针找到符合条件的值,直接将指向的值填到右边的坑中,左指针指向的地方视作新的坑
- 最后左右指针相遇,相遇点为一个坑位,key直接填到坑里
- 这样key左边的值都比key小,key右边的值都比key大
示意图:
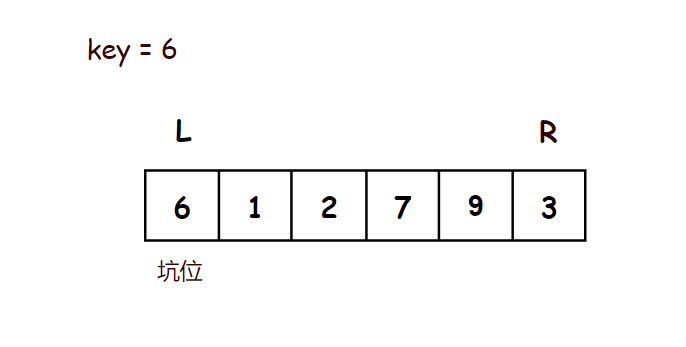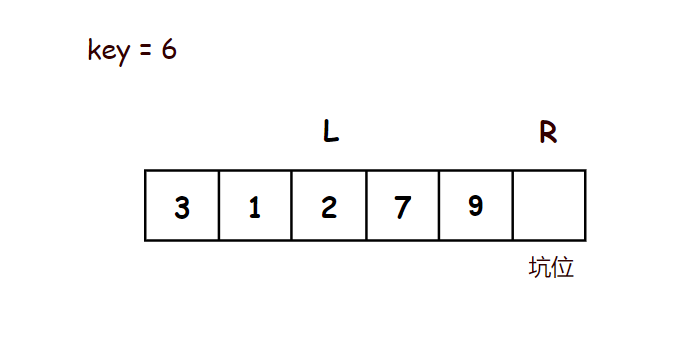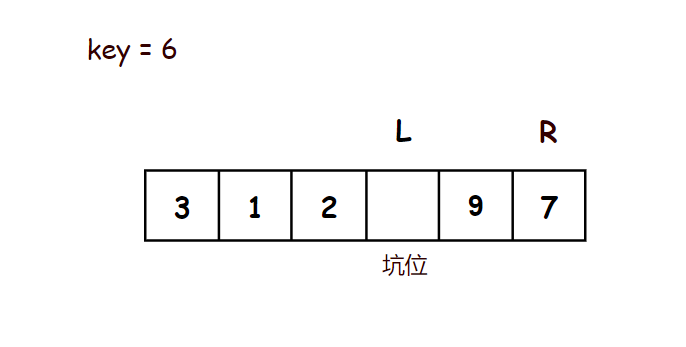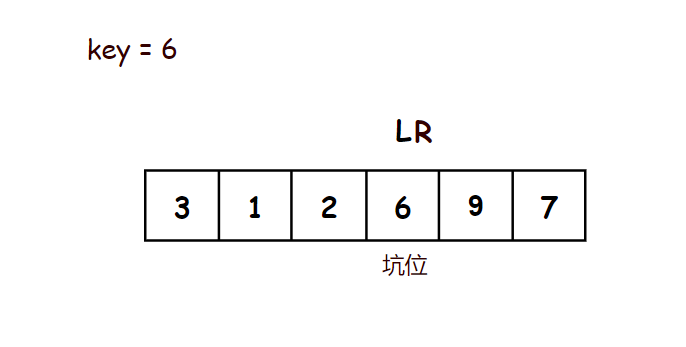
//挖坑法 - 单趟排序
int PartSort2(int* arr, int left, int right)
{
//int midi = GetMidIndex(arr, left, right);
//Swap(&arr[midi], &arr[left]);
int key = arr[left];
//坑位
int pit = left;
while (left < right)
{
//右边先走 - 找小
while (left < right && arr[right] >= key)
{
right--;
}
//填坑 - 形成新的坑
arr[pit] = arr[right];
pit = right;
//左边先走 - 找大
while (left < right && arr[left] <= key)
{
left++;
}
//填坑 - 形成新的坑
arr[pit] = arr[left];
pit = left;
}
arr[pit] = key;
return pit;
}
3.坑位的选择:
- 如果是左边坑位的话: 那就是将右边的数填到左边来,那么一定是右指针先走
- 如果是右边坑位的话: 那就是将左边的数填到右边来,那么一定是左指针先走
4.挖坑法和Hoare法的区别:
- 挖坑法 和 hoare法 时间复杂度差不多 ,两个版本本质上并没有什么区别 - 思想类似
- 但是也存在一些不同,不一样的原因就是:hoare法选到key以后,key 没动,而挖坑法动力了key
6.3 PartSort3 - 前后指针法:
1.目的
- 将比key小的数聚集在前方,将比key大的数聚集在后方
2.方法:
- 在序列开头定义两个指针(prev,cur),prev指向开头,cur指向prev的后面一个
- 当cur还没遇到比key大的值时,prev紧跟着cur,一前一后
- 当cur遇到比key大的值以后,cur还是继续往后走,prev不走,prev和cur之间隔着一段比key大的值的区间
- 当cur再次遇到比key小的数之后,将prev++指向的当前位置的后一个,再将此时prev指向的值和cur指向的值交换
- 这样就实现了将小的值聚集在了前面,将大的值聚集到了后面
- 最后将prev指向的值和key交换,此时prev指向的是比key小的值的区间的最右边一个数
- 这样key左边的值都比key小,key右边的值都比key大
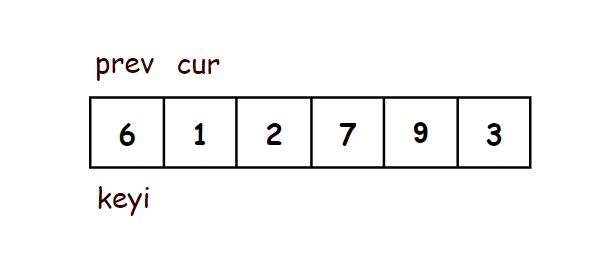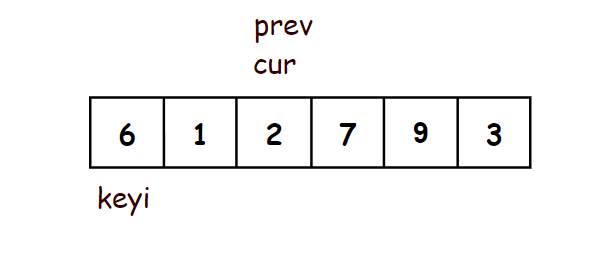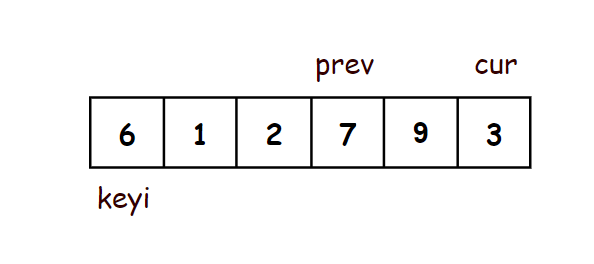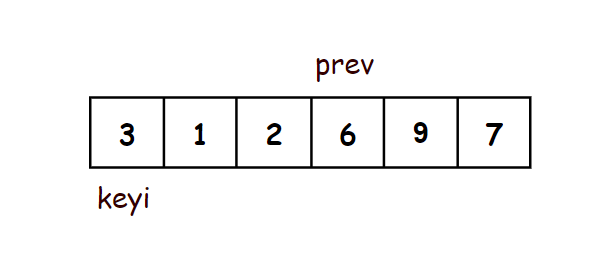
//前后指针法 - 最简洁的写法
int PartSort3(int* arr, int left, int right)
{
int midi = GetMidIndex(arr, left, right);
Swap(&arr[midi], &arr[left]);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (arr[cur] < arr[keyi] && arr[++prev] != arr[cur])
{
Swap(&arr[prev], &arr[cur]);
}
cur++;
}
Swap(&arr[prev], &arr[keyi]);
return prev;
}
3.条件if (arr[cur] < arr[keyi] && arr[++prev] != arr[cur])的意义
- cur遇到比key小的值以后++prev
- 防止自己跟自己交换,减少执行交换的次数
6.4 递归实现快排:
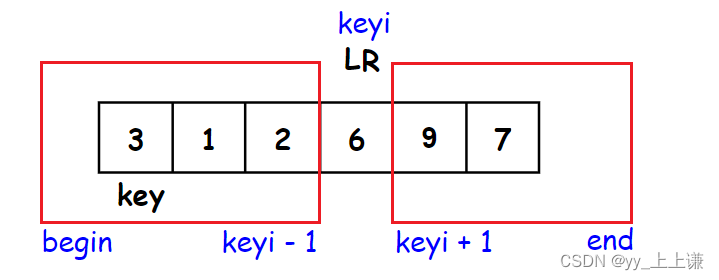
如何将序列中每个数都放在“正确的位置”呢?
1.递归快排完整过程:
- 单趟排完以后, key已经放在正确的位置了
- 如果左边有序, 右边有序, 那么我们整体就有序了
- 那么左边和右边如何有序呢?
- 递归的分治解决子问题,左右区间选出keyi之后,再对左右区间进行分割
- 不断地将区间缩小,直到将区间分到只剩一个数,或区间不存在时递归结束
//快速排序 - 没加小区间优化
void QuickSort1(int* arr, int begin, int end)
{
//当子区间相等 - 只有一个值
//或者 不存在子区间 那么就是递归结束的子问题
if (begin >= end)
{
return;
}
//int keyi = PartSort1(arr, begin, end);
//int keyi = PartSort2(arr, begin, end);
int keyi = PartSort3(arr, begin, end);
//单趟排序之后, 保证keyi的左边比keyi小,keyi的右边比keyi大
//[begin, keyi - 1] keyi [keyi + 1, end]
QuickSort1(arr, begin, keyi - 1);
QuickSort1(arr, keyi + 1, end);
}
当子区间相等 - 只有一个值,或者 不存在子区间 那么就是递归结束的子问题。
这个过程和遍历二叉树的前序遍历是非常相似的。
2.递归执行的条件
- 进入到PartSort函数的区间至少有两个值
- 如果只有一个值, 或者没有值的话, 就会在进入递归函数之前就 return 了
- 区间是左闭右闭类型的区间
6.5 快排的 时间/空间 复杂度:
快速排序的时间复杂度是怎么计算的呢?
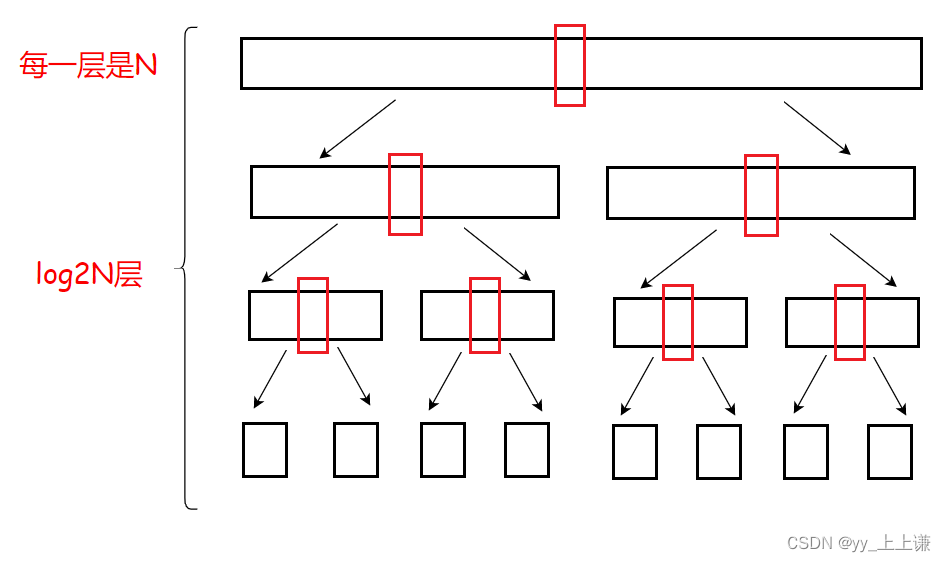
1.最好的情况:
(1)时间复杂度:
- 那么什么情况下才是最好的呢?
- 答案是当每次都是二分的时候就是最好的。
如图画的是快速排序每次key都是中位数的时候的递归展开图:
- 我们知道在有序的序列中每一个值都要将其放在其“正确的位置”上去
- 那么每选一次key就实现了将一个数放在其对应的“正确的位置”
- 所以我们将每个数都用PartSort选出来之后,这个序列就排好了
- 图中,一个红色的方框代表一个key
- 一共有1 + 2 + 4 + …… = 2^h - 1 = N,h = log2(N + 1)可以看成log2N
- 那么一共是有 log2N 层,每一层都要遍历比较N(近似看作N)次
- 所以快排的 时间复杂度:〇(N*log2N)
- 严格来说每一层并不是N,第一层是N,第二层是N - 1,第三层是N - 3,第四层是N - 7……
(2)空间复杂度:
- 因为空间的是可以重复使用的,函数结束调用之后会将创建的栈帧销毁
- 根据快排代码的基本思路是先将key的左区间排完序,再去将key的右区间排有序
- 那么根据代码思路它是一层一层递归,不断地选key,不断地将选出来的key的左区间缩小
- 当左区间不能再分割时,递归就开始往回返,销毁栈帧,开始排右区间
- 排右区间用的栈帧是刚刚左区间销毁的
- 所以从宏观来看左区间的数排完栈帧全部销毁之后,右区间继续用之前销毁的空间
- 所以空间复杂度就为高度次个,空间复杂度:〇(log2N)
2.最坏的情况:
(1)时间复杂度:
- 那么什么情况下才是最坏的呢?
- 答案是当每次调整之后是序列的头或尾的时候最坏。
如图画的是快速排序每次key都是头的时候的递归展开图:
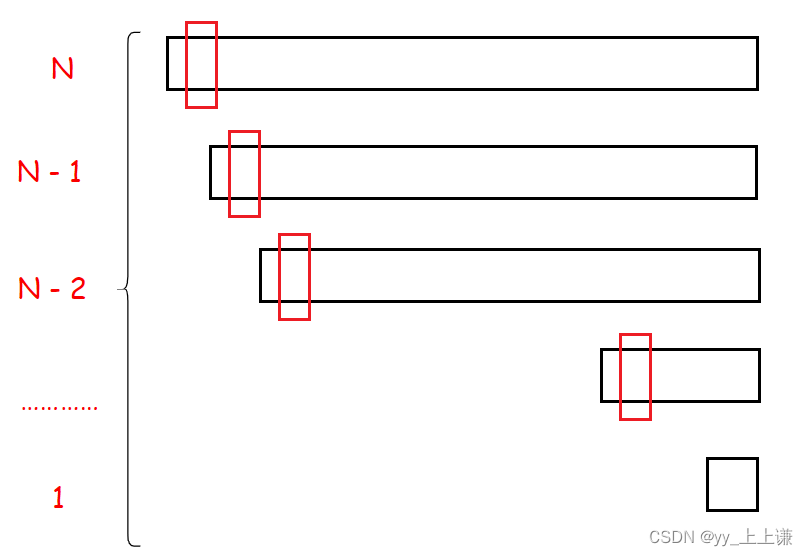
- 如果每次选的key都是在序列的一端的话(如图key每次是在头部)
- 那么每次选一个key,就要遍历一遍序列,一共要选N次key,每次遍历的次数成整差数列
- 那么一共要N + N - 1 + N - 2 + N - 3 + …… + 3 + 2 + 1 近似看作N^2
- 那么最坏的 时间复杂度:〇(N^2)
(2)空间复杂度:
- 因为每次选的key的“正确的位置”都在开头
- 所以key的左区间不存在,只有右区间
- 那么根据代码思路它是一层一层递归,不断地选key
- 不断地将选出来的key的左区间缩小,左递归再完去递归右
- 因为key左区间不存在,所以就一直在对右区间操作
- 照这样右区间一直分割,一直递归,要创建N个栈帧,左区间一直不存在
- 所以空间复杂度就为N个,空间复杂度:〇(N)
注意:
因为排序的过程是在内存中进行的,又因为函数栈帧是在栈区创建的,而栈的大小只有8M左右,当要排的数据过于庞大时,就要创建非常多的函数栈帧,就有栈溢出的风险(爆栈)!!
3.补充:
之前最好的情况中,为什么key每次选在中间是最好的?
假设每次key分的区间正好不是二分:
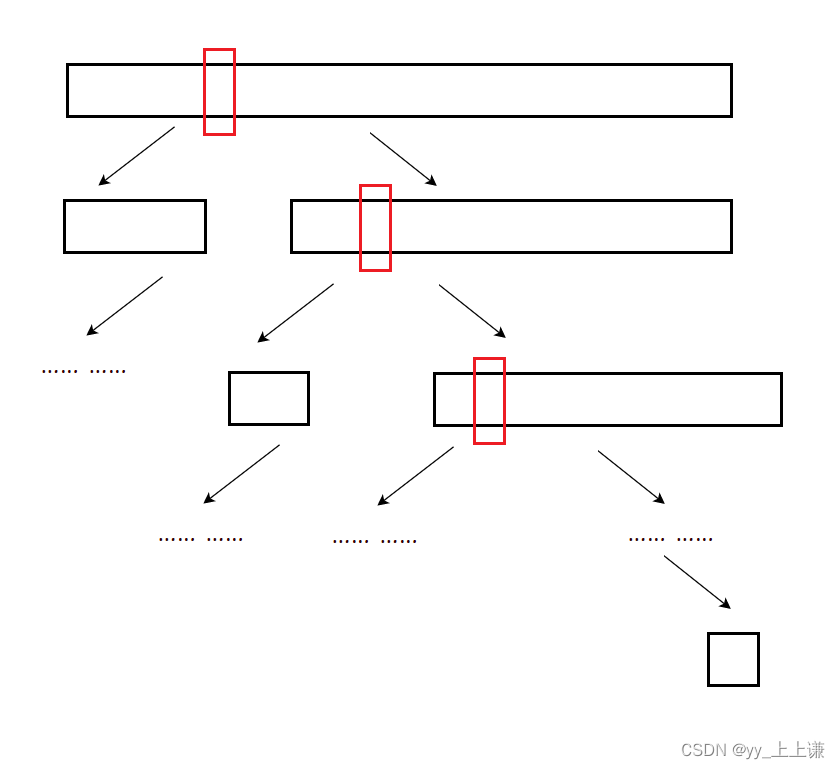
如图所示:
- 假设每次key的位置不是正好在中间将区间二分,而是每次偏离中间的话
- 那么key分出来的左右区间就不一样大了,这时我们可以来个大胆的估算
- 将小的区间忽略掉,那么这种情况就非常类似于key在序列一端时的情况
- 此时的时间复杂度我个人理解应该是:大于最好的〇(N*log2N),并且小于最坏的〇(N^2)
- 具体证明的证明目前不会,但是结论应该是正确的,时间复杂度计算个大概就已经OK了
综上所述:
快速排序的 时间复杂度:在〇(N*logN) ~ 〇(N^2)之间
6.6 快排的优化:
(1)优化一:(三数取中)
在了解完快排的时间复杂度的范围和缺陷之后,我们要想办法将时间复杂度为:〇(N^2)的情况避免掉
- 分析一下什么时候会出现〇(N^2)的情况呢?
- 排完后key每次都在序列一端的时候。
- 那么什么情况下key每次是在序列的一端呢?
- 在排逆序的时候,准确来讲就原来序列已经有序,但是要将其逆序排列的时候。
脑袋里走一走PartSort将key放在正确位置的过程,仔细想一想是不是这么回事!!
既然找到了病根,我们就要对症下药!!
- 既然当序列有序时排逆序时会将key排到序列的一端
- 那么我们选key时就不让那个最小 / 最大的来做key
- 我们在选key时,将序列的 最左端的值,最右端的值,中间的值 三个值中选出中间大的值出来
- 就将中间大的值作为key来排,就可以有效避免大部分key的左右没区间(〇(N^2))的情况了
具体代码如下:
//在数组里面选中间值的下标 - 三数取中
int GetMidIndex(int* arr, int left, int right)
{
//int mid = (left + right) / 2;
int mid = left + ((right - left) >> 1); //防溢出
// left mid right
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{
return mid;
}
else if (arr[left] > arr[right])
{
return left;
}
else
{
return right;
}
}
//right mid left
else // arr[left] > arr[mid]
{
if (arr[mid] > arr[right])
{
return mid;
}
else if(arr[left] < arr[right])
{
return left;
}
else
{
return right;
}
}
}
(2)优化二:(小区间非递归)
小区间优化:
- 实际上快排递归调用展开简化图就是一棵满二叉树(完全二分的情况下)
- 区间很小时,不再继续使用递归划分的思路让它有序,而是直接使用插入排序
- 对小区间排序,减少递归调用,减少函数栈帧的创建
效果不佳:
- 小区间优化其实需求并不是很大, 因为现在的计算机的性能都很高, 小区间的优化不明显
- 快速排序建立栈帧里面存放的是排序过程中要控制的区间
//快速排序 - 加了小区间优化
void QuickSort2(int* arr, int begin, int end)
{
//当子区间相等 - 只有一个值
//或者 不存在子区间 那么就是递归结束的子问题
if (begin >= end)
{
return;
}
//对小区间排序,减少递归调用 - 小区间排序改用插入排序
//小区间直接插入排序控制有序 - 闭区间要 + 1
if (end - begin + 1 <= 13)
{
InsertSort(arr + begin, end - begin + 1);
}
else
{
//int keyi = PartSort1(arr, begin, end);
//int keyi = PartSort2(arr, begin, end);
int keyi = PartSort2(arr, begin, end);
//单趟排序之后, 保证keyi的左边比keyi小,keyi的右边比keyi大
//[begin, keyi - 1] keyi [keyi + 1, end]
QuickSort2(arr, begin, keyi - 1);
QuickSort2(arr, keyi + 1, end);
}
}
6.7 非递归实现快排:(用栈来实现)
???? 栈 还不熟悉的小伙伴点这里来复习一下我之前写的博文:
栈复习 ???? 传送门
在递归版本的快排中,当要排非常多的数时,就很有可能会出现爆栈的风险,这时候我们就要将递归改为非递归,可以有效的避免爆栈这个问题。
虽然我们是用栈来代替递归的,但是非递归的思路还是和递归类似的,递归是划分区间,不断地将左区间分割,结束后再去分割右区间,我们用栈也能很好的模拟这个过程。
1.具体过程:
- 入栈入两个值, 就是两个区间
- 用栈来模拟实现递归, 最小规模子问题就是不入栈
- 出栈也是出两个值,对应一个区间,出一次栈就对一个区间选key
- 虽然不是递归,但是过程模拟的就是递归
- 形似二叉树, 但是没有二叉树的要求
//快速排序 - 非递归版本(用栈改)
void QuickSort3(int* arr, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st))
{
int right = StackTop(&st);
StackPop(&st);
int left = StackTop(&st);
StackPop(&st);
//单趟排
int keyi = PartSort3(arr, left, right);
//[left, keyi - 1] keyi [keyi + i, right]
//左右子区间不一定都要入栈
//只有一个元素或者没有元素的时候就不入栈
//入左区间
if (left < keyi - 1)
{
StackPush(&st, left);
StackPush(&st, keyi - 1);
}
//入右区间
if (keyi + 1 < right)
{
StackPush(&st, keyi + 1);
StackPush(&st, right);
}
}
StackDestroy(&st);
}
核心思想都是将区间分割,将子区间排成有序的,上述代码是想将分割的右区间选key,再选左区间,和二叉树遍历中的根 - 右子树 - 左子树这个过程很相似。
2.快排非递归的写法 和 层序遍历的区别是:
- 层序遍历是一层一层处理完 - 先进先出(用到了 - 队列)
- 快速排序非递归是右边子区间处理完了才去处理左边子区间 - 后进先出(用到了 - 栈)
3.快排的非递归还可以用 队列来实现:
- 快速排序非递归还可以用(队列)实现, 也是相当于一层一层处理的
- 栈的实现是一边一边处理的(左边一下, 右边一下)
???? 7. 归并排序(重点)
7.1 递归实现归并排序:
1.归并排序基本思想:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并排序核心步骤:
- 假设左右区间有序, 直接合并
- 两个有序数组, 归并成一个有序数组
- 取小的尾插到新数组
排序过程:
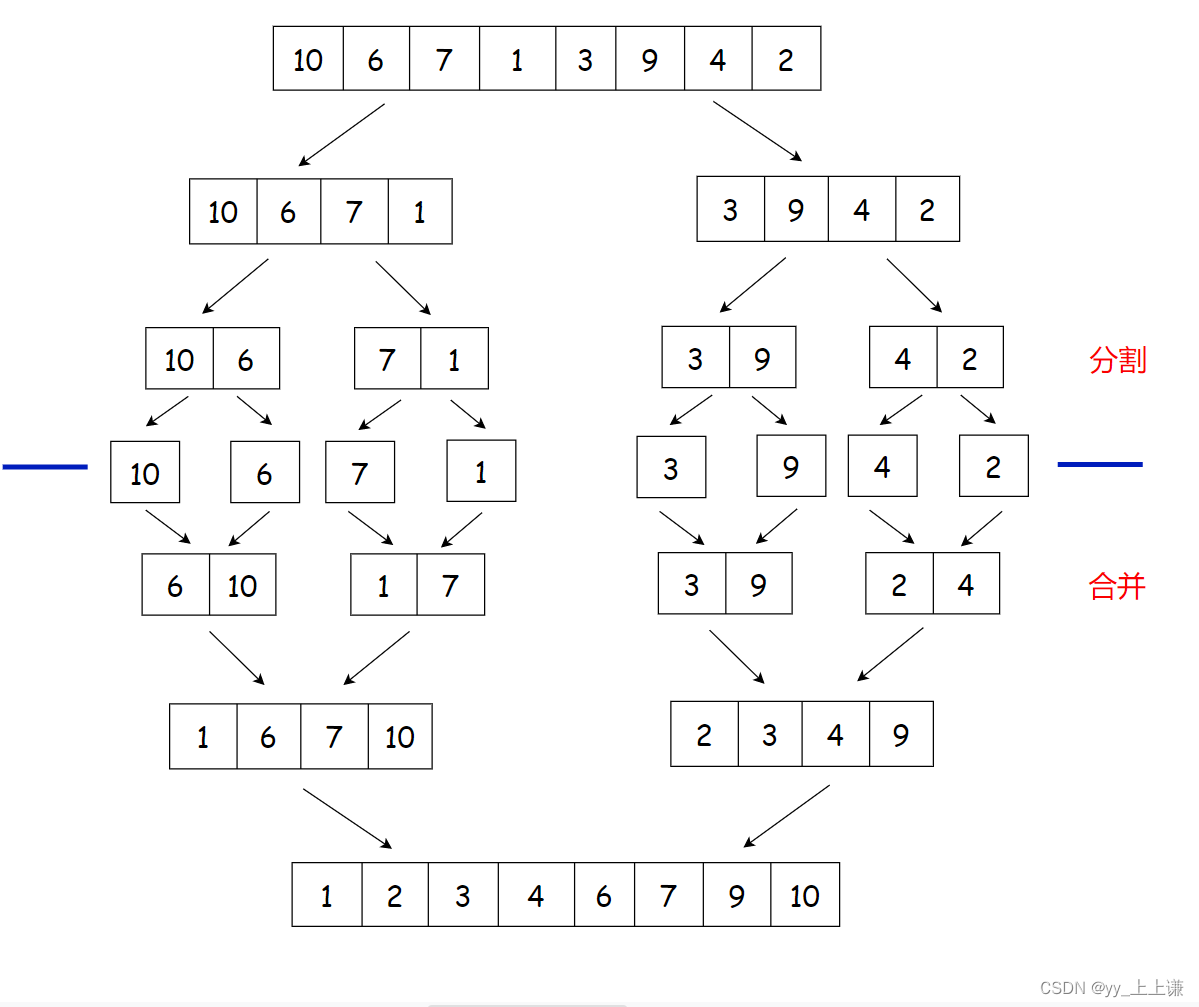
- 将左边的区间分割到不可分割的最小区间
- 再将小区间归并成有序的大区间
- 再将右区间分割到不可分割的最小区间
- 再将小区间归并成有序的大区间
- 最后将两个大区间再次归并成有序的大区间
示意图:
2.问题与解决办法:
- 目前问题: 初始的两个数组没有序
- 解决办法: 分割问题, 用递归来完成, 先分割 - 再归并
- 实际上和 后序遍历 很相似
具体代码实现:
void _MergeSort(int* arr, int begin, int end, int* tmp)
{
if (begin >= end)
{
return;
}
int mid = begin + ((end - begin) >> 1);
// [begin, mid][mid + 1, end]
//左区间
_MergeSort(arr, begin, mid, tmp);
//右区间
_MergeSort(arr, mid + 1, end, tmp);
//归并 [begin, mid][mid + 1, end](左右半边都有序)
//printf("归并[%d, %d][%d, %d]n", begin, mid, mid + 1, end);
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int index = begin;
//归并
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[index++] = arr[begin1++];
}
else
{
tmp[index++] = arr[begin2++];
}
}
//剩余的接上
while (begin1 <= end1)
{
tmp[index++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = arr[begin2++];
}
memcpy(arr + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
//归并排序 - 递归写法
void MergeSort(int* arr, int len)
{
int* tmp = (int*)malloc(len * sizeof(int));
if (tmp == NULL)
{
printf("%sn", strerror(errno));
}
_MergeSort(arr, 0, len - 1, tmp);
free(tmp);
}
printf(“归并[%d, %d][%d, %d]n”, begin, mid, mid + 1, end);可以将每次划分出的区间打印出来
例如排序:
打印出来的是每次递归时划分的区间:
 注意:
注意:
- 归并排序划分区间的时候要格外小心
- 如果是[begin, mid - 1] [mid, end]的话会出现死递归的现象
- 例如: 0 3 mid = 1,右区间:[1, 2]
- 继续划分算出mind: mid = 1, 右区间:[1, 2]
这里的区间划分要考虑到方方面面不然稍不留神就会有爆栈的风险!
7.2 非递归实现归并排序:(用循环来实现)
我们想这里能像快排那里用栈或者队列来代替递归吗?
- 答案是不能或者说是很困难。
那么不能的原因是什么?
- 因为快排分区间的时候是对单独区间操作的
- 而归并排序的时候是需要将两个区间的数归并到一个区间里去
- 用 栈/队列 的话,每次出 栈/队列 的时候就会出一个区间
- 而每次递归的时候要用到两个区间,导致归并的时候找不到两个指定的区间
- 归并的过程相当于二叉树中的后续遍历
- 当然真的想用栈或队列实现的话也是可以的,但是会很麻烦,目前还不会
这里我们采用循环的方式来实现:
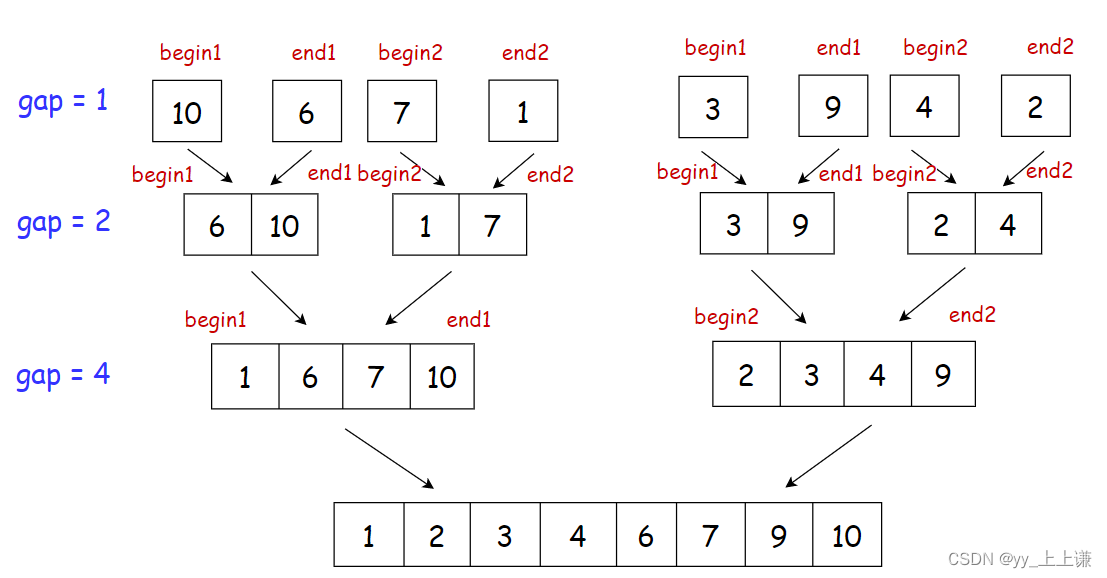
1.具体过程:
- 直接从最小规模问题开始归, 没有借助递归进行分割
- 两个区间两个区间的归并,1 - 1 归, 2 - 2 归, 4 - 4归
- 只要控制好两层循环,内层循环控制好两两归并,外层循环控制好归并的区间
如图所示:
//归并排序 - 非递归写法(用循环改)
void MergeSortNoR(int* arr, int len)
{
int* tmp = (int*)malloc(sizeof(int) * len);
assert(tmp);
int gap = 1;
while (gap < len)
{
//分组归并, 间距为gap的是一组, 两两归并
for (int i = 0; i < len; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//end1 越界, 修正
if (end1 >= len)
{
end1 = len - 1;
}
//begin2 越界, 第二个区间不存在, while就不会进去
if (begin2 >= len)
{
begin2 = len;
end2 = len - 1;
}
//begin2 - OK, end2 - 越界, 修正一下 end2 即可
if (begin2 < len && end2 >= len)
{
end2 = len - 1;
}
//printf("归并[%d, %d][%d, %d] -- gap = %dn", begin1, end1, begin2, end2, gap);
int index = i;
//归并
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[index++] = arr[begin1++];
}
else
{
tmp[index++] = arr[begin2++];
}
}
//剩余的接上
while (begin1 <= end1)
{
tmp[index++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = arr[begin2++];
}
}
memcpy(arr, tmp, len * sizeof(int));
//PrintArray(arr, len);
gap *= 2;
}
free(tmp);
}
2.边界问题
- 边界问题很麻烦,如果数据个数是2的n次方个时, 就不会有问题
- 如果不是, 那么就会出现越界的情况, 因为gap *= 2
- 每次gap += 2 * gap 就会越界
我们以6个数为例:

如上图很明显出现了越界的问题,具体原因如下图:
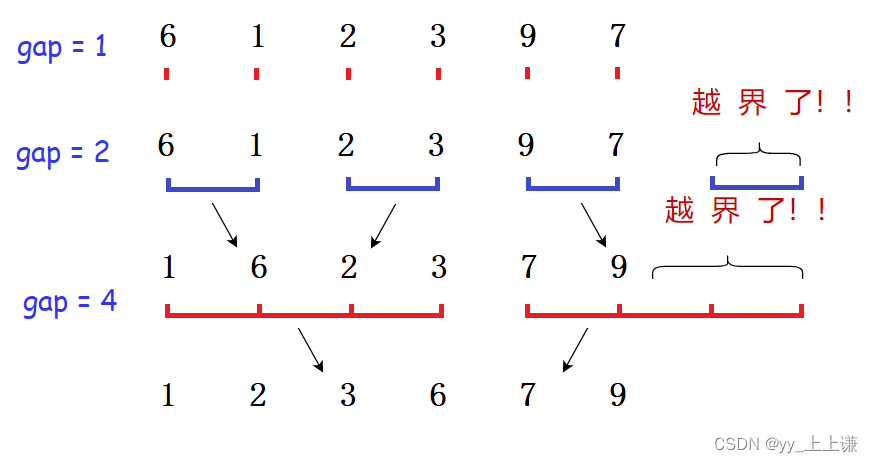
注意:
- 针对这些特殊的越界情况所以我们才要加上边界的限定来修正
- 归并排序时不能只在最后拷贝一次, 因为每次归并的前提条件是有序的
- 每次归并排序完之后都要拷贝, 这样arr数组中递归到的区间才能有序
7.3 归并排序的 时间/空间 复杂度:
1.递归实现:
(1)时间复杂度:
- 归并排序时严格的二分,所以每次递归划分左右区间的时候都是二分划分的
- 那么他的区间递归展开就是一棵满二叉树
- 总的来看每一层都要执行N次,一共log2N层,可参考快排的时间复杂度
- 时间复杂度:〇(N * log2N)
(2)空间复杂度:
- 递归最多展开log2N层,和快排二分划分区间时的空间复杂度一样,再加上额外开辟的tmp数组
- 空间复杂度:〇(N + log2N)
2.非递归实现:
(1)时间复杂度:
- 非递归实现只是换了一种方法,但是思想还是和递归一样的,所以时间复杂度没变
- 时间复杂度:〇(N * log2N)
(2)空间复杂度:
- 非递归只开辟了额外的tmp数组,并没有递归创建栈帧,所以
- 时间复杂度:〇(N)
7.4 归并排序的外排序:
1.排序的划分
- 内排序: 数据在内存中排序 - 快 (数组存储: 下标随机访问)
- 外排序: 数据在磁盘上排序 - 数据很大, 比如10亿个数 (磁盘上的数据: 串行访问)
归并排序既可以做 内排序, 又可以做 外排序。
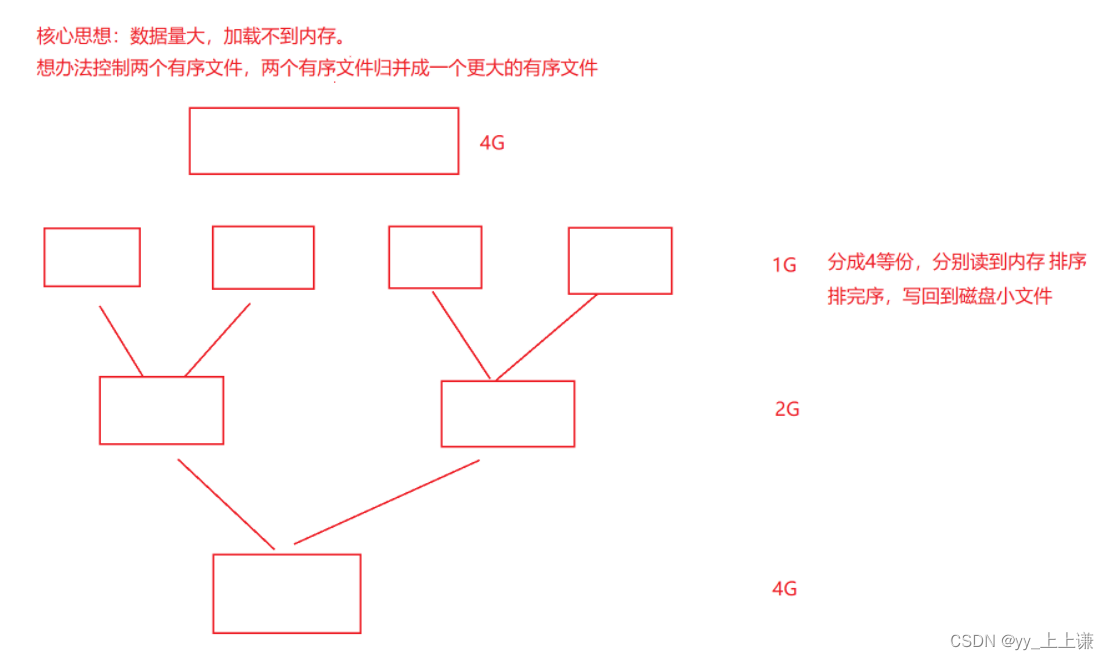
2.归并实现外排序的方法:
- 程序也可以访问磁盘上的数据 - 访问形式(文件)
- 核心思想: 数据太大, 加载不到内存。
- 想办法控制两个有序小文件, 两个有序文件归并成一个更大的有序文件
- 4G大小的数据排序: 分成4等份, 分别读到内存, 排序写成几个小文件
- 排完序, 写回到磁盘小文件
???? 8. 计数排序
1.核心思想:
- 遍历原数组, 一个 val 的出现几次, 它映射在另一个数组(新开辟的)的对应位置
- 对应的位置的值从0开始++,统计每个数出现的次数
- 再遍历另开的数组,将数据写回原数组
2.缺陷:
- 绝对映射: 假设要排序的数是从5000之后开始的
- 前5000个位置没有映射, 空间浪费了
- 相对映射:
- 用范围来映射
//计数排序
void CountSort(int* arr, int len)
{
int min = arr[0], max = arr[0];
for (int i = 1; i < len; i++)
{
if (arr[i] < min)
{
min = arr[i];
}
if (arr[i] > max)
{
max = arr[i];
}
}
int range = max - min + 1;
//开范围大的数组
int* countA = (int*)malloc(sizeof(int) * range);
assert(countA);
memset(countA, 0, sizeof(int) * range);
//计数 - 遍历一遍数组
for (int i = 0; i < len; i++)
{
countA[arr[i] - min]++;
}
//排序 - 遍历开辟的数组
int j = 0;
for (int i = 0; i < range; i++)
{
while (countA[i]--)
{
arr[j++] = i + min;
}
}
}
8.1 计数排序的 时间/空间 复杂度:
1.时间复杂度:
- 遍历原数组找出 最大/最小 值 时间复杂度:〇(N)
- 遍历原数组计数,时间复杂度:〇(N)
- 写会原数组,时间复杂度:〇(range + N)
综上所述:
计数排序的时间复杂度为:
- 精确时间复杂度:〇(range + 3N)
- 粗略估计:时间复杂度:〇(range + N)
2.空间复杂度:
- 空间复杂度:〇(range)
???? 9. 测试排序的性能
随机给大量个随机数,将它们排序,用clock函数计算出该排序算法排序用的时长(毫秒):
具体代码:
// 测试排序的性能对比
void TestOP()
{
srand((unsigned int)time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
int* a8 = (int*)malloc(sizeof(int) * N);
assert(a1 && a2 && a3 && a4 && a5 && a6 && a7 && a8);
for (int i = 0; i < N; i++)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
a8[i] = a1[i];
}
int begin1 = clock();
BubbleSort(a1, N);
int end1 = clock();
int begin2 = clock();
SelectSort(a2, N);
int end2 = clock();
int begin3 = clock();
InsertSort(a3, N);
int end3 = clock();
int begin4 = clock();
ShellSort(a4, N);
int end4 = clock();
int begin5 = clock();
HeapSort(a5, N);
int end5 = clock();
int begin6 = clock();
QuickSort2(a6, 0, N - 1);
int end6 = clock();
int begin7 = clock();
MergeSort(a7, N);
int end7 = clock();
int begin8 = clock();
CountSort(a8, N);
int end8 = clock();
printf("BubbleSort:%dn", end1 - begin1);
printf("SelectSort:%dn", end2 - begin2);
printf("InsertSort:%dn", end3 - begin3);
printf("ShellSort:%dn", end4 - begin4);
printf("HeapSort:%dn", end5 - begin5);
printf("QuickSort:%dn", end6 - begin6);
printf("MergeSort:%dn", end7 - begin7);
printf("CountSort:%dn", end8 - begin8);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
free(a8);
}
各排序时长结果:
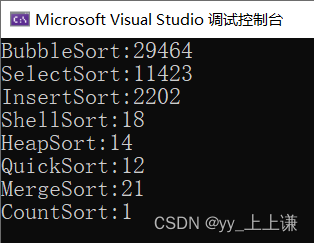
从图中我们可以清楚地看到各个排序算法的优劣性。
补充:
- 计数排序可以排负数 - (在相对映射的情况下)
- 其他类型就不行了
- 计数排序排 浮点数 和 字符串 是不行的
???? 10. 稳定性 + 总结
10.1 稳定性:
1.概念:
- 稳定性,不是性能波动
- 而是两个相同的数排过序之后相对于原来的位置是否发生变化
- 例如,1,1两个数排序,排完序之后:
- 若第一个1还在第二个1的前面,第二个1还在第一个1后面的话,说明这个排序是稳定的,反之亦然
- 所以稳定性看的是相对位置
2.各大排序的稳定性:
- 插入排序, 冒泡排序, 归并排序 - 堆排序 - 稳定
- 计数排序的稳定性: 不知道数值原来对应的位置
- 所以说计数排序的稳定性没意义
注意:
选择排序不是稳定的:
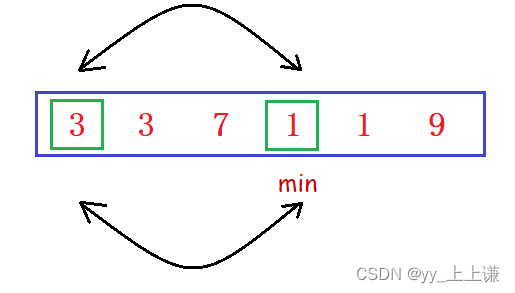 如上图排升序,当找到最小值1时和3交换,1是稳定的而3却不是稳定的。
如上图排升序,当找到最小值1时和3交换,1是稳定的而3却不是稳定的。
这一点在很多资料和书籍中讲的都是错误的。
10.2 总结:
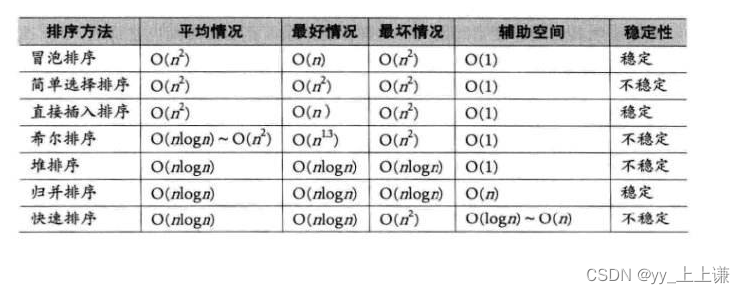
1.具体如下表格:
最后
以上就是贪玩心锁最近收集整理的关于【数据结构】手撕 - 八大排序 ,万字详解~???? 前言???? 1. 冒泡排序(咕噜咕噜)???? 2. 选择排序???? 3. 插入排序???? 4. 希尔排序???? 5. 堆排序???? 6. 快速排序(重点)???? 7. 归并排序(重点)???? 8. 计数排序???? 9. 测试排序的性能???? 10. 稳定性 + 总结的全部内容,更多相关【数据结构】手撕内容请搜索靠谱客的其他文章。








发表评论 取消回复