声明:本文来自于微信公众号 机器之心(ID:almosthuman2014),作者:机器之心,授权靠谱客转载发布。
最近的一系列研究表明,纯解码器生成模型可以通过训练利用下一个 token 预测生成有用的表征,从而成功地生成多种模态(如音频、图像或状态 - 动作序列)的新序列,从文本、蛋白质、音频到图像,甚至是状态序列。
能够同时生成多种模态输出的多模态模型一般是通过某种形式的词汇扩展(将多模态表征转换为离散 token 并添加到模型的基本词汇表中)来实现的,即在预训练阶段或在后期微调阶段进行跨模态对齐。
多模态预训练方法具有很强的性能优势(例如,一个模型可以原生理解多种模态),但也有缺点。例如,无法解决如何在预训练后添加新模态的问题,也缺乏灵活性,因为添加另一种模态需要从头开始训练一个新的模型,并进行超参数搜索,以获得模态之间的最佳训练数据混合比。因此,这种解决方案不适合小众模态,特别是 IMU、蛋白质序列等。
或者,将词汇扩展到另一种模态可以在一个从未见过该模态的模型上进行预训练后进行。只在文本模态下训练的解码器模型可以在上下文中遵循指令并从样本中学习,通常是通过微调将另一种模态(如音频或图像功能)嫁接到现有的强大文本骨干上,以利用文本模态的可表达性和人类用户的可控性。这样做的缺点是骨干网络的文本到文本功能会被破坏,由此产生的模型只能执行其经过微调的跨模态任务。
总体来说,无论是预训练还是微调,都需要大量对齐的跨模态数据,因此这两种方法都不适用于没有足够数量以对齐多模态数据的模态。
Google DeepMind 近期提出了模块化设计的新型架构 Zipper,它由多个单模态预训练解码器模型组成。利用丰富的无监督单模态数据,Zipper 可以在单一模态中预训练强大的纯解码器模型,然后利用交叉注意力将多个这样的预训练解码器「压缩」在一起,并利用有限的跨模态数据进行微调,实现多模态生成能力。预训练的纯解码器模型可以在新的多模态组合中灵活地重复使用和再利用。

论文标题:Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities
论文链接:https://arxiv.org/pdf/2405.18669
这是第一项研究灵活组合模态的工作,通过组合单独预训练的单模态解码器来实现多模态生成能力。
虽然 Zipper 架构可在多种模态和两种以上模态的骨干上通用,但这项工作的重点放在了仅融合两种骨干(语音和文本)的实验设置上。论文展示了 Zipper 在同时跨模态生成文本(自动语音识别(ASR)任务)和语音(文本到语音任务(TTS))方面的强大能力。
仅使用部分文本 - 语音对齐数据(低至原始数据的1%)进行的实验表明,首先在无标记数据上对骨干进行单模态预训练,与使用词汇扩展方法进行微调相比,Zipper 可以依赖更少的对齐数据,这为使用解码器 - 解码器架构融合模态提供了可能性,对于成对数据量有限的生成任务非常有用。
接下来,让我们看看论文细节。
模型
Zipper 架构由两个自回归解码器 tower(或主干)组成,它们通过门控交叉注意力层「压缩」在一起。每个骨干使用下一个 token 预测功能分别对单个模态进行训练。
图1显示了 Zipper 架构的概览。与 CALM 类似,在解码器骨干之间的每 i 层都插入了交叉注意力层。在这些有规律交错的层中,一种模态的表征被交叉注意力到另一种模态中。这与 Flamingo [4] 编码器 - 解码器设置不同,后者只在一个 tower(编码器)的最后一层定期交叉注意力到另一个 tower(解码器)的各层。
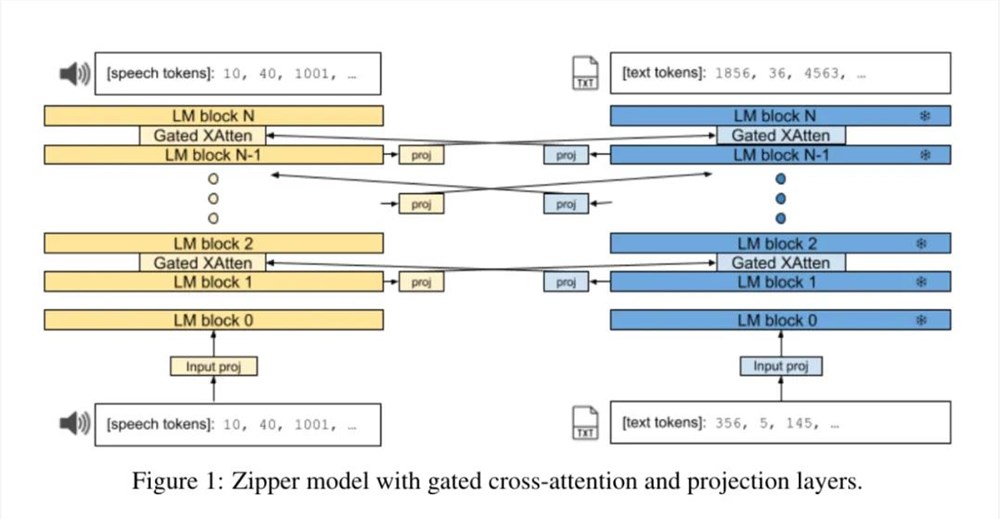
在交叉注意力过程中,投影层被插入模态之间。从功能上讲,这可以均衡骨干之间的嵌入维度大小差异。从语义上讲,它还能实现从一种模态到另一种模态的表征转换,尤其是当一个或两个骨干被冻结时。此外,在每个骨干网的输入嵌入之后,还直接加入了一个非线性输入投影层,以便更好地调整输入的单模态表征,用于多模态任务。
在第一个 Transformer 块之前(嵌入层之后),插入两个可学习的多层感知器(MLP)投影,然后对每个骨干进行 ReLU 转换:

这样做是为了让单模态表征更好地适应多模态设置。
让 i_A 和 i_B 分别代表 A 层交叉到 B 层和 B 层交叉到 A 层的间隔。将 k 层单模解码器 A 的隐藏表征法称为
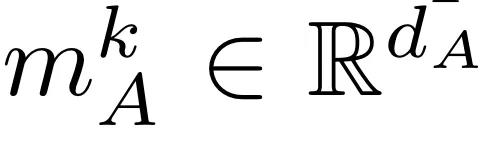
,其中 d_A 是 transformer A 的隐藏维度;同样,将 l 层单模解码器 B 的隐藏表征法称为
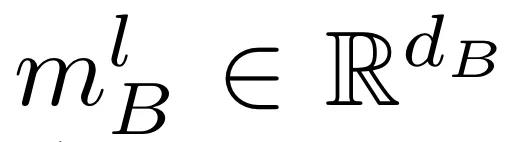
,其中 d_B 是 transformer B 的相应隐藏维度。设 fcross (Q, K, V ) 是来自 [4] 的门控交叉注意力层,其后是前馈层,Q、K、V 分别是查询、键和值。让
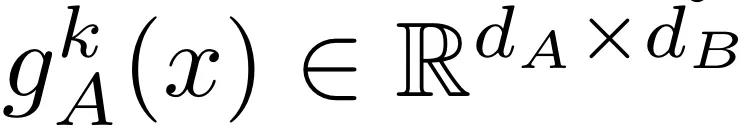
和
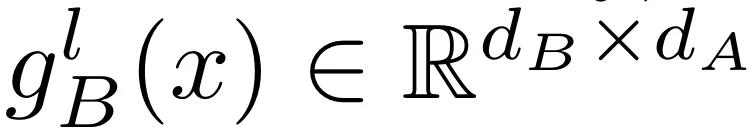
分别代表 tower A 和 tower B 的线性前馈投影和全连接投影。
解码器 A 中第 k 层的新表征
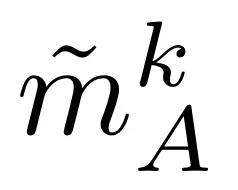
。
具体如下:
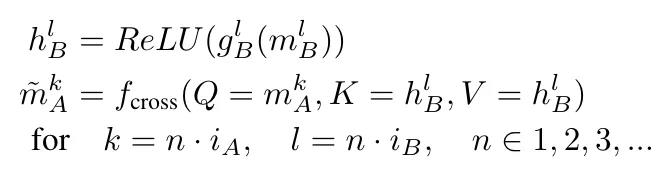
同样,解码器 B 第 l 层的新表征
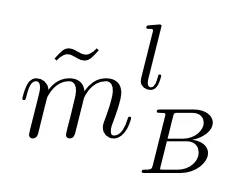
为:
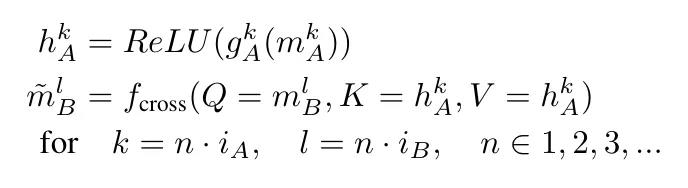
最后,每个 tower 以一个 softmax 层(与同 tower 嵌入层共享)结束,以便利用下一个 token 预测任务将隐藏表征投射到(特定模态 /tower)token 词汇的概率分布中。
研究者将交叉注意力机制用于交错序列的自动回归训练,具体做法是只交叉关注原始线性序列中当前位置之前的另一种模态的数据。
在解码过程中,输出模态的序列是指定的(例如,[语音]、[文本]、[文本、语音])。模型以序列中的第一种模态生成输出,直到遇到特殊的句末 token,这时才会切换到序列中的下一种模态。该过程一直持续到序列中的所有模态都被解码为止。虽然可以扩展模型自动选择输出生成的模态,但这一设置的通用化还需要后续的工作。
实验
虽然 Zipper 可以扩展到任意数量的模态,研究者率先评估了语音到文本生成和文本到语音(TTS)生成的自动语音识别(ASR)。
值得注意的是,虽然对 TTS 系统(合成语音)的标准评估依赖于人类反馈(平均意见分数),可以捕捉到语音的许多整体方面(如文本保真度和声音质量等),但这里的 TTS 评估只希望捕捉到架构选择对语义 token 建模和预测能力的影响。
表1列出了 ASR 任务的测试结果:
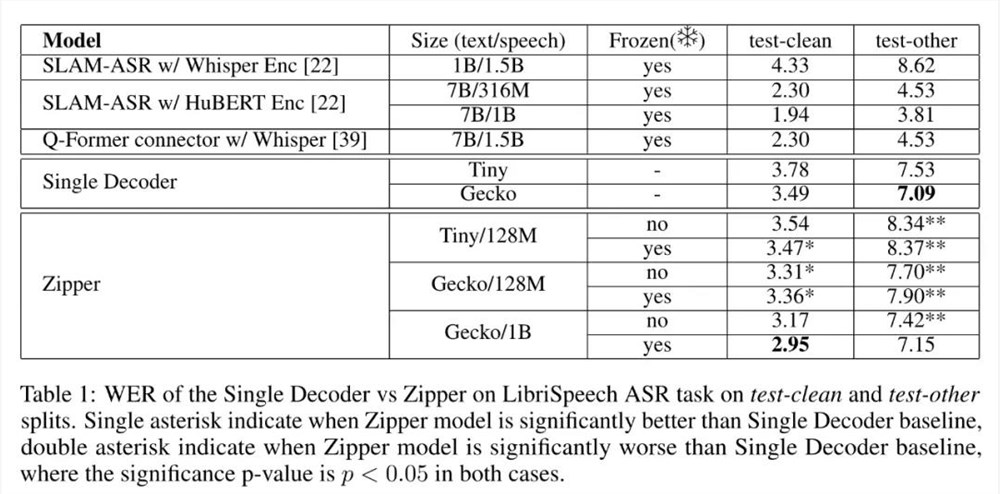
将 Zipper 与扩展词汇量的单解码器基线进行比较时,可以发现 Zipper 在 test-clean 子集上的性能略好,而在噪音较高的语音 test-other 子集上的性能则略有下降,总体性能相当接近。
表2列出了在 LibriTTS 数据集的 test-clean 分割上进行 TTS 任务的结果。
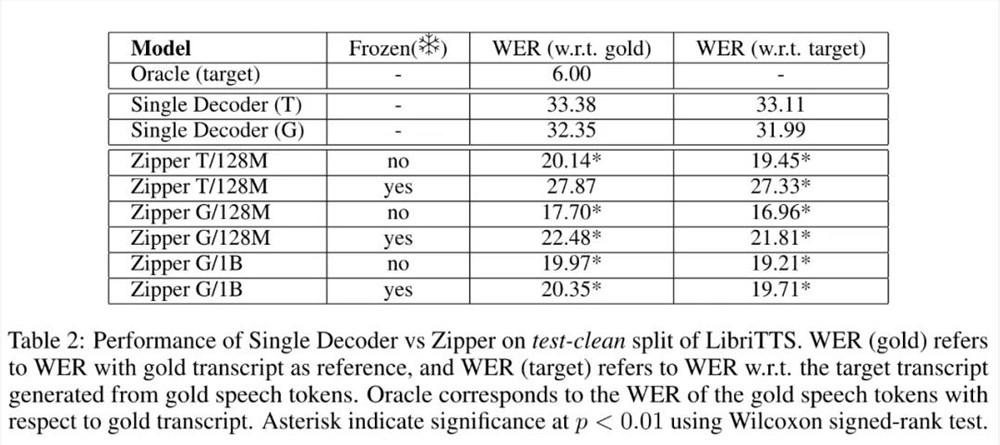
可以看出,Zipper 模型明显优于单解码器模型,Zipper S/128M unfrozen model 模型提高了13个 WER 点(相对误差减少40%),Zipper L/1B unfrozen model 模型提高了12个 WER 点(相对误差减少38%)。
研究者还观察到,与使用冻结骨干网络相比,在训练过程中解冻语音骨干网络可持续改善所有尺寸 Zipper 模型的性能,这验证了直觉 —— 微调语音骨干网络的参数比仅依赖交叉注意力产生的模态对齐效果更好。
更多研究细节,可参考原论文。
(举报)








发表评论取消回复