声明:本文来自于微信公众号 新智元,作者:新智元,授权靠谱客转载发布。
【新智元导读】刚刚,OpenAI重金押注的人形机器人初创1X终于揭秘了背后的「世界模型」——它能够根据真实数据,生成针对不同场景的中的行为预测!机器人领域的ChatGPT时刻,或许真的要来了。
月初,OpenAI投下重注人形机器人初创1X,终于放出了NEO官宣视频。
它的首次现身,就惊艳到所有人。
不仅外观上,被戏称为「穿着西装的人」,而且在能力上,帮女主拎包、一起下厨,妥妥的一个通用家庭机器人。

它专为人类设计,去完成我们不愿意做的各种家庭任务,比如清洁、整理等等。
时隔半个月,1X终于发布了NEO背后的「世界模型」。
有了这个虚拟世界模拟器,NEO可以预测有用的物体交互。
简言之,它们完全可以生成,各种环境中的视频画面。
比如,叠一件T恤、拉开窗帘这类可变性物体,家里随处可见,但却很难将其放入虚拟世界模拟器中。

有趣的是,1X AI副总裁Eric Jang称,他们在办公室专门放了一个全身镜,这样「模型」可以在镜子中,认出自己。
NEO现在有了自我反思的能力,不过,自我意识还没觉醒。

通过理解世界,并与之交互,1X「世界模型」可以生成高保真视频,并在神经网络中,重新规划、模拟和评估。

这也是世界模型,之于机器人的重要性。
1X创始人兼CEO Bernt Bornich表示,首次证明了人形机器人数据,正显著地推进Scaling Law。
谷歌DeepMind机器人高级研究员Ted Xiao表示,1X的「学习型」世界模型能够随着惊艳、物理交互数据不断改进。
- 世界模型很可能是在多智能体环境中,实现可重复和可扩展评估的唯一前进的方向。(参加自动驾驶中世界模型评估成功案例)
- 基于2024年AI技术,比基于去年的技术更容易构建世界模型。
- 一旦世界模型足以用于评估,它们很可能已经至少完成了90%的训练工作。

机器人「世界模型」来了!
直白讲,世界模型就是一种计算机程序。
它能够想象出,世界如何随着智能体的行为而演变。
基于视频生成和自动驾驶汽车世界模型研究,1X由此训练出自家的世界模型,作为NEO的虚拟模拟器。
从相同的起始图像序列出发,1X世界模型可以根据不同机器人的动作,预测多种可能的未来场景。

左:去左侧的门;中:弹空气吉他;右:去右侧的门
那么,具身机器人的存在,最重要的是能够与物理世界交互。
而在万千繁杂的世界中,如何有效交互就成为了难题。
世界模型,能够帮助NEO完成精准地交互,比如刚体、物体掉落的效果、不完全可见物体(杯子)、可变形物体(窗帘、衣物)、铰接物体(门、抽屉、椅子)。
它能够将餐盘放入沥水架子中。

它还可以拉开窗帘。

从抽屉拿出东西等等。

具身机器人难题——评估
另外,世界模型解决了构建通用机器人时,一个非常实际但常被忽视的挑战:评估。
假设训练机器人执行1000个独特的任务,那么很难判断一个新模型是否真的在所有任务上,都比之前的模型有所改进。
更令人困扰的是,即便模型权重相同,但由于环境背景或环境光线的细微变化,性能可能在短短几天内下降。
研究人员训练了一个机器人叠T恤的模型,性能在50天内逐渐下降。
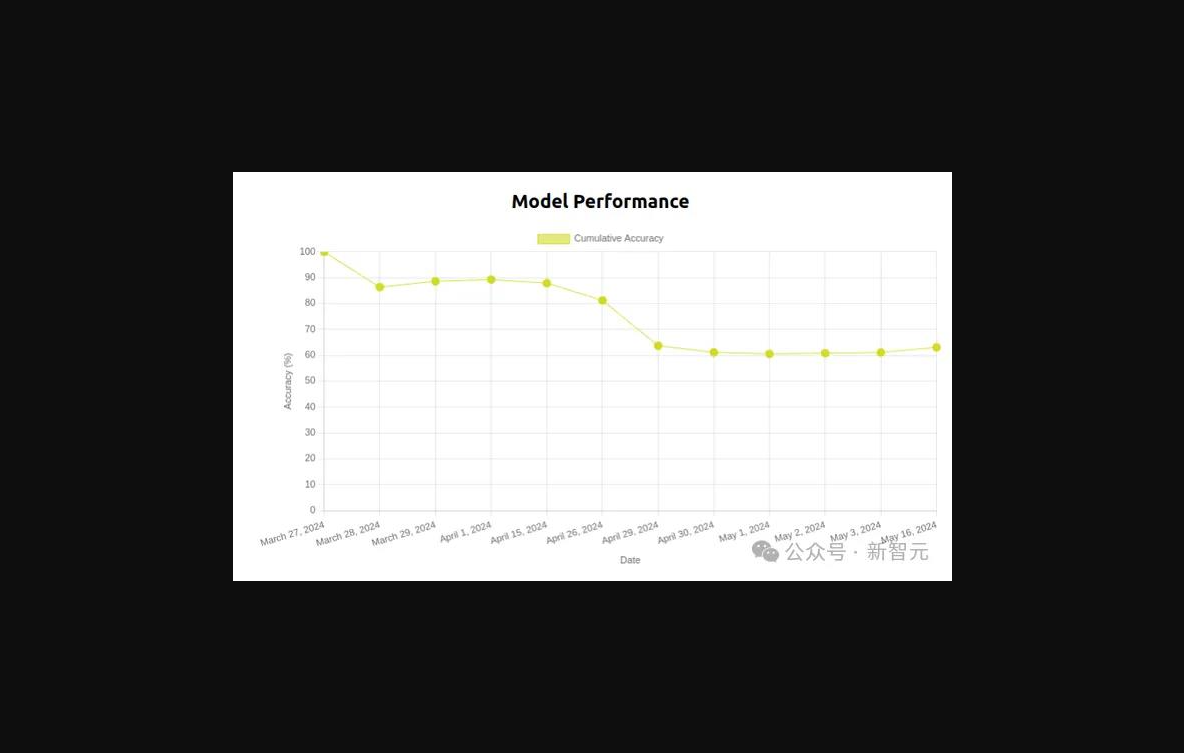
而且,如果环境不断持续变化,实验的可重复性便成为难题。
尤其是,在家庭、办公室这样的环境中,去评估多任务系统,这一问题就会变得更加棘手。
基于这些因素,使得在真实世界中,开启严谨的机器人研究变得异常困难。
当scaling数据、算力、模型规模时,AI系统能力将如何扩展的问题,可以通过精准测量进行预测。
Scaling Law已经成为ChatGPT这样的通用AI系统,性能提升的有力支撑。
因此,如果机器人领域想要迎来属于自己的「ChatGPT时刻」,必须首先建立起它的「Scaling Law」。
从原生数据中学习,预测未来场景
基于物理模拟的引擎,诸如Bullet、Mujoco、Isaac Sim、Drake,已成为快速测试机器人策略的合理方法。
而且,这些模拟器可以重置、重复使用,进而研究人员能够仔细比较不同控制算法。
然而,这些模拟器主要是为「刚体动力学」设计的,并且需要大量人工数据收集。
那么,如何让模拟机器人打开一盒咖啡滤纸、用刀切水果、拧开一罐果酱,或与人类、其他AI智能体互动呢?
家庭环境中,常见的日常物品、宠物很难模拟,训练机器人极度缺少真实世界的用例。
因此,在有限数量任务中,对机器人进行小规模真实/模拟评估,并不能准确预测其在真实世界中的表现。
也就是说,这样训练出的机器人,很难具备真实世界「通用泛化」能力。
1X研究团队采取了全新的方法,来评估通过机器人:
直接从原生传感器数据中学习模拟,并利用它在数百万情境中,评估机器人策略。
这种「世界模型」方法的优势在于,可以一键获得真实世界所有复杂数据,而无需手动创建资产。
过去一年里,1X团队收集了超5000小时EVE人形机器人数据。
这些数据包括,机器人在家庭和办公室环境中,执行各种移动操作任务,以及与人互动的场景。
然后,他们将视频和动作数据结合,训出一个世界模型。
这个模型非常强大,不仅能够根据所观察到的情况,执行动作,还能生成视频,预测未来的场景画面。












动作可控,「脑补」弹空气吉他
1X世界模型能够根据不同的动作指令,生成多样化的输出。
如下图所示,展示了基于四种不同动作序列,生成的各种结果。这些动作序列,都是从相同的初始画面帧开始。
与之前一样,这些所展示的示例,都不包含在训练数据中。



世界模型的主要价值在于,能够模拟物体之间的交互。
在接下来的模拟生成中,研究人员为模型提供相同的初始场景,并设置了三组不同的抓取盒子的动作。
在每个模拟场景中,被抓取的盒子,会随机械手运动而被提起和移动,而其他未被抓取盒子纹丝不动,保持原位。

即便没有给出具体的动作指令,世界模型也能生成看起来合情合理的视频。
比如说,它能自己在前行时,避开行人和障碍物,这种行为是很符合常理的。


模拟叠T恤,长期任务也在行
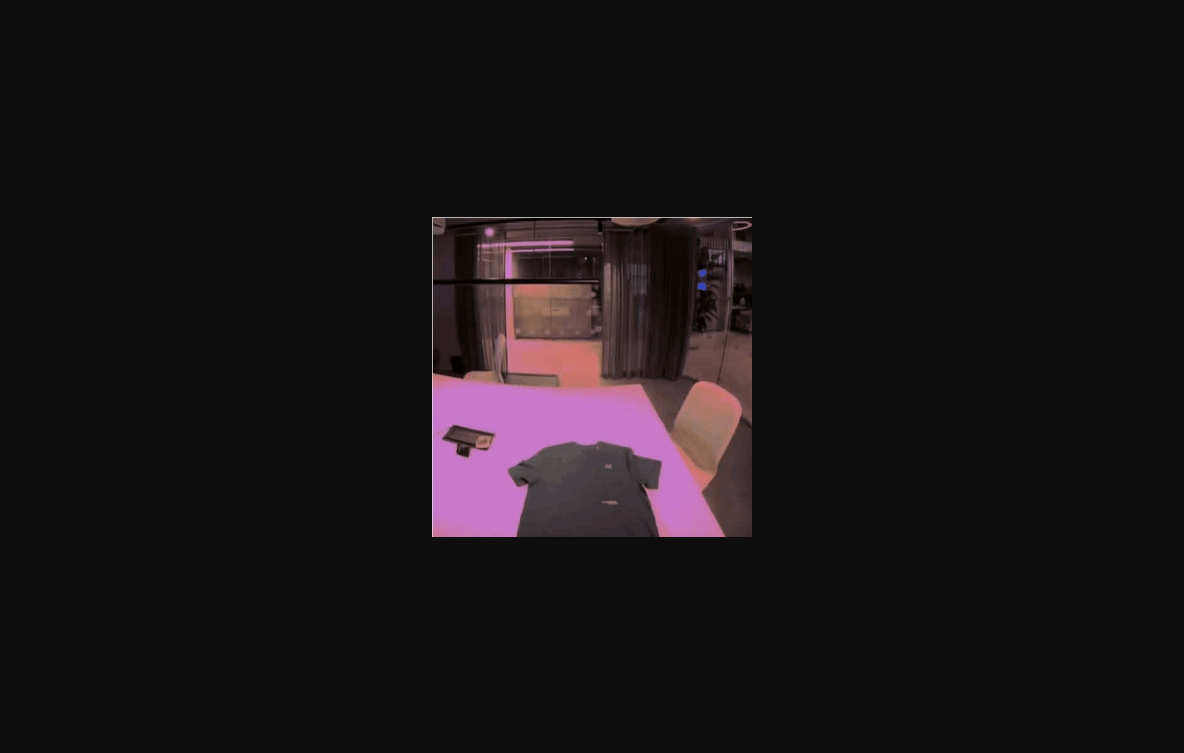
此外,1X还可以生成长视频。
正如开头所展示的例子,NEO模拟了一个完整的T恤折叠演示。
值得一提的是,T恤等可变形物体,往往在「刚体模拟器」中难以实现。
当前存在的问题
不过,1X的世界模型同样存在一些问题。
物体一致性
比如,模型在与物体交互的过程中,可能无法保持物体的形状的和颜色一致性。
尤其是当物体被遮挡,或者以不理想角度呈现时,世界模型在生成视频过程中,物体外观可能会出现变形。

有时,物体甚至完全消失不见。
比如,在执行拿起红色小球并放置在盘子上这一动作时,球在过程中莫名其妙地就消失了。

物理学定律
而且,它也不懂物理世界中的基本定律。
有时候,NEO能够对物理属性有自然的理解,比如松开机械手之后,勺子会掉落到桌子上。

但在很多情况下,生成的结果并没有遵循物理法则,比如下面这个,盘子就直接悬在了空中。
这说明,世界模型并不理解所有物体,都受到竖直向下的重力作用。

自我认知
另外,研究人员让AI机器人EVE走到镜子前,观察其是否会生成与镜子中的相对应的行为。
没想到,它在抬起另一只手臂时,镜子中没有同步。
可见,现在1X模型没有自我意识的表现。


参考资料:
https://x.com/ericjang11/status/1836096888178987455
https://x.com/1x_tech/status/1836094175630200978
(举报)








发表评论取消回复