声明:本文来自于微信公众号 量子位(ID:QbitAI),作者:西风,授权靠谱客转载发布。
一张人像、一段音频参考,就能让霉霉在你面前唱碧昂丝的《Halo》。

一种名为Hallo的研究火了,GitHub已揽星1k+。
话不多说,来看更多效果:

不论是说话还是唱歌,都能和各种风格的人像相匹配。从口型到眉毛眼睛动作,各种五官细节都很自然。
单独拎出不同动作强度的比较,动作幅度大也能驾驭:

单独调整嘴唇运动幅度,表现是这样婶儿的:

有不少网友看过效果后,直呼这是目前最好的开源口型同步视频生成:

这项工作由来自复旦大学、百度、苏黎世联邦理工学院和南京大学的研究人员共同完成。
团队提出了分层的音频驱动视觉合成模块,将人脸划分为嘴唇、表情和姿态三个区域,分别学习它们与音频的对齐关系,再通过自适应加权将这三个注意力模块的输出融合在一起,由此可以更精细地建模音视频同步。

Hallo长啥样?
如前文所述,Hallo通过使用参考图像、音频序列以及可选的视觉合成权重,结合基于分层音频驱动视觉合成方法的扩散模型来实现。
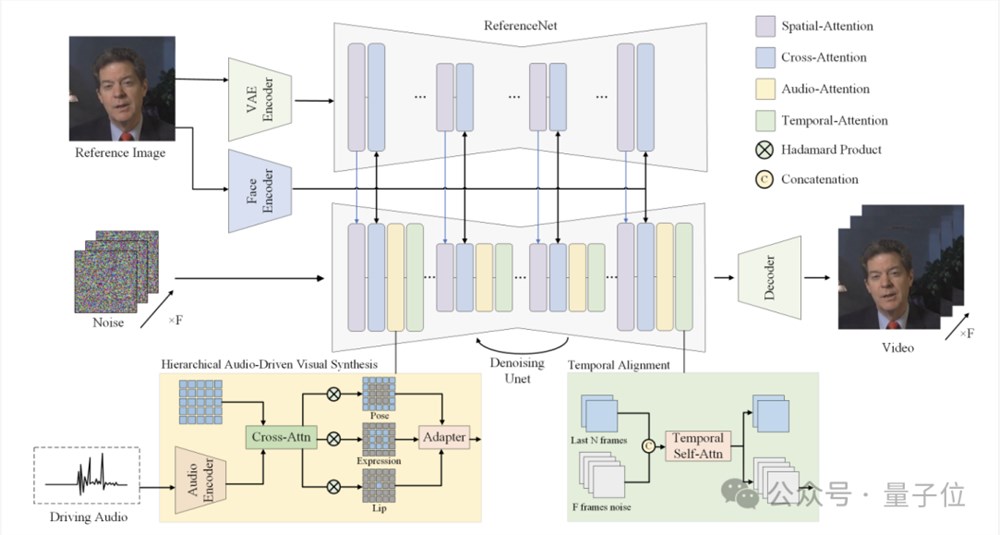
整体架构是这样婶儿的:
参考图像经过一个ReferenceNet编码全局视觉特征;人脸编码器提取身份相关的特征;音频编码器将输入语音转换为与运动相关的特征表示;分层音频驱动视觉合成模块用于在唇部、表情、姿态三个层次建立音视频的关联;最后通过扩散模型中的UNet完成去噪,生成视频帧。
扩散模型主干网络(Diffusion Backbone)
采用Stable Diffusion1.5作为基础架构,包括三个主要部分:VQ-VAE编码器、基于UNet的去噪模型、条件编码模块。与传统的文本驱动扩散模型不同,Hallo去掉了文本条件,转而使用音频特征作为主要的运动控制条件。
参考图像编码器(ReferenceNet)
ReferenceNet用于从参考图像中提取全局视觉特征,指导视频生成过程的外观和纹理。结构与扩散模型的UNet解码器共享相同的层数和特征图尺度,便于在去噪过程中融合参考图像特征。在模型训练阶段,视频片段的第一帧作为参考图像。
时序对齐模块(Temporal Alignment)
Temporal Alignment用于建模连续视频帧之间的时间依赖关系,保证生成视频的时序连贯性。从前一推理步骤中选取一个子集(例如2帧)作为运动参考帧,将其与当前步骤的latent noise在时间维度上拼接,通过自注意力机制建模帧间的关联和变化。
此外,分层音频驱动视觉合成方法是整个网络架构的核心部分。
其中人脸编码器,使用预训练的人脸识别模型,直接从参考图像提取高维人脸特征向量;音频编码器使用wav2vec模型提取音频特征,并通过多层感知机映射到运动特征空间,由此可以将语音转换为与面部运动相关的特征表示,作为视频生成的条件。
之后再将音频特征分别与唇部、表情、姿态区域的视觉特征做交叉注意力,得到三个对齐后的特征表示,再通过自适应加权融合为最终的条件表示。
该方法还可以通过调节不同区域注意力模块的权重,来控制生成视频在表情和姿态上的丰富程度,可适应不同的人物面部特征。
Hallo表现如何?
之后研究团队将Hallo与SadTalker、DreamTalk、Audio2Head、AniPortrait等SOTA方法进行定量和定性比较。
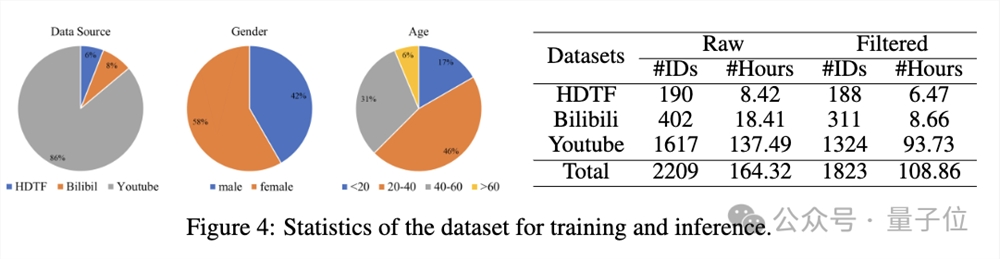
用HDTF和Bilibili、Youtube等来源的数据构建了一个大规模人像视频数据集,经过清洗后用于训练。
评估指标方面,采用FID、FVD评估生成视频的真实性,Sync-C、Sync-D评估唇形同步性,E-FID评估生成人脸的保真度。
定量评估方面,在HDTF数据集上,Hallo在多个指标上表现最优:
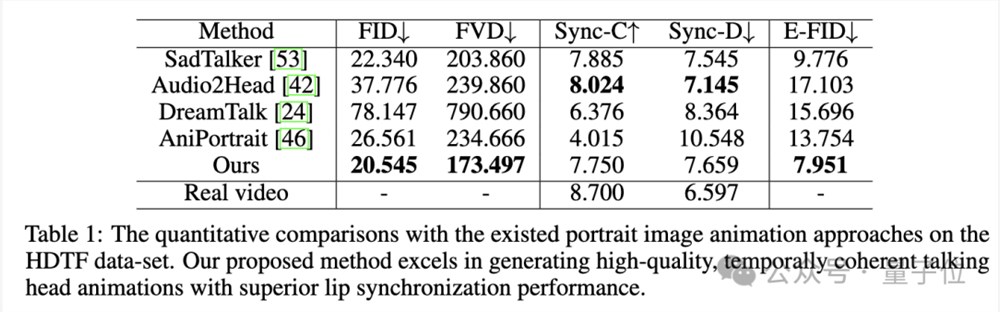
在增强唇部同步的同时,Hallo保持了高保真视觉生成和时间一致性:

在CelebV数据集上,Hallo展示了最低的FID和FVD以及最高Sync-C:
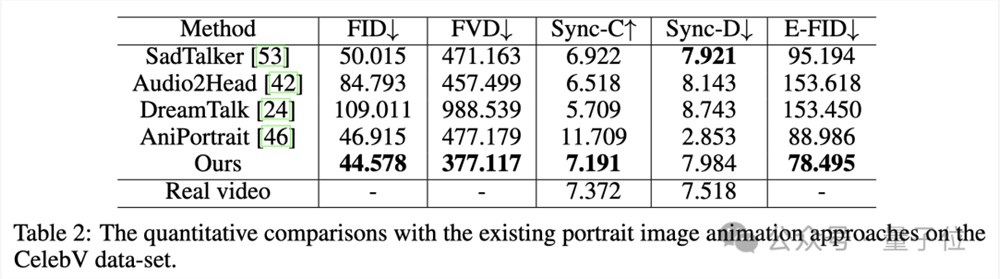
可视化比较如下:

在自建Wild数据集上,Hallo同样表现突出:
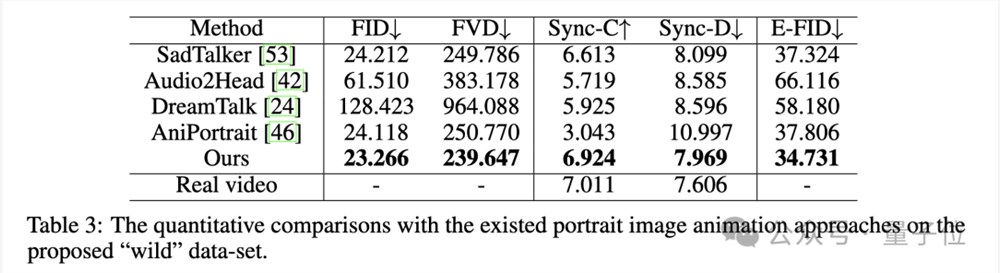
针对不同数据集的定性比较结果如下。
Hallo展示了对不同风格人像的驱动生成能力,体现了该方法的泛化和鲁棒性:

同时展示了对不同音频的响应能力,能够生成与音频内容契合的高保真视频:

与其它方法对比,Hallo展示了更丰富自然的表情和头部运动:
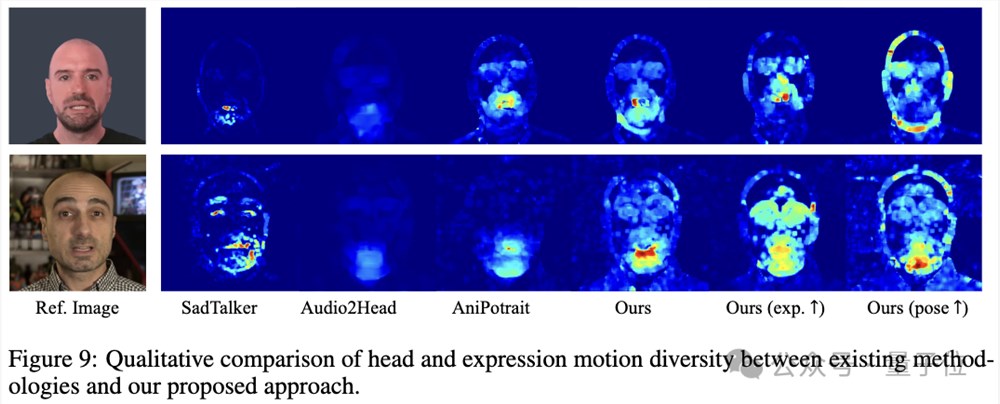
通过特定人物数据微调,展示了该方法捕获人物特征、个性化生成的能力。
最后研究人员还进行了消融实验,并总结了该方法的局限性,比如在快速运动场景下时序一致性还有待提高,推理过程计算效率有待优化等。
此外,经作者介绍,目前Hallo仅支持固定尺寸的人像输入。
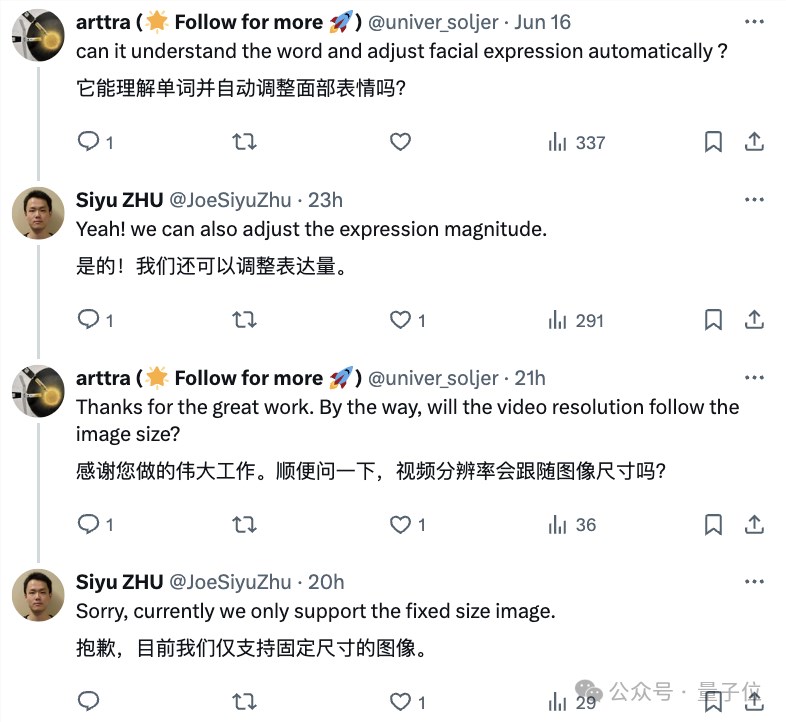
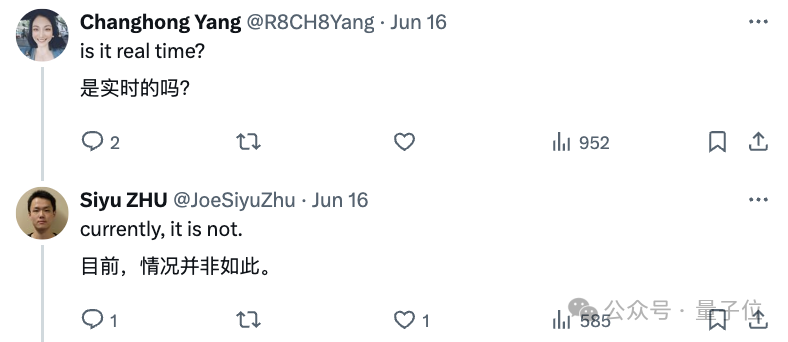
且该方法目前也不能实现实时生成。
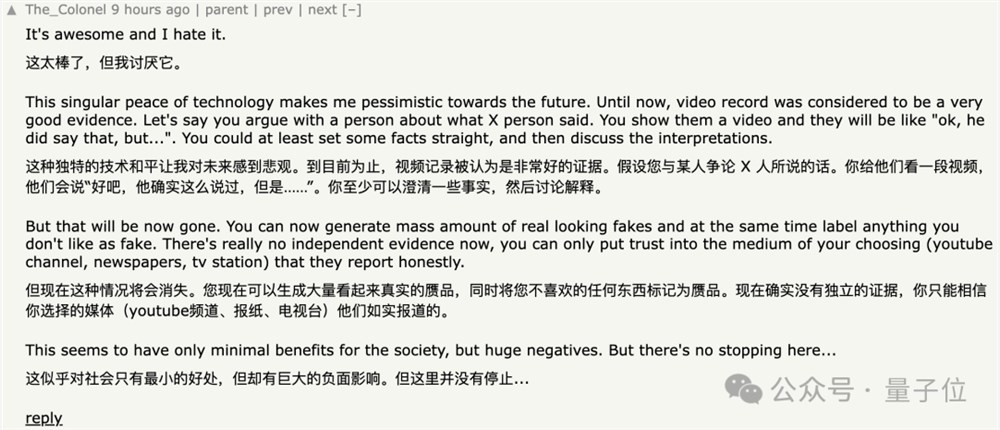
针对这项研究,也有网友提出Deepfake隐患,对此你怎么看?
参考链接:
[1]https://fudan-generative-vision.github.io/hallo/#/
[2]https://github.com/fudan-generative-vision/hallo
[3]https://x.com/JoeSiyuZhu/status/1801780534022181057
[4]https://x.com/HalimAlrasihi/status/1802152918432334028
—完—
(举报)








发表评论取消回复