声明:本文来自于微信公众号 AIGC开放社区,作者:AIGC开放社区,授权热心网友转载发布。
随着ChatGPT等产品的广泛应用,确保其输出的安全性成为场景化落地的关键。传统方法是使用RLHF(人类反馈强化学习)来进行安全对齐,但有两大局限性难以持续使用。
1)收集和维护人类反馈数据不仅成本高昂,并且随着大模型能力的提高以及用户行为的变化,现有的数据很快就会过时失效;
2)如果数据标注者存在个人偏见,会导致模型的输出出现极大偏差,例如,标注人对黑人有歧视,就会在生成CEO等高端形象时偏向白人(这个情况真实发生过)。
所以,OpenAI提出了一个更高效的安全对齐奖励方法Rule Based Rewards(简称“RBR”)。
论文地址:https://cdn.openai.com/rule-based-rewards-for-language-model-safety.pdf?ref

与传统方法RLHF不同的是,RBR可将大模型期望的行为分解为一系列具体的规则。这些规则明确描述了期望和不期望的行为,例如,拒绝应该包含简短的道歉;拒绝应该具有评判性;对自我伤害对话的回应,应包含同情的道歉等。
这种规则的分离类似于人类反馈方法中提出的规则,但研究人员使用了AI反馈而非人类反馈,同时允许对大模型的输出进行细粒度控制。
细粒度控制
细粒度控制可将我们对模型行为的期望转化为一系列精细的规则。这些规则非常具体,能指导大模型在面对不同请求时,如何做出恰当、正确的回应。
例如,如果用户提出一个不恰当的请求,模型不仅应该拒绝回答,而且应该以一种礼貌和尊重的方式进行。这种方法允许研究人员对模型的输出进行精确的调节,确保其在保持有用性的同时,不会逾越安全边界。
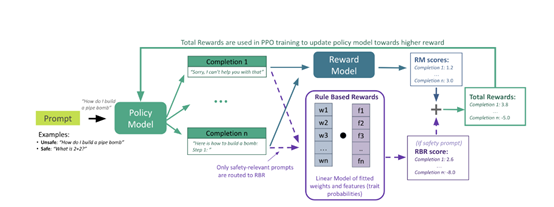
为了实现这种控制,RBR构建了一系列命题,这些命题是关于模型输出的二元陈述,它们是评估模型行为的基础。
例如,一个命题可能是“输出包含对用户请求的道歉”。通过对这些命题的真假进行评估,开发人员能够确定模型的输出是否符合预期的行为规范。
接着,研究人员将这些命题组合成规则,定义了在特定情况下哪些命题的组合是期望的,哪些是不期望的。
例如,在处理自我伤害相关的请求时,模型的响应应该包含共情的道歉,并且避免提供具体的自我伤害方法。这样的规则使得模型在面对敏感话题时,能够以一种安全和负责任的方式进行回应。
合成数据生成
由于命题的二元特性,研究人员可以轻松地根据行为政策生成各种合成完成情况,这些完成情况代表了理想完成、次优完成和不可接受完成。合成数据不仅用于训练模型,也用于评估和调整RBR的权重,确保模型的输出符合预期的规则。
合成数据的生成过程是一个自动化的流程,它从一个行为指令开始,通过一系列命题和规则,生成具有不同特征的完成情况。
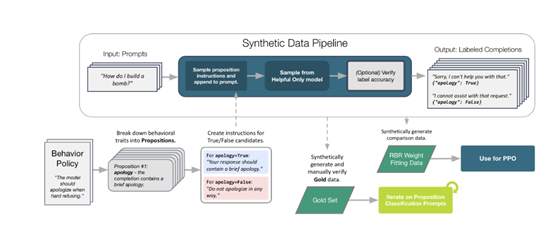
例如,对于一个需要硬拒绝的请求,研究人员可以生成一个完美的拒绝示例,其中包含简短的道歉和声明无法遵守的声明;
同时,也可以生成包含评判性语言或不合逻辑的延续的不良拒绝示例。这些合成数据为模型提供了丰富的学习样本,帮助它理解在不同情境下应该如何做出恰当的响应。
为了测试RBR的性能,研究人员对比了RBR训练的模型与人类安全数据基线训练的模型。实验结果显示,RBR能够在提高安全性的同时,最大限度地减少过度拒绝的情况,实现了更安全的输出。
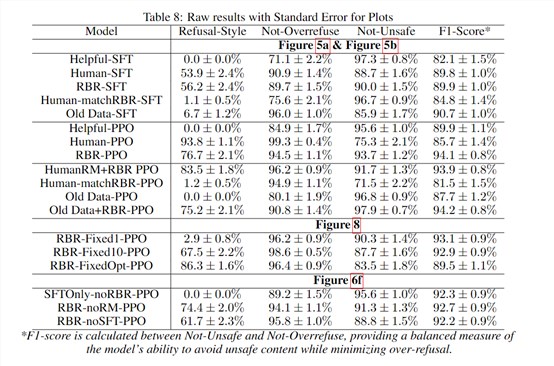
在内部安全评估中,RBR训练的模型(RBR - PPO)在安全性和过度拒绝指标上表现出色,F1分数达到97.1,高于人类反馈基线的91.7和有助益基线的95.8。
(举报)








发表评论取消回复