声明:本文来自于微信公众号 量子位,作者:量子位,授权热心网友转载发布。
让AI绘画模型变“乖”,现在仅需3秒调整模型参数。
效果be like:生成的风险图片比以往最佳方法减少30%!
像这样,在充分移除梵高绘画风格的同时,对非目标艺术风格几乎没有影响。

在移除裸露内容上,效果达到“只穿衣服,不改结构”。

这就是复旦大学提出的概念移除新方法——RECE。
目前,基于扩散模型的AI生图有时真假难辨,常被恶意用户用来生成侵犯版权和包含风险内容(如虚假新闻、暴力色情内容)的图像。
SD中使用的的安全措施是使用安全检查器,对违规的生成图像不予展示,还集成了一些用classifier-free guidance来规避风险概念的方法。
但在开源条件下,恶意用户可以轻松绕过这些机制,网上甚至有大把的教程……
针对此,学界提出了“概念移除”,即通过微调来移除文生图扩散模型中特定的风险概念,使其不再具备生成相应内容的能力。
这种方法的资源消耗远低于从头重新训练的SD v2.1版本,也不能被轻易绕过。
而最新研究RECE,拿下概念移除SOTA效果,并且对无关概念破坏极小,论文已被顶会ECCV2024接收。

整个过程基于高效的解析解
此前,尽管概念移除进展迅速,其问题仍然明显:
已有的方法为了安全性牺牲了较多的生成质量。
已有方法即使对模型破坏较大,仍不能充分移除不当概念,有很大几率生成风险图像。
大多数方法需要大量的微调步数,计算资源消耗大。
那么RECE是如何实现的?
RECE主要包含两个模块:模型编辑和嵌入推导。
首先,RECE以解析解的形式,在交叉注意力层中将风险概念映射到无害概念。
然后,RECE以解析解的形式推导出风险概念的新嵌入表示并用于下一轮的模型编辑。
RECE还包括了一个简洁有效的正则项,可以证明其具有保护模型能力的作用,进而保证概念移除可以交替进行多轮。整个概念移除的过程都基于高效的解析解。
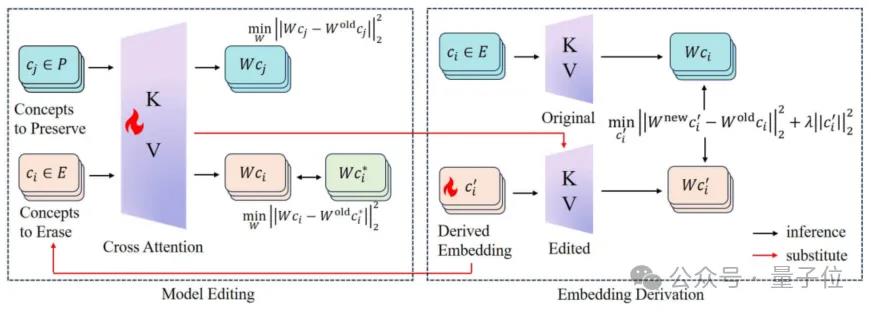
风险概念嵌入推导
RECE的有效性来自于对已有方法概念移除不彻底的观察:
以”裸露“为提示词,SD生成了裸露图像,UCE(一种概念移除方法)成功避免了裸露内容的生成;
然而,输入有意设计的提示词或文本嵌入,UCE再次生成了裸露内容。

为引导编辑后的模型重新生成裸露内容,接下来将以“裸露”为例,介绍RECE是如何推导上述具有攻击性的概念嵌入的。
既然是文生图,那首先思考文本引导的机制——交叉注意力。
SD利用CLIP作为文本编码器得到提示词的嵌入形式,并且获得key与value,与表征视觉特征的query一起,得到输出:
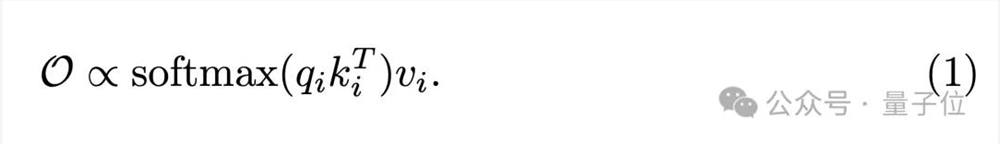
如果能得到一个新的概念嵌入,满足在编辑后的交叉注意力映射后,足够接近经过编辑前的映射值,那么应能够诱导生成裸露图片:
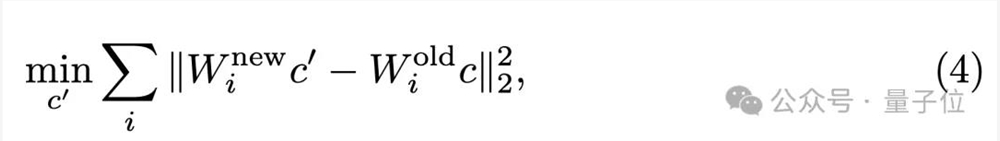
上式为凸函数,因此具有解析解,不需要繁琐的梯度下降近似求解:
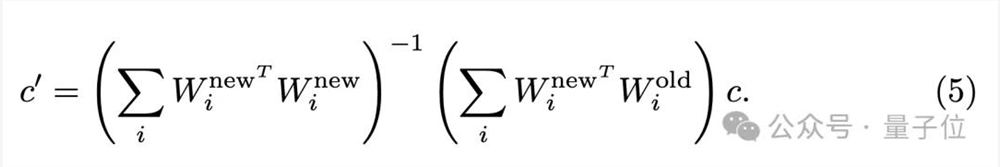
模型编辑
接下来RECE将编辑交叉注意力以移除风险概念。RECE借鉴了已有的方法UCE,通过解析解来编辑交叉注意力的权重,一步到位,避免繁琐微调。
给定“源”概念(例如,“裸露”),“目标”概念(例如,空文本“ ”),以及交叉注意力的K/V投影矩阵,UCE的目标是找到新权重,将新权重下的映射值对齐到。
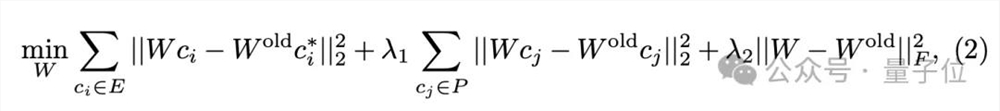
其中后面两项是为了控制参数变化,最小化对无关概念的影响。这也是凸函数,将解析解直接赋值给新权重:
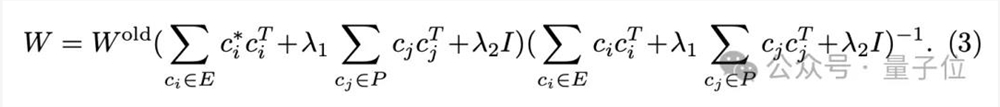
正则项
理想情况下,将公式(5)得到的移除就可以避免生成裸露内容了,然而团队发现这会对模型能力产生极大的破坏。
因此在相邻的两轮概念移除中,RECE对无关概念的映射值变化做了约束:
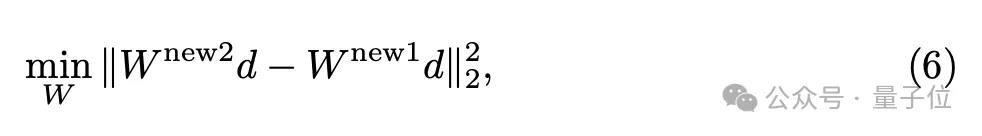
学过线性代数的同学是不是觉得很熟悉呢?
利用矩阵范数的相容性,证明得到:
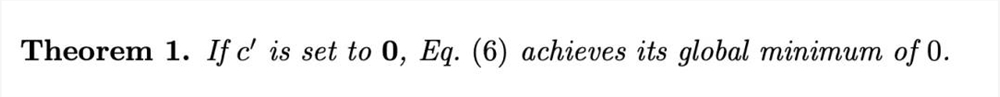
因此只需在推导时添加一个范数约束项,就能保护模型的能力:
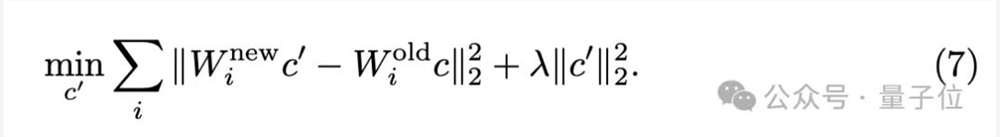
其解析解为:
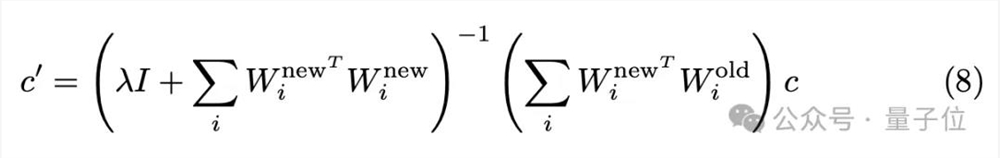
综上,RECE的算法流程归纳为:

RECE效果如何?
不安全概念移除
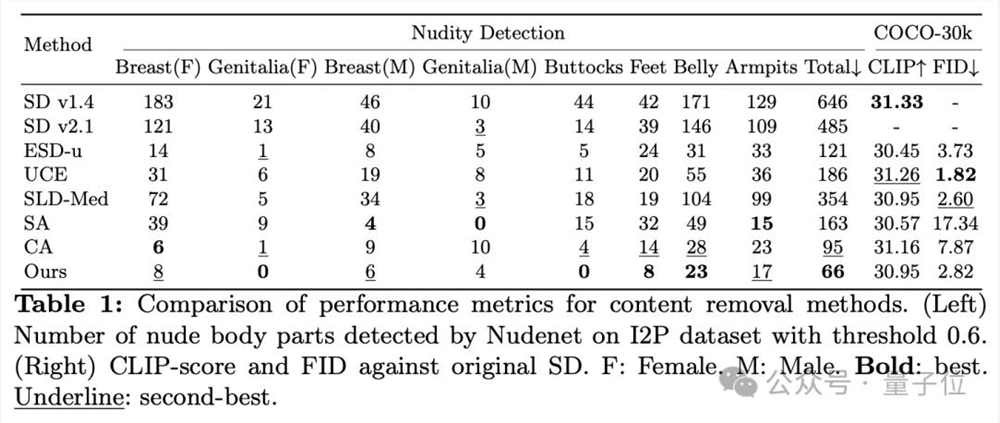
首先来看最敏感的内容——色情。在I2P基准数据集上,RECE的裸露移除效果超过了全部已有方法。
团队还评估了概念移除后模型的正常内容生成能力,即无关概念集COCO-30k上的FID指标,也远超CA等方法。
艺术风格移除
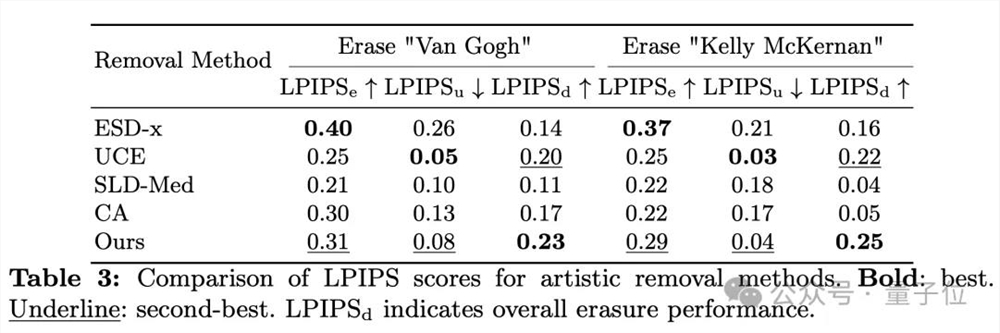
保护艺术版权不受AI侵犯同样十分敏感。综合效果方面,RECE优于所有方法。
并且细致来看,RECE是唯一一个在目标艺术家擦除效果和无关艺术家保留效果方面都表现优异的方法。
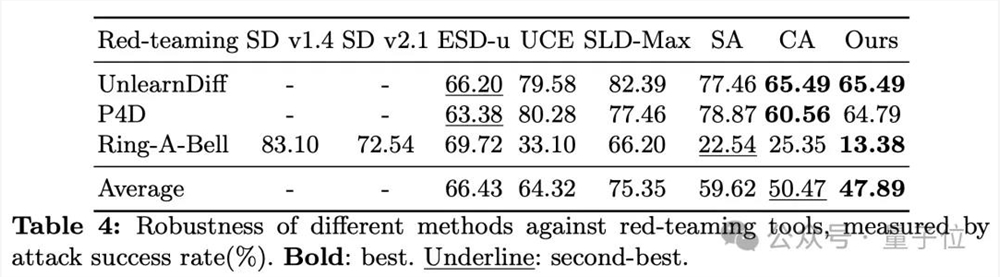
红队鲁棒性
RECE对恶意用户的有意攻击同样可以有效防护,在红队攻击下,RECE生成风险图片的几率仍是最低。
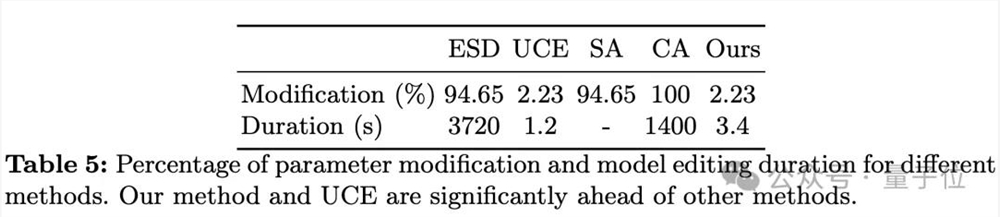
模型编辑耗时
RECE5个Epoch仅需3.4秒,参数改动比例、编辑耗时远低于CA等方法。UCE的耗时也很短,但UCE的概念移除效果与RECE相差较大。
作者简介
论文共同第一作者为复旦大学视觉与学习实验室的硕士新生公超和博士生陈凯。
通讯作者为陈静静副教授。
研究团队专注于AI安全的研究,近年来在CVPR,ECCV,AAAI,ACM MM等顶会上发表过多篇AI安全的研究成果。
论文地址:https://arxiv.org/abs/2407.12383
代码地址:https://github.com/CharlesGong12/RECE
(举报)








发表评论取消回复