本篇文章主要通过一个简单的例子来实现神经网络。训练数据是随机产生的模拟数据集,解决二分类问题。
下面我们首先说一下,训练神经网络的一般过程:
1.定义神经网络的结构和前向传播的输出结果
2.定义损失函数以及反向传播优化的算法
3.生成会话(Session)并且在训练数据上反复运行反向传播优化算法
要记住的一点是,无论神经网络的结构如何变化,以上三个步骤是不会改变的。
完整代码如下:
import tensorflow as tf
#导入TensorFlow工具包并简称为tf
from numpy.random import RandomState
#导入numpy工具包,生成模拟数据集
batch_size = 8
#定义训练数据batch的大小
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#分别定义一二层和二三层之间的网络参数,标准差为1,随机产生的数保持一致
x = tf.placeholder(tf.float32,shape=(None,2),name='x-input')
y_ = tf.placeholder(tf.float32,shape=(None,1),name='y-input')
#输入为两个维度,即两个特征,输出为一个标签,声明数据类型float32,None即一个batch大小
#y_是真实的标签
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#定义神经网络前向传播过程
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#定义损失函数和反向传播算法
rdm = RandomState(1)
dataset_size = 128
#产生128组数据
X = rdm.rand(dataset_size,2)
Y = [[int(x1+x2 < 1)] for (x1,x2) in X]
#将所有x1+x2<1的样本视为正样本,表示为1;其余为0
#创建会话来运行TensorFlow程序
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
#初始化变量
sess.run(init_op)
print(sess.run(w1))
print(sess.run(w2))
#打印出训练网络之前网络参数的值
STEPS = 5000
#设置训练的轮数
for i in range(STEPS):
start = (i * batch_size) % dataset_size
end = min(start+batch_size,dataset_size)
#每次选取batch_size个样本进行训练
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
#通过选取的样本训练神经网络并更新参数
if i%1000 == 0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y})
print("After %d training step(s),cross entropy on all data is %g" % (i,total_cross_entropy))
#每隔一段时间计算在所有数据上的交叉熵并输出,随着训练的进行,交叉熵逐渐变小
print(sess.run(w1))
print(sess.run(w2))
#打印出训练之后神经网络参数的值
运行结果如下:
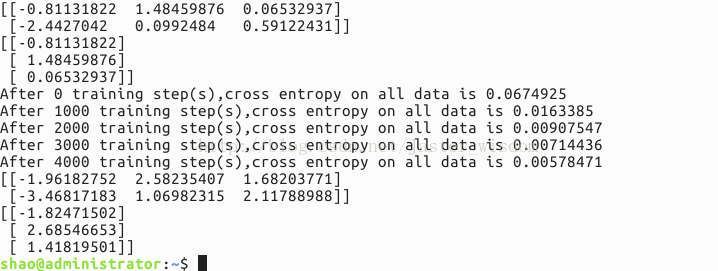
结果说明:
首先是打印出训练之前的网络参数,也就是随机产生的参数值,然后将训练过程中每隔1000次的交叉熵输出,发现交叉熵在逐渐减小,说明分类的性能在变好。最后是训练网络结束后网络的参数。
分享一个图形化神经网络训练过程的网站:点这里,可以自己定义网络参数的大小,层数以及学习速率的大小,并且训练过程会以很直观的形式展示出来。比如:
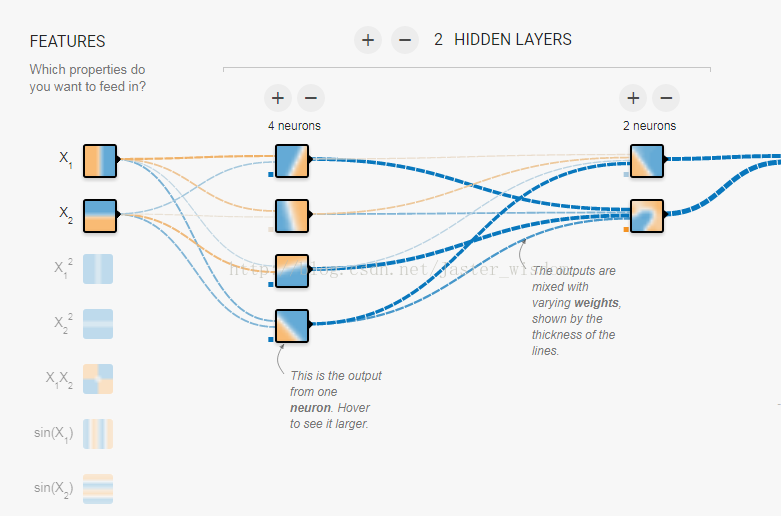
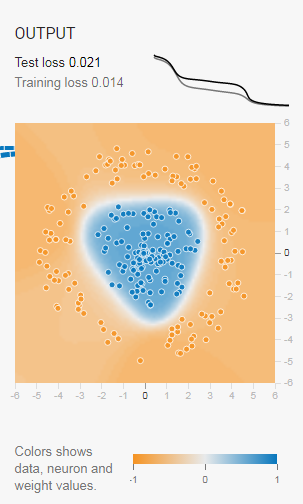
以上对于神经网络训练过程可以有一个很深刻的理解。
最后,再补充一些TensorFlow相关的知识:
1.TensorFlow计算模型-计算图
Tensor表示张量,可以简单的理解为多维数据结构;Flow则体现了它的计算模型。Flow翻译过来是“流”,它直观地表达了张量之间通过计算相互转换的过程。TensorFlow中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
指定GPU方法,命令如下:
import tensorflow as tf a = tf.constant([1.0,2.0],name=“a”) b = tf.constant([3.0,4.0],name=“b”) g = tf.Graph() with g.device(/gpu:0): result = a + b sess = tf.Session() sess.run(result)
2.TensorFlow数据模型-张量
张量是管理数据的形式。零阶张量表示标量,第一阶张量为向量,也就是一维数组,一般来说,第n阶张量可以理解为一个n维数组。张量本身不存储运算的结果,它只是得到对结果的一个引用。可以使用tf.Session().run(result)语句来得到计算结果。
3.TensorFlow运行模型-会话
我们使用session来执行定义好的运算。
主要有以下两种方式,第一种会产生内存泄漏,第二种不会有这种问题。
#创建一个会话 sess = tf.Session() sess.run(…) #关闭会话使得本次运行中使用的资源得到释放 sess.close()
第二种方式是通过Python的上下文资源管理器来使用会话。
with tf.Session() as sess: sess.run(…)
此种方式自动关闭和自动进行资源的释放
4.TensorFlow-神经网络例子
使用神经网络解决分类问题可以分为以下四个步骤:
①提取问题中实体的特征向量作为输入。
②定义神经网络的结构,并定义如何从神经网络的输入得到输出。这个过程就是神经网络的前向传播算法。
③通过训练数据来调整神经网络中参数的设置,这就是训练网络的过程。
④使用训练好的神经网络来预测未知的数据
在TensorFlow中声明一个2*3的矩阵变量的方法:
weight = tf.Variable(tf.random_normal([2,3],stddev=2))
即表示为方差为0、标准差为2的正态分布
在TensorFlow中,一个变量的值在被使用之前,这个变量的初始化过程需要被明确调用。一下子初始化所有的变量
sess = tf.Session()
init_op = tf.initialize_all_variables()
或者换成init_op = tf.global_variables_initializer()也可
sess.run(init_op)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
最后
以上就是友好豆芽最近收集整理的关于TensorFlow平台下Python实现神经网络的全部内容,更多相关TensorFlow平台下Python实现神经网络内容请搜索靠谱客的其他文章。








发表评论 取消回复