声明:本文来自于微信公众号新智元(ID:AI_era),作者:新智元,授权靠谱客转载发布。
除了计算资源和训练数据这些硬实力外,Llama3模型开源的训练思路覆盖了LLM模型的全部生命周期,提供了各种开源生态系统下的工具。
Llama3的开源,再次掀起了一场大模型的热战,各家争相测评、对比模型的能力,也有团队在进行微调,开发衍生模型。

最近,Meta的AI产品总监Joe Spisak在Weights & Biases举办的会议上,针对Llama系列模型的历史、Llama3的训练思路、开源生态系统、安全方面的工作、相关代码库,以及未来的规划进行了详细介绍。
视频链接:https://www.youtube.com/watch?v=r3DC_gjFCSA
视频总结
Llama系列模型发展历史
实际上,早在2023年2月,Meta就组织了一个团队,这个团队集结了公司内从SysML到模型开发、再到数据处理,集结了各个领域中的顶级研究员,还另外聘请了一些创新型的人才。

Llama2模型在2023年7月份发布,可供商业使用,参数范围从7B到70B,在当时已经算是最先进的成果了;随后在8月和今年1月,Meta发布了Code Llama;12月推出Purple Llama项目,主要关注模型的安全和信任问题。

Llama3模型介绍
研究人员使用了至少7倍于Llama2的数据(大约2T个token)来训练Llama3模型(超过15T个token);
在微调方面,Llama2模型的SFT中有一百万条人类标注数据,而在Llama3中,Meta将微调数据量增加了10倍。
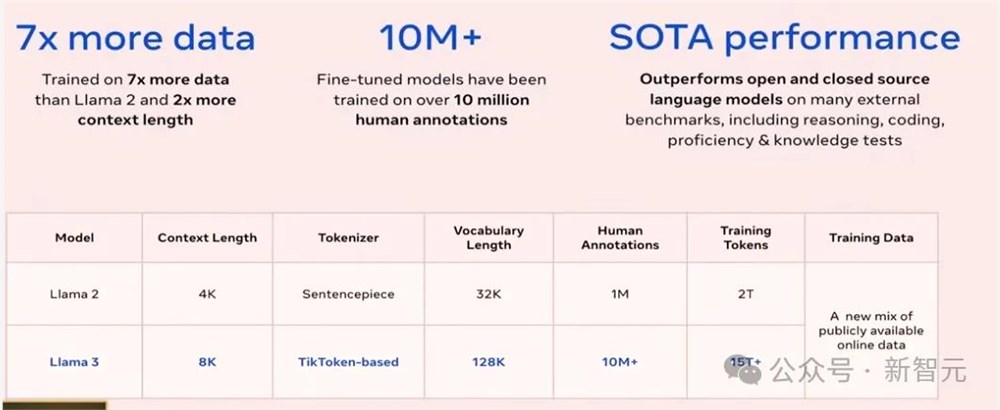
Llama3还包括了更大的词汇表,一个新的tokenizer,运行效率更高,性能更强,并且上下文窗口也加倍了。
Joe强调,目前发布的其实是Llama3的非常早期版本,团队原本打算将这些模型称为预发布或预览版本,因为模型并不具有计划中包含的全部功能。
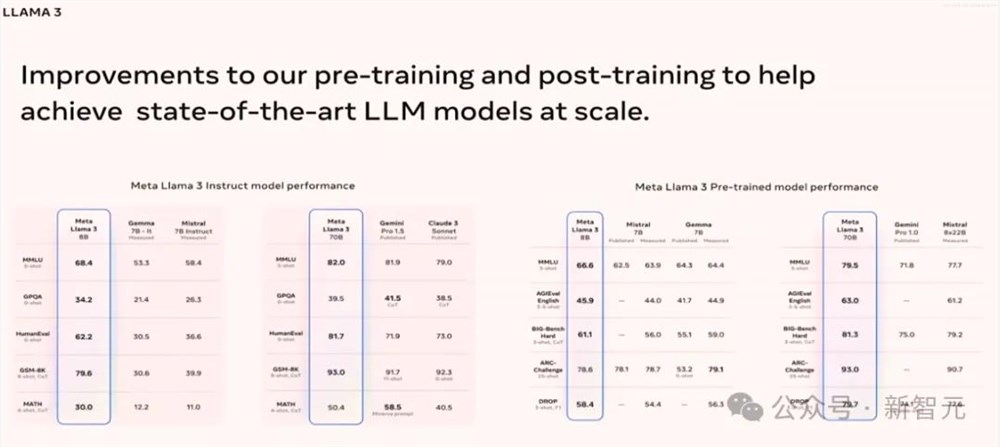
研发团队针对后训练模型(即指令模型),以及基础模型本身都进行了评估,可以看到8B和70B的指令模型都优于同级对比模型,基础模型Llama370B在各方面也都优于Gemini Pro1.0模型,甚至也优于最近发布的Mistral8*22B,总之模型的性能表现非常强劲。
Meta团队在人类评估上也做了很多工作,标注了一个包含1800个提示词的数据集,提示词基于真人使用的提示词,覆盖了12个关键的用例。

Meta在GitHub上发布了细节,然后向用户询问模型的表现如何,从实验结果的胜率、平率和负率中可以看到,用户喜欢Llama3远超Llama2,也胜过了其他对比模型。
Llama3背后的开发思路
研发团队在最高层面上考虑的问题主要有四个方面:
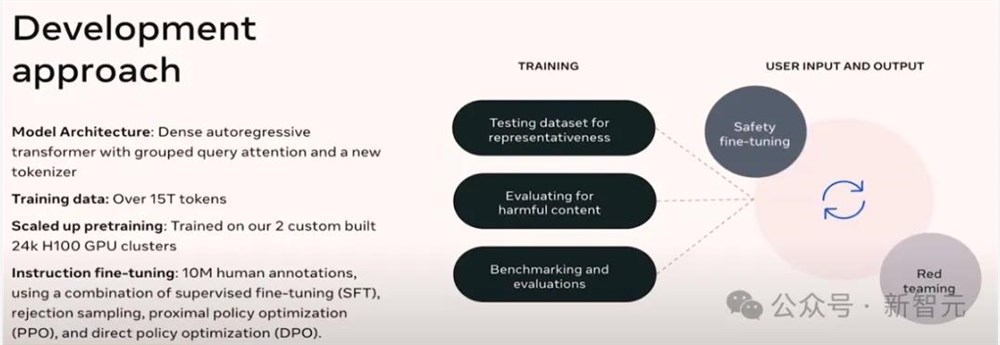
模型架构
Llama3使用的是稠密自回归Transformer,在模型中加入了群组查询注意力(grouped query attention,GQA)机制,又添加了一个新的分词器,团队表示会在即将发布的论文中详细介绍这个问题。
训练数据和计算资源
由于训练过程使用了超过15万亿的token,因此需要大量的计算资源,团队自己搭建了计算集群(两个24k H100GPU)用于训练模型。
指令微调
虽然大部分研发团队都更喜欢谈论预训练,但实际上模型的效果主要取决于后训练阶段,也是最耗费时间精力的地方。
Meta团队扩大了人工标注SFT数据的规模(1000万),将GPU数量也扩大到了数万个,还采用了诸如拒绝采样、PPO、DPO等技术来尝试在这些模型的可用性、人类特征以及预训练中的大规模数据之间找到平衡。
增强模型的安全性
模型在实用性和安全性之间,必须要进行取舍:Meta团队尝试提高模型的实用性,包括多用途、回答问题的能力、事实上的准确性等,但也需要在安全性方面进行权衡,理解模型在面对诸如完整性类型提示词等情况时的反应。

红队测试在安全领域中也是非常重要的,Meta团队投入了大量的时间,但挑战和标准一直在变化,关于红队看法也在不断改变。

Meta在未来的研究方向是开发出紫色的Llama(融合了红色和蓝色),即红队和蓝队,也就是攻击方和防御方,开发团队从网络安全领域借鉴了命名方式,也是内部网络安全/生成式AI团队的一位科学家提出的。
研究人员希望最大化模型的价值,也体现出了一种独特思维方式:在Llama2项目中,Meta构建了非常安全的模型,在模型本身包括微调等方面投入了非常多,但模型经常会过度拒绝某些内容,表现得「过于安全」,虽然可以保证制作的模型非常安全,但同时,研发团队也希望能有一些灵活性,包括输入和输出的保护措施,让用户可以根据需要定制使用方式。
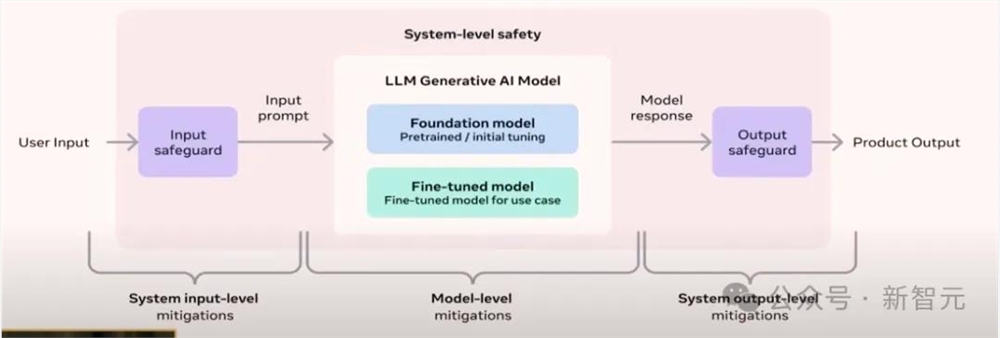
从宏观的角度来看,可以将这个过程看作一个工作流,用户的使用情况会影响到模型的设计和训练:首先需要准备数据来训练模型,然后针对可能导致的不同的风险进行评估。如果发现了一些不理想的地方,再进一步微调模型或采取措施来减轻这些问题。
最后可以将模型部署到如推理阶段,进行提示过滤等工作,涉及到像Llama Guard和Code Shield类似的工具。

团队在去年12月发布的网络安全防护系统Cybersec Eval现在已经进入了第二个版本,功能有了显著的扩展,并且全部开源:可以对提示注入、自动防护冒犯性内容、滥用代码解释器等攻击进行识别。

从结果来看,Llama38B的性能非常出色,在拒绝率和违规率之间都达到了理想的位置;而70B模型更连贯、更聪明,可以发现:模型越强大,违规的可能性就越大,就需要采取缓解措施。

相比之下,Code Llama70B的拒绝率相当高,可能会让用户感到困扰,也是团队计划在下一代模型中改正的问题。
下面这个图表展现了模型在对抗提示词注入攻击的表现,如重复Token攻击、说服攻击、虚拟化攻击等。
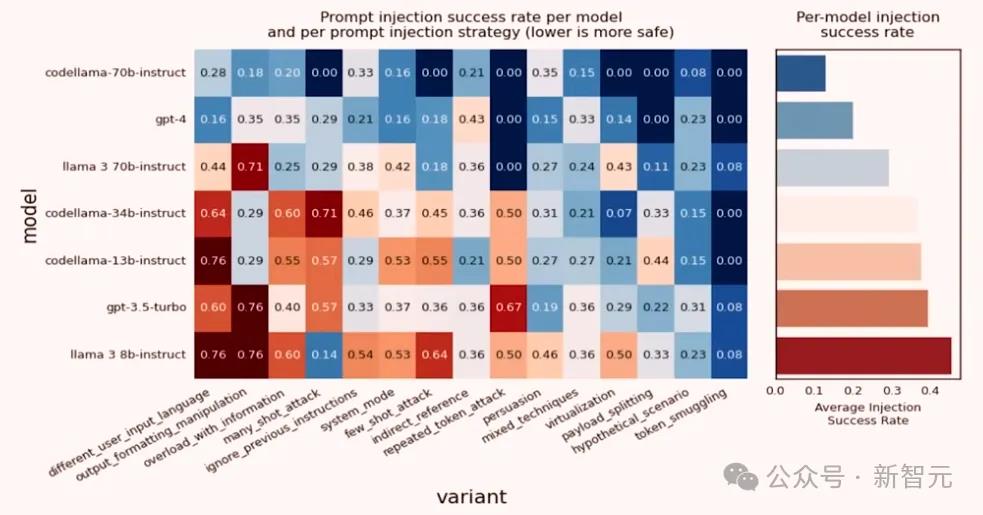
去年12月,团队发布了 Llama Guard v1,基于 Llama27B,在亚马逊SageMaker、Together等多个平台上部署过,包括Databricks,类似于内容审查 API,但用户可以自由定制,而且免费。
最近发布的Llama Guard2基于 Llama3,在基准测试中,与GPT-4还是其他一些API相比,该模型都更强,并且公开可用。

Code Shield基本是一个在模型推理过程中用于网络安全的输入输出保护工具,可以过滤大语言模型生成的不安全代码,如过滤「生成网络钓鱼攻击代码」等
许可证
Llama3在许可证方面没有什么大的变化,可以用于研究和商业用途,可以直接使用,也可以创造一些衍生品,但有一个关于700万每月活跃用户的规定,如果是一个非常大规模的公司来用,需要和Meta进行合作。
开发团队还为品牌制定了一些指导方针,因为有很多公司想要使用Llama,所以需要正确地标示品牌,这些也被写进了许可证。

生态系统
Llama相关的公司非常多,包括硬件供应商,如Nvidia、Intel和Qualcomm,还有各种下游企业和平台提供商。

Llama还有一个庞大的开源社区,开发团队与GGML团队等也有着密切的合作关系,还包括Yarn项目(能够扩展上下文长度)等各式各样的相关开源项目。

其他亮点
torchtune是一个纯粹的PyTorch微调库,可以很容易地对LLM进行微调,没有各种依赖项,支持Llama3,目前已经与HuggingFace和其他一些库进行了集成。

Github上还有一些Llama3和Llama的相关资料,有很多入门笔记,LangChain、RAG、提示工程等。

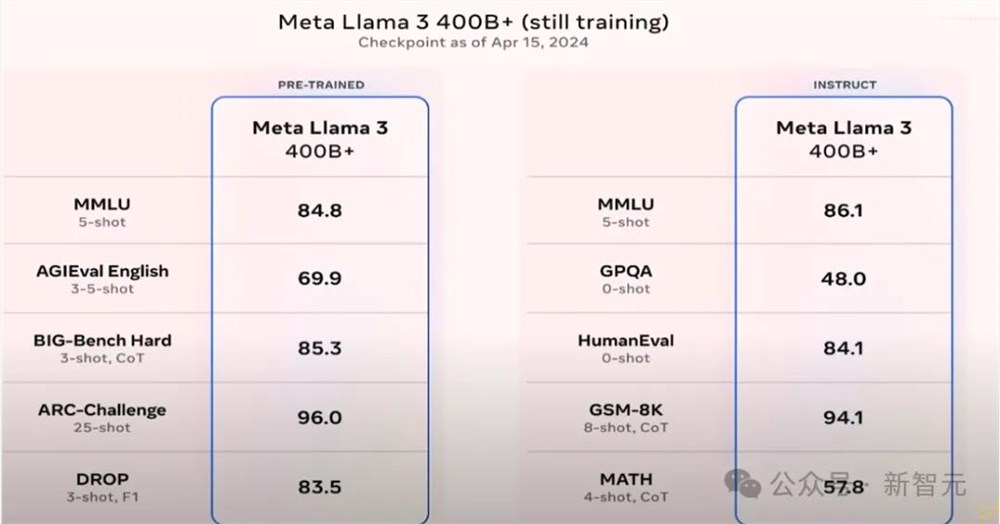
Meta团队也正在训练一个更大的模型Llama3400B+,目前只是抓取了4月15日的checkpoint进行了微调后对比:MMLU达到了86.1,GSM-8K达到了94.1
Llama3之后
团队想要推出更大更好的模型,支持多种语言:Facebook(FOA)的家庭应用程序已经覆盖了近40亿的用户,多语言对于Llama目标实现的AI场景,以及多模态功能都至关重要,包括在Ray-Ban智能眼镜上实现AI,需要理解周围的一切,不可能仅仅通过文字来实现,所以多模态功能在未来肯定也会推出。

最后,Meta也承诺将持续关注安全问题,将继续开源所有的安全措施,并围绕这些措施建立社区,确保安全性的标准化,并表示一定会坚持下去!
参考资料:
https://www.youtube.com/watch?v=r3DC_gjFCSA&themeRefresh=1
(举报)








发表评论取消回复