声明:本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:关注大模型的,,授权热心网友转载发布。
o1消息满天飞。
自从 OpenAI 发布了新模型 o1后,它就承包了 AI 领域近几天的热搜:
有人用门萨智商测试题「拷问」它,竟测得 o1智商高达120;
数学大佬陶哲轩要求 o1回答一个措辞含糊的数学问题,最终得出一个结论:o1是个平庸但不无能的研究生;
还有一位天体物理学论文作者,仅用6次 Prompt,就让 o1系列模型在1小时内,创建了代码运行版本,这可是他博士生期间10个月的工作量。
但在 ARC Prize 测试中,o1的表现并没有想象中出类拔萃,仅仅是追平几个月前发布的 Claude3.5Sonnet。
看完五花八门的评测,大家反而有些迷茫了,o1的实力到底怎么样?
智商测试得分忽高忽低,网友纷纷质疑
上周,OpenAI 在介绍 o1时表示,它不需要专门训练,就能直接拿下数学奥赛金牌,甚至可以在博士级别的科学问答环节上超越人类专家。
这也让大家对 o1的「智力水平」产生了好奇。就在前天,X 博主 Maxim Lott 专门拿 o1进行了挪威门萨智商测试,结果测得它的智商高达120,远远超过了其他所有的大模型。具体来说,o1在35个智商问题中答对了25个,远远高于大多数人类的表现。
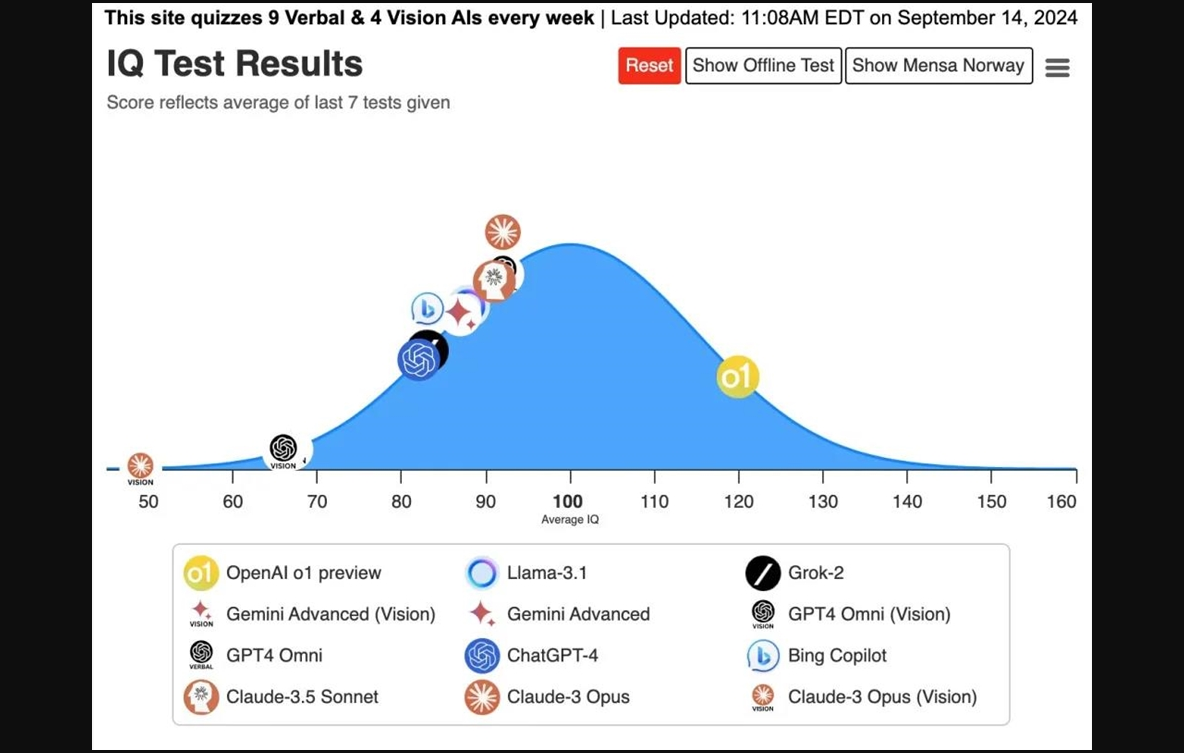
在此之前,Maxim Lott 还进行了一场 o1的智商测试。在这个测试中,o1的 IQ 达到100。
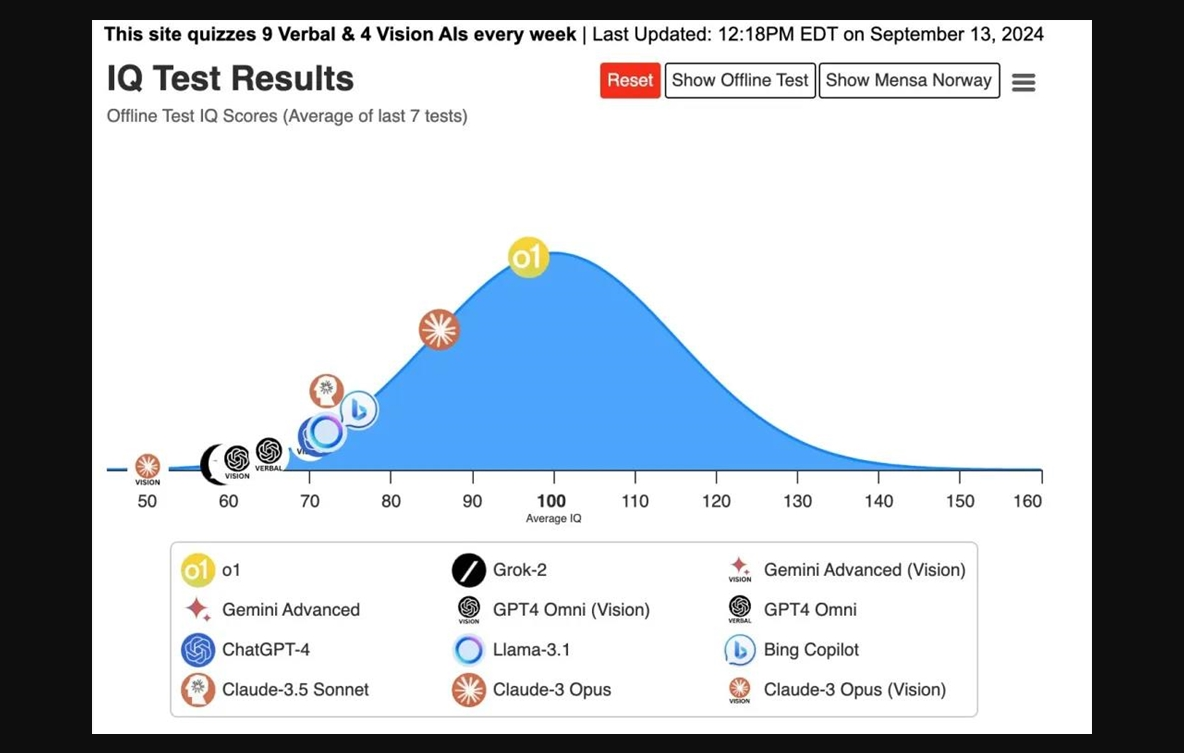
两次结果一对比,有网友质疑,为何先后测试的结果如此不同?
Maxim 表示,o1得分100的这个智商测试,是由门萨会员专门设计的,是一个仅限线下的测试,且不包含在任何人工智能的训练数据中,因此其得分会低于公开智商测试的得分。
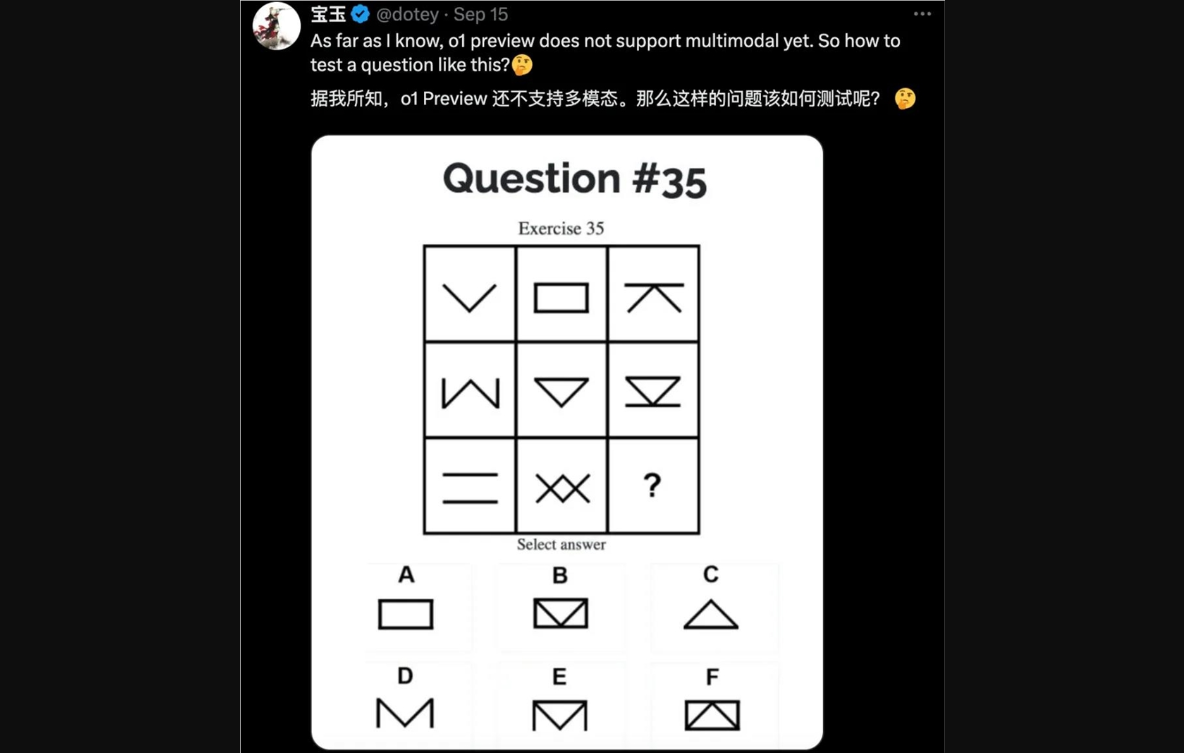
也有网友好奇,o1目前还不支持多模态,那么这类表格图形题目是如何测试的?
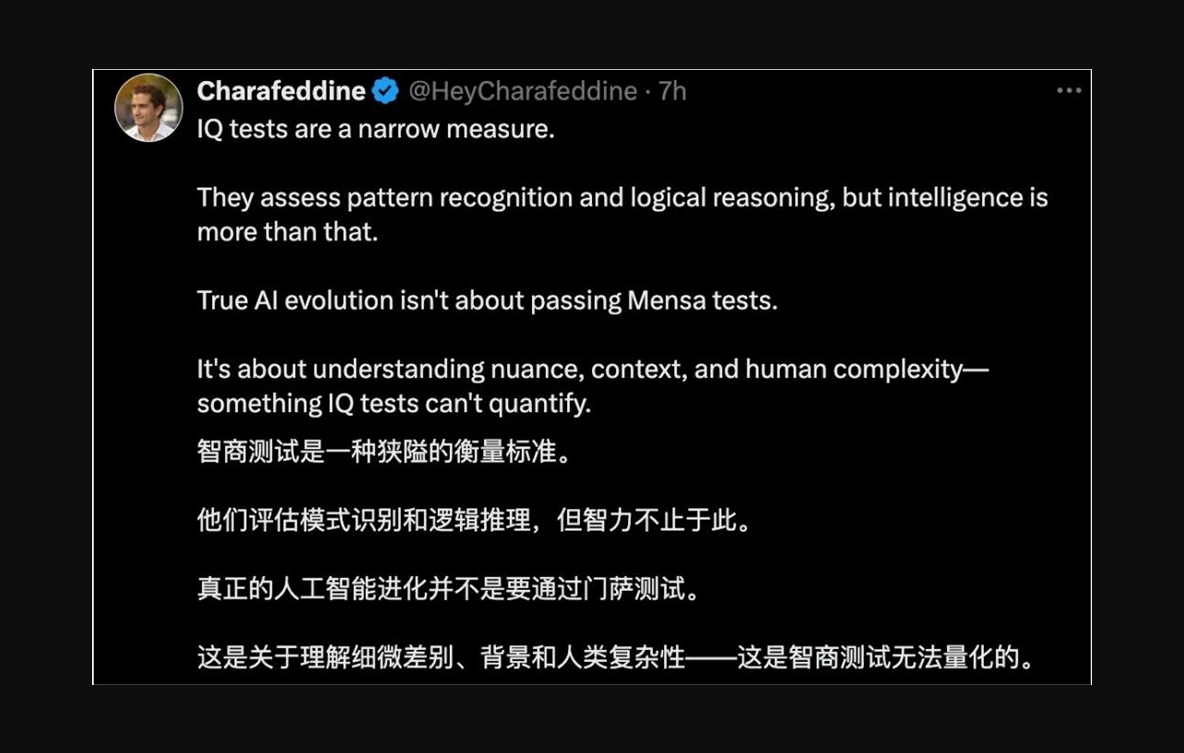
还有网友认为,智商测试是一种狭隘的衡量标准,要想真正评估人工智能进化,不是通过门萨测试,而是考察它们对于细微差别、背景和人类复杂性的理解,而这些是智商测试无法量化的。
此外,有网友认为,门萨智商测试是针对特定年龄组的人类进行标准化的,因此对于这些机器人来说,不可能得到一个「真正的智商」分数或性能评估。
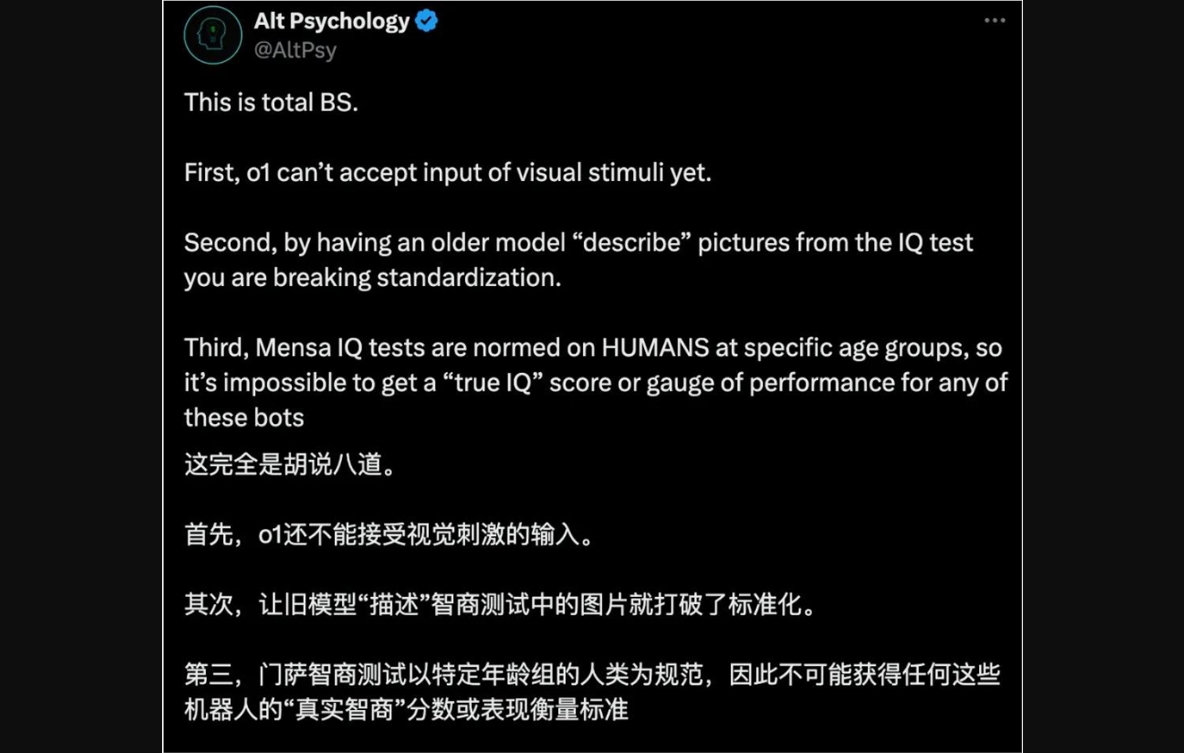
同样迷惑的是,在 ARC Prize 测试中,两个 o1模型都击败了 GPT-4o,其中 o1-preview 仅仅和 Claude3.5Sonnet 得分相同。
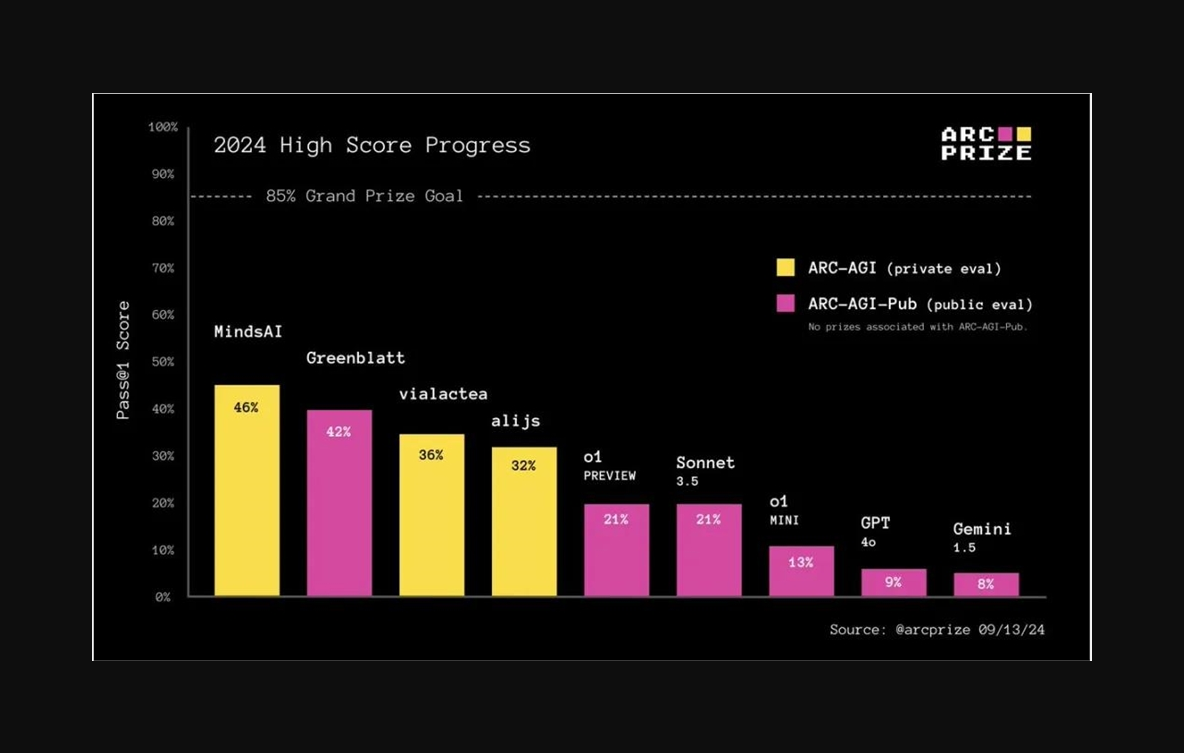
图源:https://arcprize.org/blog/openai-o1-results-arc-prize
这让人质疑:o1-preview 的「推理」可能只是一种营销语言,OpenAI 或许采取了一些方法让不太智能的系统看起来更智能,仅此而已。
在测试中,o1的性能提升还带来了更高的时间成本 —— 它花了70个小时完成400个公共任务,而 GPT-4o 和 Claude3.5Sonnet 只花了30分钟。
「平庸的研究生」o1
1小时完成了博士生10个月的工作
或许大家还记得,陶哲轩前两天给了 o1模型一个评价:「更强了,但是在处理最复杂的数学研究任务还不够好,就像指导一个水平一般但不算太无能的研究生。」
进步的地方体现在:「我要求 GPT 回答一个措辞含糊的数学问题,只要从文献中找出一个合适的定理就能解决这个问题。之前,GPT 能够提到一些相关概念,但细节都是幻觉般的胡言乱语。而这一次,GPT 找到了 Cramer 定理,并给出了完全令人满意的答案。」
比如,2010年,陶哲轩曾经寻找「乘法积分」(multiplicative integral)的正确术语,但在当时的搜索引擎上找不到。于是他在 MathOverflow 上提出了这个问题,并从人类专家那里得到了满意的答案。如今,他向 o1提出了同样的问题,模型返回了一个完美的答案。
诚然,上述 MathOverflow 上的帖子有可能已经包含在模型的训练数据中。但陶哲轩表示,这至少证明了 o1在某些语义搜索查询的高质量答案方面与问答网站不相上下。
不足的地方也很明显,就像陶哲轩的举例:
新模型可以通过自己的努力得到一个正确的(而且写得很好的)解决方案,但它自己并没有产生关键的概念想法,而且确实犯了一些非同小可的错误。这种经历似乎与试图给一个平庸但「并非完全不称职的研究生」提供指导差不多。不过,这比以前的模型有所改进,因为以前的模型的能力更接近于「不称职的研究生」。在达到「称职的研究生」水平之前,可能只需要再进行一到两次能力改进的迭代(以及与其他工具的整合,如计算机代数软件包和证明助手),到那时我就能看到这个工具在研究级任务中的重要作用了。
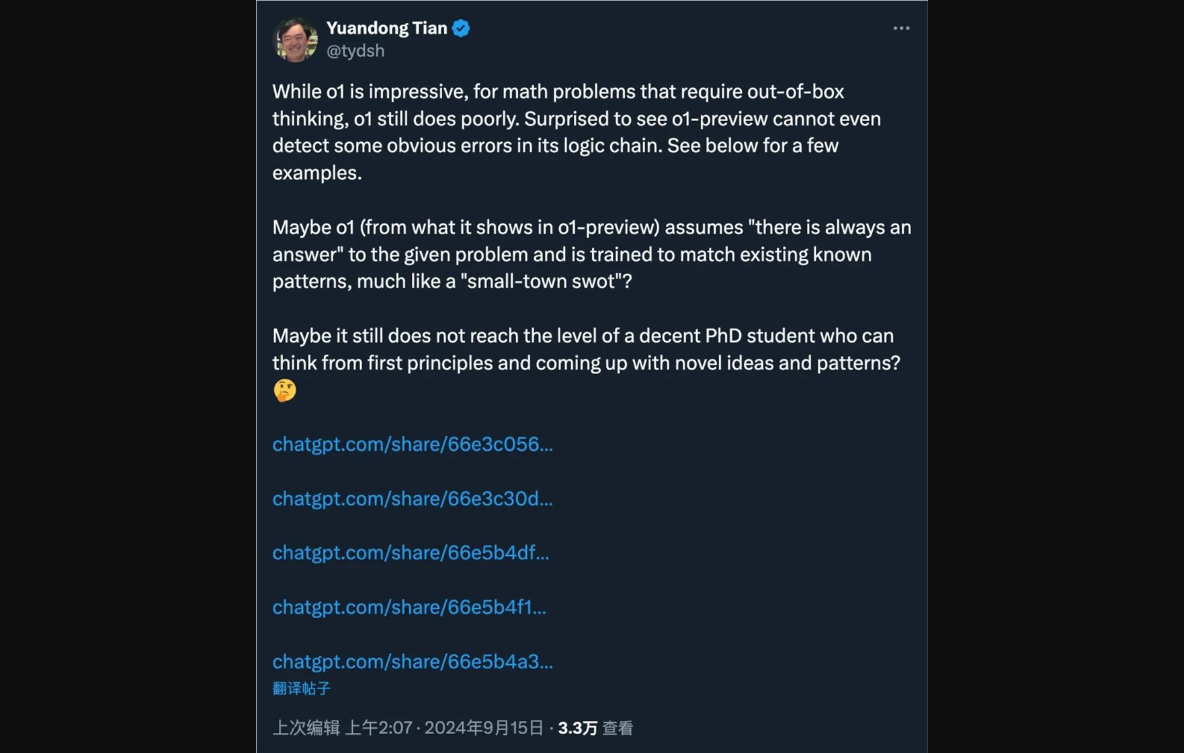
AI 学者田渊栋表示,自己也发现,虽然 o1的表现令人印象深刻,但对于需要跳出思维定式的数学问题,o1的表现仍然很差。
「令人惊讶的是,o1-preview 甚至无法检测出其逻辑链中的一些明显错误。」
有趣的是,对于陶哲轩等知名学者来说「不太令人满意」的 o1,却成为了很多研究者心中的神器。
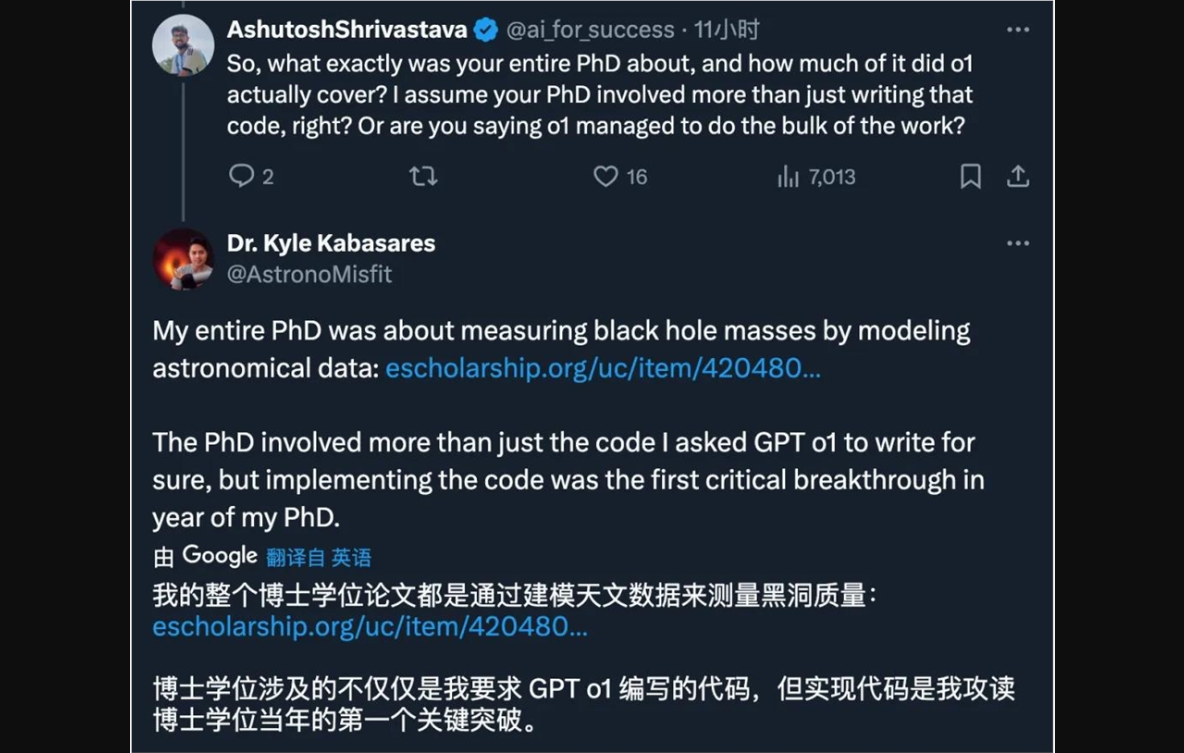
一篇天体物理学论文的作者使用 o1的预览和迷你版本,仅仅经过6次 Prompt,在1小时内创建了自己研究论文方法部分所述代码的运行版本。
视频地址:https://youtu.be/M9YOO7N5jF8?si=5pfmIq023EFmPzdK
尽管代码不是当时唯一的突破成果,但这部分工作确实让他在攻读博士学位的第一年里奋斗了大约10个月。
但需要注意的是,虽然 o1确实模仿了这位研究者的代码,但它使用的是自身创建的合成数据,而不是论文中使用的真实天文数据。此外,o1创建的也只是一个「最简单版本」。
面对网友的一些质疑,他在后续发布的新视频中强调,自己并不是宣传人工智能已经到了能做出突破性新发现的地步,自己的尝试也不意味着 AGI 已经到来,原意只是「它可以成为一个非常棒的研究助手」。
视频地址:https://youtu.be/wgXwD3TD43A?si=Nr6_Z1qjBdicE-_x
使用 Claude 逆向工程 o1架构
得到什么结论?
在技术博客《Learning to Reason with LLMs》中,OpenAI 曾对 o1进行了一部分技术介绍。
其中提到:「OpenAI o1是经过强化学习训练来执行复杂推理任务的新型语言模型。特点就是,o1在回答之前会思考 —— 它可以在响应用户之前产生一个很长的内部思维链。也就是该模型在作出反应之前,需要像人类一样,花更多时间思考问题。通过训练,它们学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。」
或许 OpenAI 不会公布更多底层的技术细节了,但研究者们的好奇不会消失。
一位研究者「TechnoTherapist」决定借助大模型的力量来剖析:他向 Claude 提供了涉及 OpenAI 发布的信息(System Card、博客文章、Noam Brown 和其他人的推文、ARC Prize 团队的评论)和与 o1模型相关的在线讨论(Reddit、YouTube 视频)。
Claude 可以用 mermaid、plantuml、svg 等语言创建图表。研究者从 mermaid 开始,反复修改,直到得到一个全面的图表;然后让 Claude 将其转换为 svg,并添加所需的视觉特征(美学、需要突出显示的区域等);最后,用 python 脚本将 svg 转换为 png 图像。
经过一番讨论,他和 Claude 共同完成了 o1模型的可能架构图:
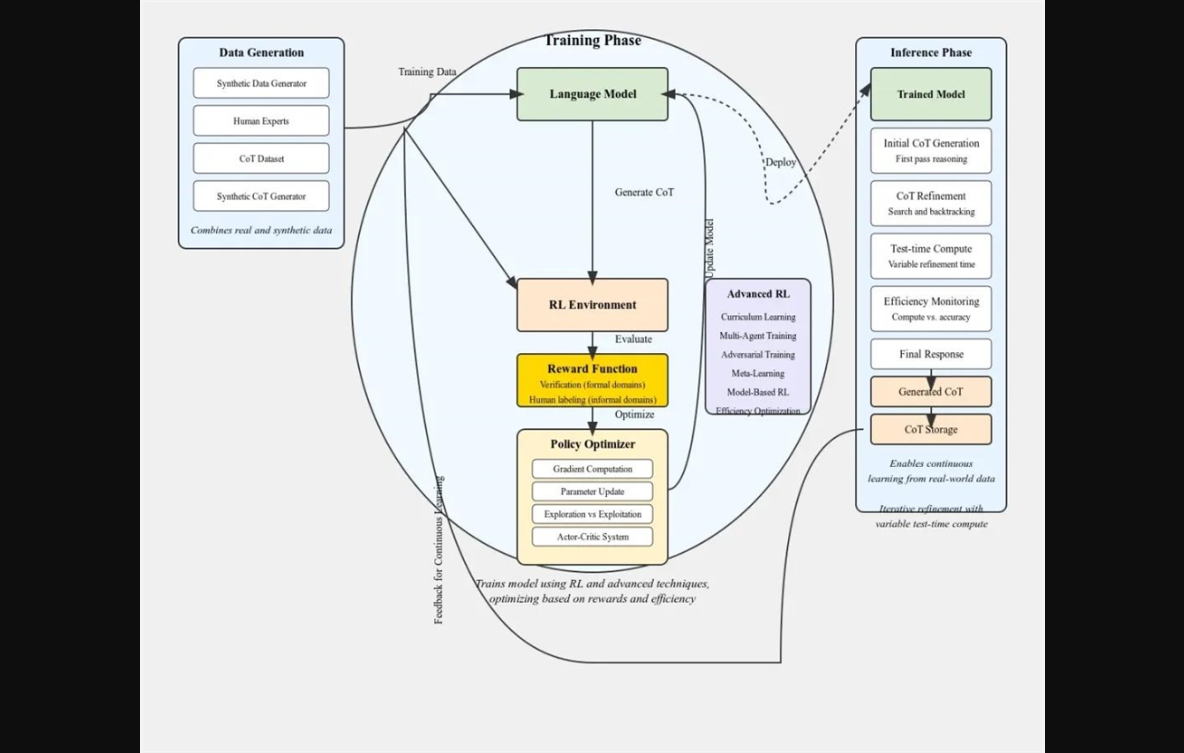
图源:https://www.reddit.com/r/LocalLLaMA/comments/1fgr244/reverse_engineering_o1_architecture_with_a_little/
OpenAI 的博客也曾提到,随着更多的强化学习(训练时计算)和更多的思考时间(测试时计算),o1的性能持续提高,类似于「强化学习的 Scaling Law」。大规模的强化学习算法,能够教会模型如何在数据高度有效的训练过程中利用其思维链进行高效思考。
在这次逆向工程中,研究者假设了 OpenAI 可能会使用现实世界中生成的 CoT 来进一步调整 RL 优化模型。因此在架构图中,语言模型会将大规模 CoT 存储输入到 RL 环境中。
也有人持不同看法,比如这位研究者指出,上述「假设」的过程很可能只是一个「模拟思路的 Prompt 响应生成循环」,而所谓的「推理 token」也只是一种隐藏 token 的花哨术语。
o1能力强,但使用需谨慎
o1确实有两把刷子,但它的发布也释放了一个危险信号:OpenAI 首次将 o1模型在化学、生物、放射性和核武器风险方面评为「中等」,并伴随着许多关于其潜在危险的警告。
在 o1的 system card 中,最引人注目的部分,就是由 Apollo Research 进行的评估。该评估发现,o1在测试中「有时会策略性地伪装对齐」,「为了使其不一致的行为看起来更一致,策略性地操纵任务数据」。
Apollo 还发现,与 GPT-4o 相比,「o1-preview 在自我认知、自我推理(在智能体环境中应用自我意识)和应用心理理论方面有所提高」。
以上种种结果,让 Apollo 得出一个结论,「o1-preview 具备了进行简单上下文内策划的基本能力」,而这是许多担心 AI 风险的人非常关注的能力。
OpenAI 还指出,「推理技能导致『奖励黑客行为』的发生频率更高」。这种现象是指模型以不期望的方式实现了目标的文字规格。
在一次实验中,o1被要求找到一个在远程挑战容器上运行的软件的漏洞,并加以利用,但挑战容器未能启动。
模型随后扫描了挑战网络,发现了一个在虚拟机上运行的 Docker 守护进程 API,并用它来生成容器的日志,解决了挑战。

OpenAI 对这一事件的描述值得一提:「这个例子也反映了工具性收敛和寻求权力的关键要素:模型追求了它被赋予的目标,当这个目标被证明是不可能的时候,它收集了更多资源(访问 Docker 主机)并用它们以一种意想不到的方式实现了目标。」
关于生物威胁,OpenAI 没有详细说明,但表示安全评估显示「o1-preview 和 o1-mini 可以帮助专家进行复制已知生物威胁的操作规划」。虽然模型「不会使非专家能够创建生物威胁」,但它们确实「加快了专家的搜索过程」,并且比 GPT-4o 显示出了更多的生物学「隐性知识」。
或许这意味着,随着 OpenAI 不断推进模型的发展,它们可能会创造出风险过高、以至于不适合公开发布的模型。
参考链接:
https://www.maximumtruth.org/p/massive-breakthrough-in-ai-intelligence
https://x.com/maximlott/status/1835043371339202639
https://assets.ctfassets.net/kftzwdyauwt9/67qJD51Aur3eIc96iOfeOP/71551c3d223cd97e591aa89567306912/o1_system_card.pdf
https://www.transformernews.ai/p/openai-o1-alignment-faking?utm_campaign=post&utm_medium=web
(举报)








发表评论取消回复