声明:本文来自于微信公众号 AI新榜,作者:石濑,授权靠谱客转载发布。
高端的大片特效,如今只需要最朴素的操作。
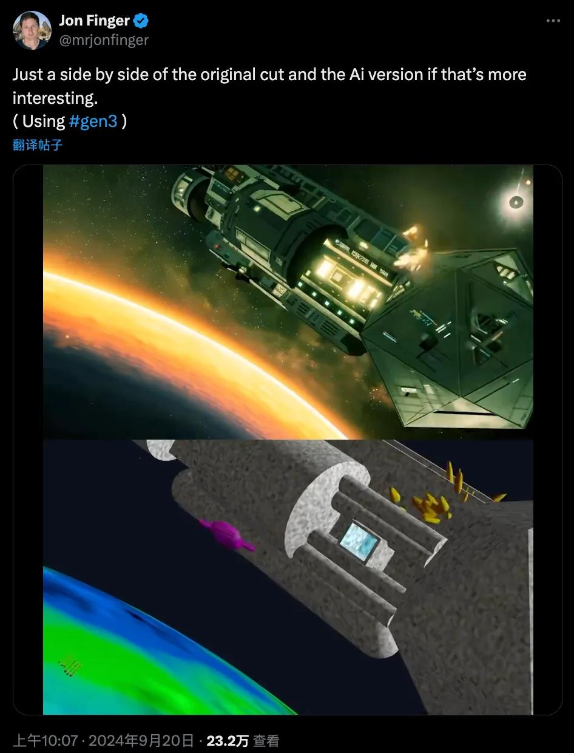
简陋实拍“AI一下”秒变惊险动作片:

上方为AI生成
下方为原视频素材
还可以一人分饰两角,变装易容从未如此简单:

上方为AI生成
下方为原视频素材
以上动图来自X博主“Jon Finger”利用Runway Gen-3模型最新V2V(视频生视频)功能整活的AI特效视频。
9月底,该视频发布后,迅速在AI创作圈引起热议。视频中人物一致性、动作表现相当惊艳,不少在X平台上有一定影响力的创作者,也在评论区纷纷盛赞“Incredible”。
背后工作流并不复杂。博主先是“就地取材”,实拍了一些表演镜头,结合部分未经渲染的3D建模镜头,投喂给AI后,经过大量抽卡,便得到了最终的视频效果。
AI视频创作中,目前最常见的工作流是图生视频和文生视频。相较之下,大多数头部AI视频工具如Luma、可灵、即梦等,都还没有支持V2V功能。
但对于寻求进阶玩法的玩家来说,V2V在保持画面连续性、人物运动符合物理运动规则方面有着天然的优势。

图源:X博主“aulerius”
更不用说,今年在应用层上卷生卷死的AI视频生成产品,还把V2V的操作门槛打了下来、生成质量提了上去。
据我们观察,以抖音、TikTok为代表的短视频平台上,已经涌进大量V2V制作的热门UGC内容,其中还有不少博主借此快速涨粉起号。
目前市面上有哪些好用的V2V工具?创作者都在用V2V做些什么?相较图生视频和文生视频,V2V的应用前景如何?我们进行了一番探究。
把一支视频交给AI,可以有哪些玩法?
为了方便理解,先看看整体制作流程。简单来说,利用V2V功能制作一支AI特效视频主要分为两个步骤:
第一步,准备好原始素材。无论是实拍还是3D建模,只要画面构图、人物动作符合创作需求即可。实拍可以是任何场景,而3D建模则可以是任何想象中的物体或环境。这些素材不需要完美,因为AI可以进行进一步加工。
第二步,投喂素材给AI,进行风格化处理。如果说第一步相当于绘画中的线稿,那这一步就是上色和细节修饰的过程。不过,由于各家AI视频工具的定位和面向的用户群体有所差异,在这一步中,你用不同的工具,能创作出来的视频是不一样的。
所以,依据功能和玩法差异,我们把支持V2V的AI视频生成工具分成了以下三类:
1.视频转绘工具:可以通过文字提示词指挥AI做后期特效,包括改变视频氛围、色调和风格,甚至更改人物形象。代表工具有Runway、Domo和Kaiber。
https://runwayml.com/
https://www.domoai.app/zh-Hant/create/video
https://kaiber.ai/
2.模版化的视频转绘工具:这类工具定位更接近“视频风格转绘”,通常由官方提供预设模版,适合需要快速制作特定视频风格的玩家。代表工具有GoEnhance AI、Wink AI。
https://app.goenhance.ai/vid2vid
https://wink.meitu.com/
3.局部视频编辑工具:支持输入文字提示词进行局部编辑,适合需要精细调整视频的玩家。代表工具有Pika1.0、以及尚未面向公众开放的Sora和Meta最近发布的AI视频模型Movie Gen。

Pika1.0演示Demo
这三类工具都基于V2V的使用方法,即你输入一个视频,可以通过文字提示词或预设模版,来改变视频的风格或添加创意特效。
不同之处在于,模版化的视频转绘工具如GoEnhance AI,不支持文字提示词输入,所以你没有办法“用嘴”指挥AI修改画面主体的细节。
例如,让人物戴个帽子、或者更改人物样貌,如果官方没有提供特定的模版,都难以通过这类工具实现。
早前在TikTok、抖音上流行的真人转绘漫画风格玩法,就是基于模版化的视频转绘工具。在一定程度上,模版优化了产品使用体验,方便UGC内容制作,但同时也限制了创意的发挥。
而局部视频编辑,虽然在交互上更自然、更可控——可以通过框选局部画面进行精细修改,也支持文字提示词输入。但目前市面上提供该功能的产品很少。
据我们不完全统计,面向公众开放的产品中,仅有Pika(目前已更新至Pika1.5)的上一代模型Pika1.0支持局部视频编辑,且需要订阅会员才能使用。
相比之下,以Runway为代表的视频转绘工具可玩性就很高了。
以Runway为例,其V2V功能是由最新模型Gen-3支持的,不仅在生成视频质量上有显著提升,还能一次性上传并转换时长达10秒的视频。
对于第一次使用的新手,官方还提供了提示词示例参考如3D卡通、黏土风等流行风格,点击你想要的风格,修改彩色字体部分(画面主体描述)即可。
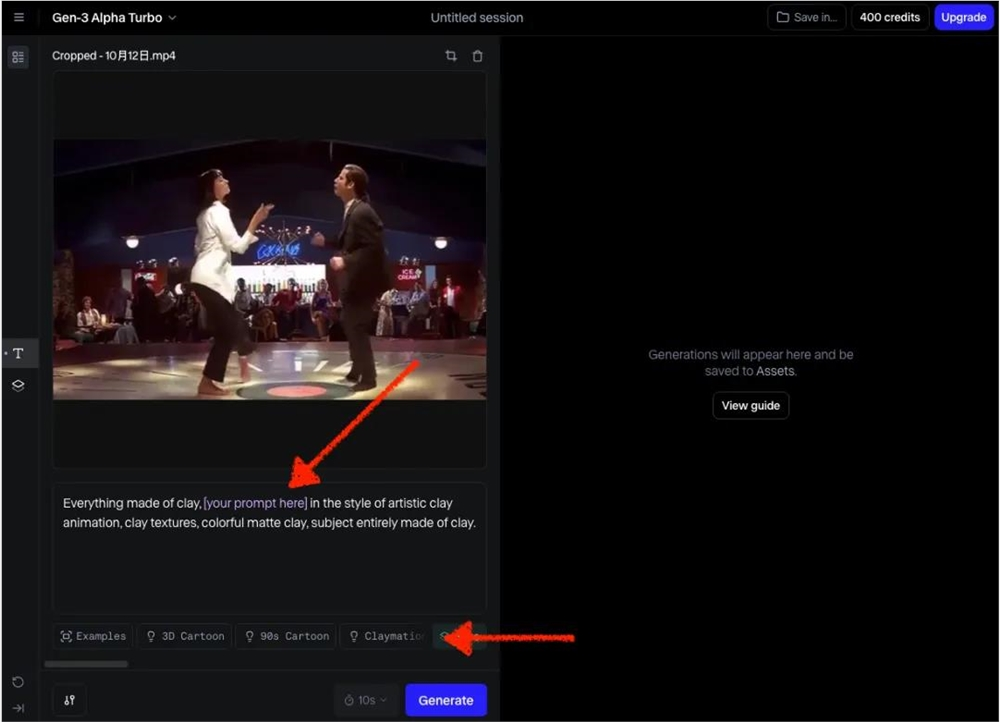
在这里,我们尝试了多种提示词。例如,让跳舞的两个人带上墨镜、或者让他们的手变成热狗肠,都成功生成了。

由于生成质量的提升,近期各大社交媒体上也涌现出了不少基于Runway V2V的有趣玩法,其中一些玩法还获得了不错的流量。
一个在网上传播颇广的例子是,国民电子榨菜《甄嬛传》的二创。“赛博影业”是抖音上的一位博主,自9月20日起其在抖音上陆续更新了一系列《甄嬛传》的二创视频,定位是“印度甄嬛”。
这些视频大多围绕剧中的名场面或经典情节整活,其中有一条视频获得36.8万转发。
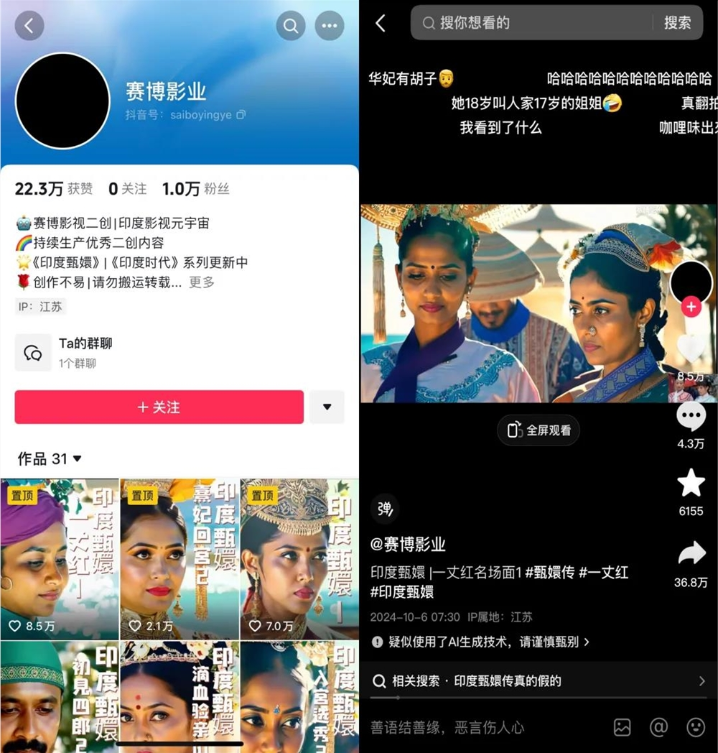
从效果呈现来看,这些二创视频并没有对原片进行较大改动,仅仅是利用V2V将画面风格和人物装扮转换成了具有印度特色的元素。
背后制作流程类似X博主“@CharaspowerAI”在9月24日发布的对比视频所示,一段视频素材+一句提示词,就轻松完成了人物和场景的“套皮”。
提示词:A group of woman in a luxurious hotel in dubai, sunset, luxurious dress code, cinematic
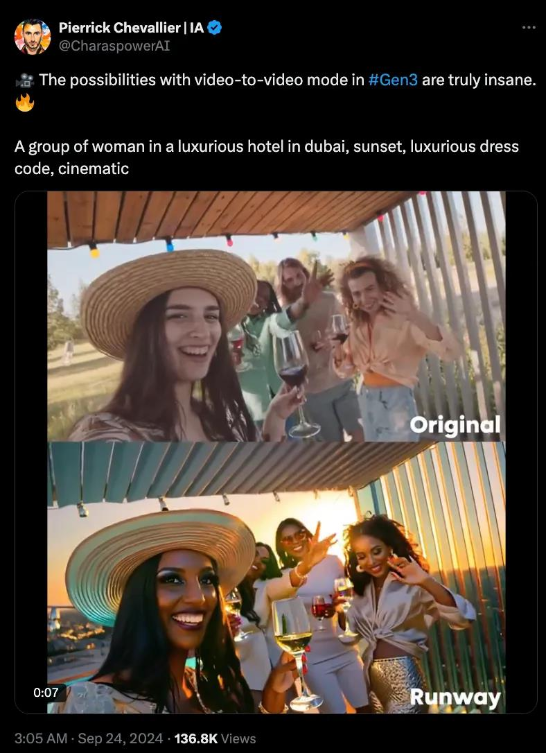
AI圈知名博主“歸藏”还发文称这是“天才想法”,并推测其背后的工作流可能是“剪辑一些影视剧的经典镜头,然后用Runway V2V转成别的主题”,并评价称这“非常容易起量,又避免了原创问题”。
不过还是可以看到,虽然V2V在画面整体风格上可以保持一致性(用网友的话来说就是“一股咖喱味”),但仍然无法保证在多切几个镜头之后,“甄嬛”还是那个“甄嬛”。
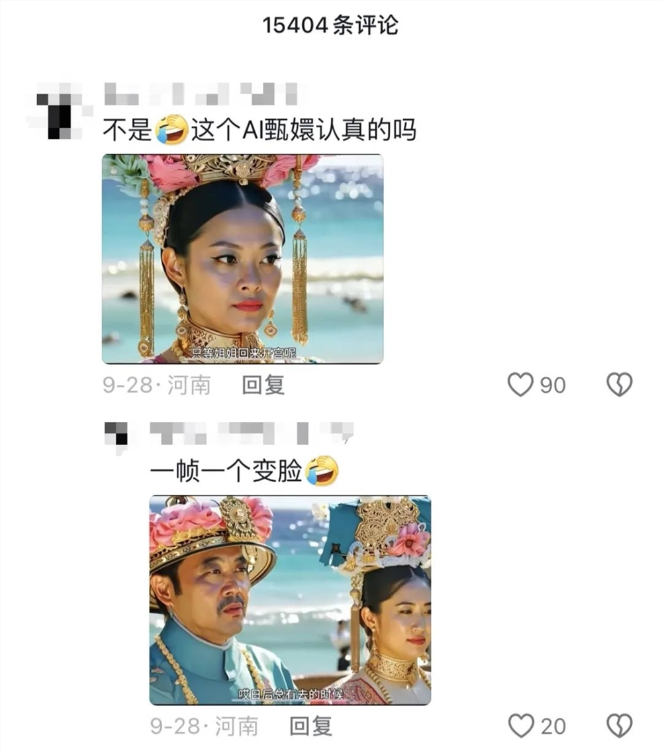
可见,在强叙事、多人物的视频中保持人物一致性,V2V也不是最终的解决之道。
从电影制作到短视频生产,
V2V的应用前景如何?
在AI视频生成领域,V2V并不是一个新玩法。
头部AI视频初创公司Runway最早尝试的视频生成模式就是V2V。早在2023年2月,Runway就推出了可以转换视频风格的Gen-1模型,虽然这款初代模型在当时为影视制作带来了一些新思路,但与Gen-3相比,其生成效果多少还是有点拉胯。
从这两代的生成效果对比,可以看到AI视频生成技术的迭代之快。

Gen-1

Gen-3
所以, V2V其实不是一个新功能,但之前由于生成质量、操作门槛等各种因素,它在实际应用中的普及度,相比图生视频和文生视频等工作流要小众得多。
V2V主要使用人群在早前更偏向专业创作者,作为一种实验性的方法,用来替代传统影视制作中的动作捕捉、CG和布景等制作成本高昂、耗时较长的制作环节。

迪士尼导演Nem Perez工作流:实拍绿幕+Kaiber
一些专业的AI创作者会利用ComfyUI+AnimateDiff+LCM的工作流进行视频风格转绘。
Simon阿文,赞126
随着底层模型能力的提升,AI视频在产品应用层上的内卷,如今做一支AI转绘视频,无需复杂的前期部署,就能让原本的视频“改头换面”。
这对大多数创作者来说是一个好消息,就算你没有专业影视制作背景和资源,也能用AI做出以前做不到的视觉效果。
就视频生成模式而言,用视频作为“原料”来生成新视频,比光用文字或图片靠谱得多——给模型一个基本的视频内容框架,再让AI赋予原视频新的外表和风格,远远比文字或图片作为输入“原料”更为可控。
在AI备受诟病的原创性问题上,V2V的工作流程也因为提供了足够的创作自由度,在作品归属上更易被判定为是创作者本人的智力投入。
尤其对专注特效、剧情赛道的博主和自媒体创作者来说,结合实拍等方式的V2V,既可以在制作上节省成本,也能比以往更轻松地将脑子的创意转化为现实,用小成本撬动大流量的同时,还规避掉了使用AI创作的原创性问题。
自今年年初Sora横空出世以来,国内外大厂、AI初创公司在视频生成产品上的内卷有目共睹。毕竟视频作为当今互联网内容消费的流量大头,谁都不愿错过在AI时代成为抖音的机会。
在“人人都能成为导演”的科技愿景兑现之前,不可否认的是,AI正在以前所未有的速度降低内容生产的门槛。
如今在V2V的帮助下,人人都可以是“五毛特效师”。
(举报)








发表评论取消回复