声明:本文来自于微信公众号数字生命卡兹克,作者:数字生命卡兹克,授权靠谱客转载发布。
夜里十一点,大洋彼岸早上8点整。
Claude带着大货闪亮登场了。
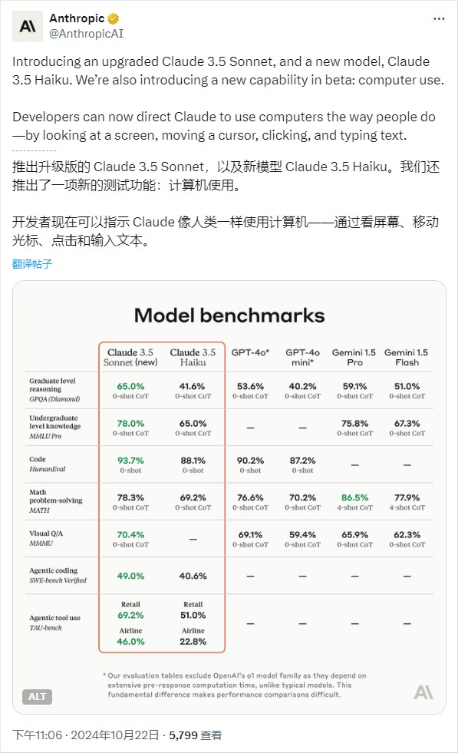
升级版的Claude3.5Sonnet,新模型Claude3.5Haiku,还有全新的新功能:computer use,翻译过来后,我把他称为,“计算机操控”。
一个一个来说。
首先新模型升级版Claude3.5Sonnet。
Claude的模型一直分为三个尺寸,分别是Opus、Sonnet、Haiku。从大到小。
3月的时候,Claude正式推出Claude3代的全系模型,从Opus到Haiku都有。
然后6月的时候推出了Claude3.5Sonnet,只推了这一个,没有3.5Opus和Haiku,参见这篇文章:我体验完刚发布的Claude3.5,发现最强的是这个新功能。
那时候Claude3.5Sonnet的能力就吊打了旧的最大参数的模型。
而今天,推送的是升级版的Claude3.5Sonnet,还有新的Claude3.5Haiku。

有趣的是,Claude3.5Haiku还是后训的,知识截止时间是7月,而升级版Claude3.5Sonnet知识时间并没有变,也就是加了更多的强化学习的合成数据以及“计算机控制”的训练。
而Claude3.5Sonnet的整体性能上,基本傲视群雄。
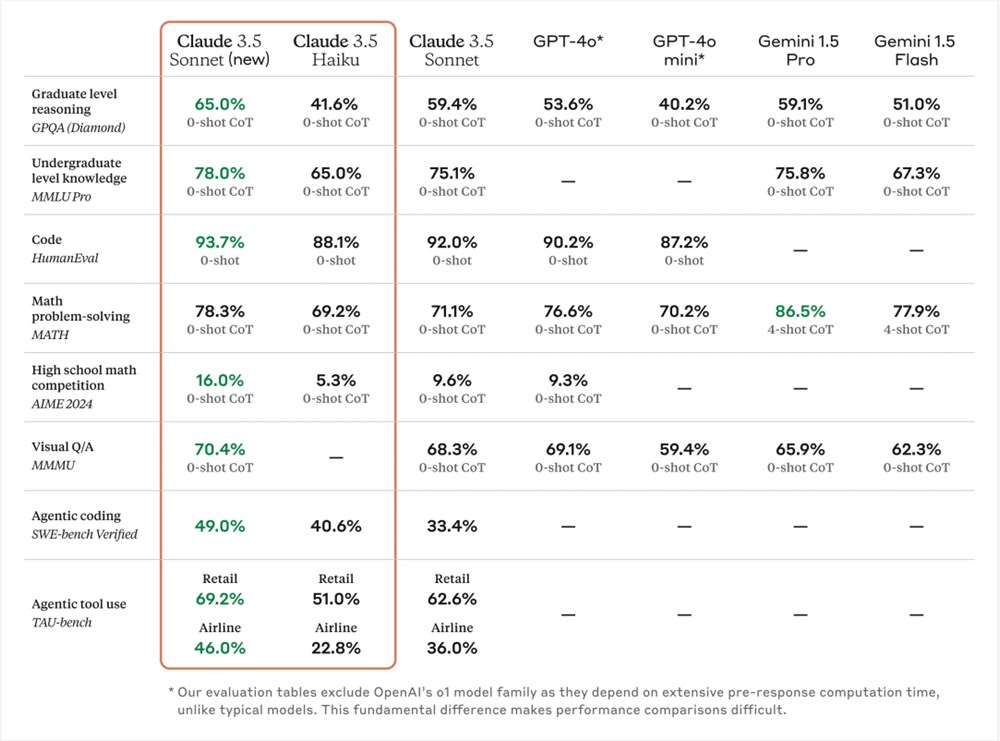
不管是推理、还是本科的知识、还是编程能力啥的,都是No.1,而且Claude的跑分不像很多模型那种刷榜,他的跑分是真的可信的。
我相信6月Claude3.5Sonnet上线后,直接一波科技跃迁,带着cursor之类的A编程一波升天,就不会有任何人会怀疑Claude的代码能力了吧。
最特别的评测基准其实是那个第七行的SWE-bench Verified,大概就是测试写代码解决问题的真实能力,这个评测基准是8月份OpenAI提的,然后这波Claude3.5直接把这个基准加在自己的跑分里。
GPT4o在这项的跑分是33.2%,o1不知道。
但是按Claude的话说,o1是个什么脏东西,不认识。
而新版的Claude3.5Sonnet,目前也在Claude官网上上线了。
可以看到有了new的标签。
我直接发了最简单的一句话:给我生成一个非常精美的俄罗斯方块游戏。
然后,升级版Claude3.5Sonnet,就开始嘟嘟嘟的生成。

直接一次性生成了280行代码,而且这个游戏,是真的可以直接玩的。。
也可以直接让它生成一个随时可调可互动的动效模拟器,彻底改变学习方式。
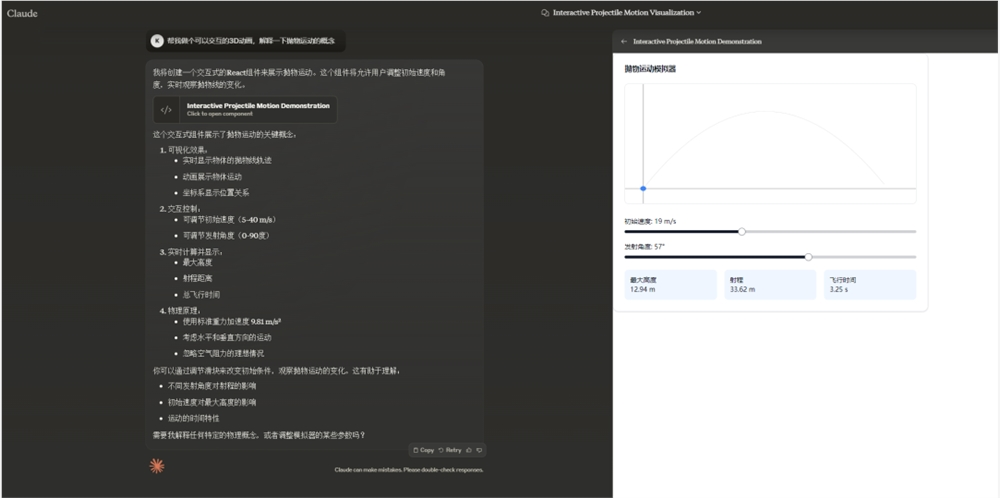
就,非常的酷。
其次是Claude3.5Haiku。
这个其实就没太多可说的了,常规升级,但是是目前最快、性价比最高的模型。
在跟Claude3Haiku的相同成本和速度下,直接击败了参数量最大的Claude3Opus。
在编码任务上,居然能直接打败没升级前的Claude3.5Sonnet,这个是最离谱的。

只能说,Anthropic的强化学习范式走的还是太超前了,合成数据的质量实在是太高太高了。
那最后,也是最重磅的一点,Claude的“computer use”,也就是新功能,计算机控制。
这个点就非常的科幻,能够实时分析用户计算机屏幕上的活动,并自主执行在线任务,比如浏览、点击和输入。
我直接放一个官方case吧。
Anthropic是这么描述这个“计算机控制”的功能的:“Claude3.5Sonnet可以按照用户的命令在计算机屏幕上移动光标,点击相关位置,并通过虚拟键盘输入信息,模拟人们与自己计算机的互动方式。”
这,就是一个能理解用户意图,并帮他自主实现的真正的Agent。
以前的Agent,说实话,看上去更像一个RPA,就是根据预设好的工作流,一步一步的执行下去,但是真正的Agent应该是什么样?
在我看来,他就应该跟人一样,能理解你的复杂语义,把这个复杂语义具象成可执行的步骤,就像我说现在“凌晨3点半了我太困了,但是文章还没有写完,你帮我看看附近有没有咖啡买,有的话帮我买一杯,没有的话就算了。”
如果是个人,那肯定是会打开美团外卖或者饿了么,看看附近有没有咖啡店开着,如果有开着的,看看我最喜欢喝的冰美式有没有的,没有冰美式的话问我一句要换什么口味?然后下单,等待送达。
如果3点半附近都关门了,那也应该告诉我,附近没卖的了,哥们你自己撑一撑吧,一会就能睡了。
这才是AI,这才是我们身边,能进入到普通人生活中的,最酷的AI助手。
而这种AI助手,它势必,需要学会操作手机或者电脑。
我们不止要让AI学会写文章,学会画图,也要让他学会操作。
这样,才能有很强的,自主探索、解决问题的泛化能力。

而升级版Claude3.5,只是在一些简单软件上进行了训练,就有了操作一些不复杂软件的能力,甚至还会自我纠错,不断重试,这又何尝不是一种强化学习、自我博弈呢?
Anthropic,真的吧Self-Play玩出花了。
目前,在测试开发者让模型使用计算机的一个基准评估(OSWorld)中,Claude 目前得分为14.9%。
而人类水平通常为70-75%,虽然差距很大,还有一些路要走,但已经远高于目前其他最好AI模型的7.7%这个分数了。
不过现在这个功能普通用户还用不到,只对开发者进行开放,有API接入,Anthropic的本意是还在前期测试阶段,怕有危险,所以让开发先帮忙测试一下。
我们也花了N久时间,把API接入进来,做了一些简单的测试。
先装了一个类似于模拟系统的东西,一切行为都会在这个模拟系统里运行,Anthropic还是怕对你的系统会有一个不可逆转的损害影响。
我测了很多个case,但是说实话,一是速度实在太磨叽了...二是成功率,确实还有点低下。
比如这个案例:“打开淘宝网站页面,找到小米手机官方旗舰店,找一个2000左右的手机,加到购物车。”
其实不算难,说实话。
但是Claude翻车了,翻车的点也很搞笑,是在输入店名上,人明明叫小米官方旗舰店,它非要写“方店”,后面又试了一次,这次连两个字都不写了,直接写了一个字“舰”,这能搜到才有鬼了...
而且,这个视频我已经两倍速了,你们可以感受一下它有多慢。。
不过,让他玩2048,它玩的倒是非常的开心。这一次,是三倍速。
玩的还挺好,我感觉在这放着,他一个人能玩到天荒地老。
这倒也是挺有趣的。
当然,也能做一些很实际的事情,比如给我的浏览器装一个可以屏蔽广告的插件。
他居然把插件地址背下来了,直接输入,给我搜索+安装一步到位。
起飞。
虽然总体任务的成功率还比较一般,但是还好,毕竟Claude自己也说了,成功率没那么高。
而且,这只是第一代。
他们坚信,使模型适应工具,这是必然,而模型也可以融入我们每天使用的环境里,成为我们生活的方方面面。
他们的目标是让Claude使用现有的计算机软件,就像人一样。
就像人一样。
真好。
希望这个愿景,能在不远的未来达成。
我真的,很想拥有一个自己的。
贾维斯。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:卡兹克、东毅
(举报)








发表评论取消回复