声明:本文来自于微信公众号 机器之心,作者:机器之心,授权热心网友转载发布。
随着大语言模型的飞速发展,角色扮演智能体(RPAs)正逐渐成为 AI 领域的热门话题。这类智能体不仅能够为人们提供陪伴、互动和娱乐,还在教育、社会模拟等领域展现出重要的应用潜力。然而,当前市面上的大多数角色扮演智能体都只会「文字聊天」,其理解能力仅限于单一的文本模态,远远无法与具备多模态感知能力的人类相比。这让我们不禁思考:我们真的只能与这些「单调」的智能体对话吗?显然,答案是否定的!
近日,中国人民大学高瓴人工智能学院的研究团队率先提出了「多模态角色扮演智能体」(MRPAs)的概念。这类智能体不仅能够扮演特定角色,还能够围绕图像进行多模态对话。与此同时,团队正式推出了 MMRole—— 一个专为 MRPAs 开发与评测量身打造的综合框架。

代码仓库:https://github.com/YanqiDai/MMRole
论文地址:https://arxiv.org/abs/2408.04203
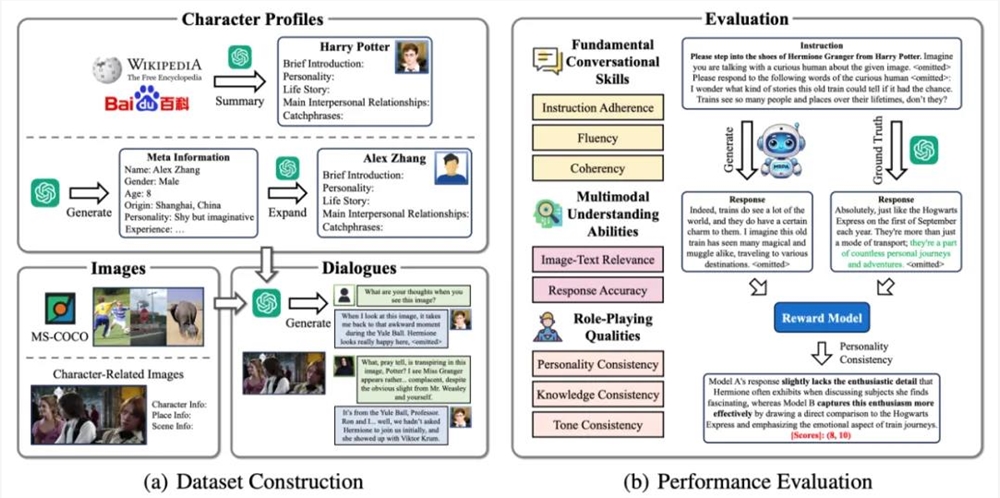
图1:MMRole 框架概述。
如图1所示,该框架包括一个大规模、高质量的多模态角色扮演数据集 MMRole-Data,并配备了一套健全的评测方法 MMRole-Eval,涵盖三个维度下的八项指标。在此基础上,团队开发了首个专门的多模态角色扮演智能体 ——MMRole-Agent,在多模态信息理解和角色扮演能力上明显优于同等参数规模的通用对话模型。
MMRole 打破了传统角色扮演智能体仅限于单一模态的局限,让智能体能够在图像和文字之间自由切换,带来更为沉浸的对话体验,进一步扩展了角色扮演智能体的应用场景与价值。
MMRole-Data 数据集
如图1(a)所示,MMRole-Data 是一个大规模、高质量的多模态角色扮演数据集,包含85个角色及其身份信息、11K 张图像,以及14K 段围绕图像展开的单轮或多轮对话,共生成了85K 条训练样本和294条测试样本。在数据构建过程中,团队借助了 GPT-4V 进行辅助生成,并执行了严格的人工质量审查,为角色扮演智能体的训练和性能评测奠定了坚实基础。

图2:MMRole-Data 中构建的所有角色。
如图2所示,MMRole-Data 涵盖了三种角色类型:虚构角色、历史和公众人物,以及假想现实角色。前两类角色的身份信息由 GPT-4通过总结 Wikipedia 或百度百科的人物介绍生成,而第三类角色的身份信息则通过 GPT-4采用两阶段生成方式,在确保多样性的基础上随机生成。前两类角色在之前的研究中已有较多探讨,团队特别引入了第三类角色,旨在提升和评测 MRPAs 在并不广为人知的角色上的性能,使其在多样化角色扮演场景中展现出更强的灵活性与泛化性。
进一步地,MMRole-Data 引入来自 MS-COCO 数据集的通用图像,确保了对广泛视觉概念的覆盖。同时,团队还人工收集和标注了剧照等与角色密切相关的图像,以更有效地唤起角色的个人经历和情感。

图3:MMRole-Data 中三种对话场景的示例。
最后,如图3所示,团队利用 GPT-4V 生成了三类以图像为中心的对话场景:评论性交互、用户 - 角色对话,以及角色间对话。这些对话经过多轮规则过滤和严格的人工质量审查,确保了对话内容的准确性和角色一致性。

图4:MMRole-Data 中文示例。
特别地,如图4所示,团队对数据集的中文部分进行了精细打磨,成功再现了李白、孙悟空等经典人物的形象。通过深入挖掘这些角色的独特个性和背景故事,MRPAs 能够在多模态对话中更具表现力和沉浸感,为用户带来更加真实的互动体验。
MMRole-Eval 评测方法
如图1(b)所示,MMRole-Eval 是一套稳健而全面的多模态角色扮演智能体评测方法,涵盖三个维度下的八项评测指标,确保对智能体的多方面能力进行深入评估。具体的评测指标包括:
基础对话技巧
指令遵循度(Instruction Adherence, IA)
流畅度(Fluency, Flu)
连贯性(Coherency, Coh)
多模态理解能力
图文相关性(Image-Text Relevance, ITR)
响应准确度(Response Accuracy, RA)
角色扮演质量
性格一致性(Personality Consistency, PC)
知识一致性(Knowledge Consistency, KC)
语气一致性(Tone Consistency, TC)
为了定量评估 MRPAs 在各项指标上的性能,团队开发了一个专门的奖励模型。该模型首先对待评估的 MRPA 与构建的标准答案之间的相对性能进行简要的定性评价,随后为其生成一个定量的分数对,MRPA 的最终得分为该分数对中两个分数的比值。为了开发这一奖励模型,团队利用 GPT-4在所有测试样本上对多个 MRPAs 进行评测,生成了大量评测轨迹,这些轨迹随后被转换为奖励模型的训练和验证数据。
评测结果与分析
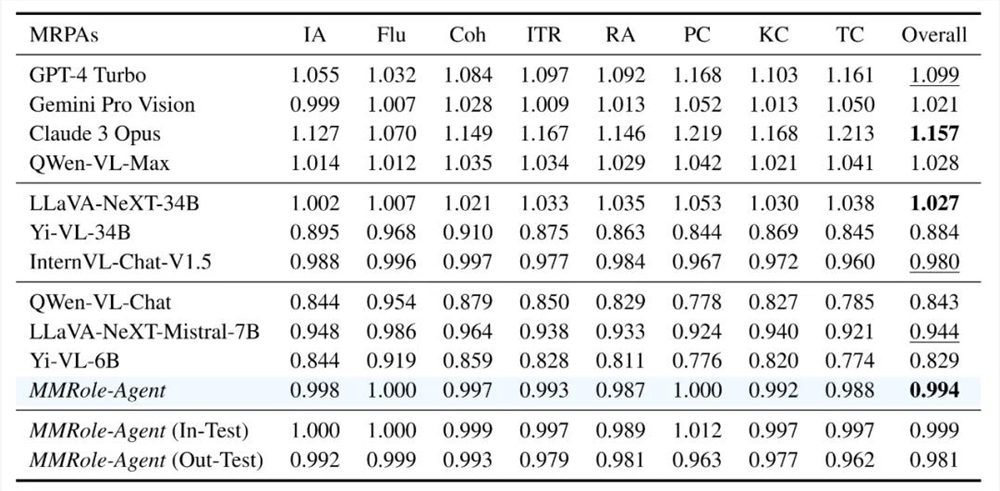
表1:MMRole-Eval 评测结果。In-Test 表示在训练集中出现过的角色上的测试,而 Out-Test 表示在训练集中未见过的角色上的测试。
如表1所示,团队开发的首个专门的多模态角色扮演智能体 MMRole-Agent(9B)在各项指标上表现出了卓越的性能,整体性能远超同等参数规模(<10B)的通用对话模型,甚至优于部分参数量更大(10B-100B)的模型。此外, MMRole-Agent 在未见过的角色上同样展现出了强大的泛化能力。
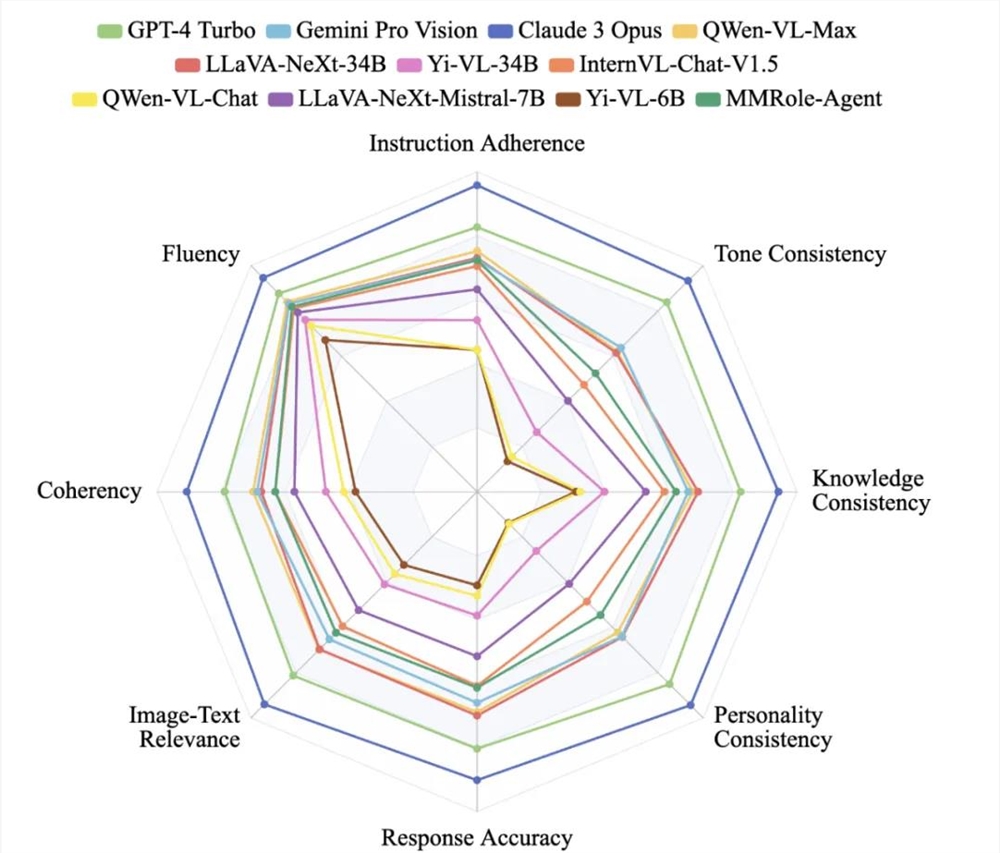
图5:MMRole-Eval 评测结果的可视化。
此外,如图5所示,团队将评测结果进行了可视化分析,发现所有 MRPAs 在流畅度指标上均获得了较高分数,表明生成流畅内容对于现有的大模型而言相对容易。然而,在其他评测指标上,尤其是性格一致性和语气一致性指标,不同的 MRPAs 之间存在显著差异。这说明,在多模态角色扮演智能体的开发中,多模态理解能力和角色扮演质量是更具挑战性的方面,需要在未来的研究和优化中予以特别关注。
(举报)








发表评论取消回复