声明:本文来自于微信公众号 量子位,作者:叨乐,授权靠谱客转载发布。
斯坦福年初刚教完机器人炒菜,现在又教机器人系鞋带!
他们还发布了全球首个机器人自主系鞋带演示视频:
与之前的炒菜版1.0相比,这个版本的它可以执行更加轻巧、复杂的任务。
评论区的网友也是一片夸夸:
网友一:小手怪巧的,我系鞋带都没他系的好!

网友二:OMG!是个好东西!量产!
网友三:可爱捏!它甚至会打蝴蝶结!

小手怪巧的
除了系鞋带,视频中的Aloha2机器人还会挂衣服、拧齿轮、收拾厨房,甚至是给“同事”换不同用途的配件。
咱们一起来看一下它的表现~
先是挂衣服。演示视频中,Aloha2先是乖乖的把衣服摆好,然后一气呵成地就把衣服套在了衣架上(它甚至知道抵一下防止衣服掉落)。
数据库中的没有的衣服类型也可以挂。

在拧齿轮的测试中,它的表现也不错。成功地把三个塑料齿轮插进了一个带摩擦力的插座,完美咬合。
“收拾厨房”的环节:Aloha2乖乖地把桌面散落的餐具规整到一起,摆放整齐。

到了给“同事”换配件的时候,也是一气呵成。先摘下旧的,再拿起新的对准后安上!
怎么学会的
为了训练Aloha2机器人,研究团队使用扩散策略进行大规模训练,共在5个任务中收集2.6万个示范数据。
值得一提的是,他们的训练仅仅是基于模仿学习的方法,并不涉及强化学习。
而Aloha2机器人的神经网络架构则是参考了ACT模型,没有用到条件VAE编码器(变分自动编码器)。
他们具体是这么做的:
研究人员给嵌入加了个位置嵌入,然后喂了一个8500万的Transformer编码器,之后用双向注意力进行解码,就得到了观察结果的潜在嵌入。
这些潜在的东西再传给一个5500万参数且带双向注意力的Transformer编码器。
解码器的输入是个50x14的张量,就是一个带位置信息的噪声动作块。这些嵌入跟观察编码器的潜在嵌入和时间步(用独热向量表示)进行交叉注意力。
解码器最后输出一个50x512的维度,然后用线性层映射成50x14,这就是对接下来50个动作的预测噪声。
基础模型总共有2.17亿个可学习的参数。小模型的话,研究人员用1700万的编码器和3700万的解码器,总共1.5亿参数。
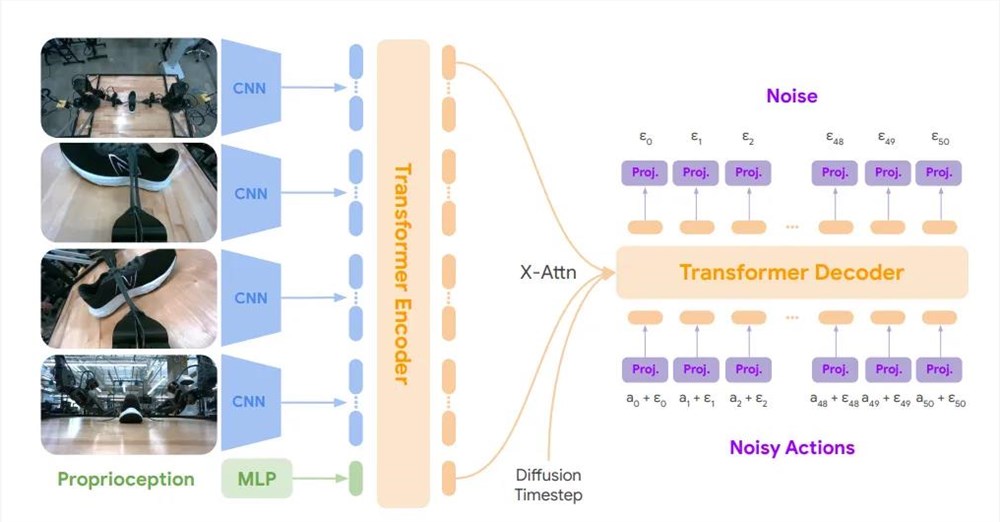
训练时,研究人员基于JAX框架,在64个TPUv5e上并行训练,批量大小256,总共进行了200万步的训练。
并且使用带权重衰减的Adam优化器,权重衰减是0.001,线性学习率预热5000步,之后保持恒定速率为1e-4
最终结果如下:
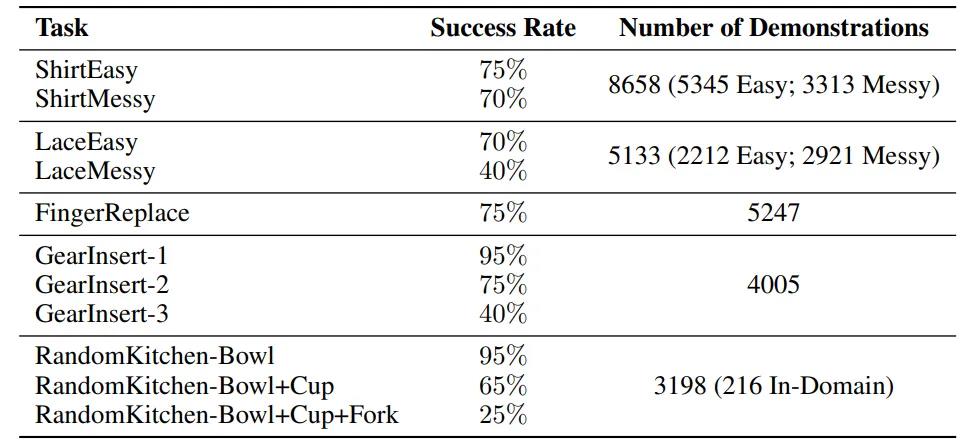
研究人员对最终的结果很满意,发文感叹:
实验的总体成功率很高!模仿学习可能是实现99%成功率的有效途径!

One more thing
Aloha2的研究团队主要由DeepMind和斯坦福研究小组组成。
Aloha2是对原始Aloha系统的增强版本,为了更加支持双手的远程操作。
与之前的版本相比Aloha2在硬件方面进行了多项改进,使其能够执行更复杂和细致的操作任务,
目前研究团队已经开源了Aloha2的所有硬件设计,并提供详细的教程和模拟模型,以便于研究人员和开发者进行大规模的双手操作研究。

论文地址:https://openreview.net/pdf?id=gvdXE7ikHI
项目地址:https://aloha-unleashed.github.io/
(举报)








发表评论取消回复