ES安装和hanlp插件安装参考《ElasticSearch分词器-ElasticSearch环境搭建及hanlp插件安装》
https://blog.csdn.net/skywalkeree/article/details/109527633
一.采用hanlp分词器建立分词索引
1. 进入kibana管理台Dev Tools页面
2. 输入如下请求,建立ES索引
表示建立名为hanlp_test的索引,为content字段采用hanlp分词建立索引,查询时同样采用hanlp进行检索
PUT hanlp_test
{
"settings": {
"index.analysis.analyzer.default.type": "hanlp"
},
"mappings": {
"doc": {
"properties": {
"content": {
"type": "text",
"analyzer": "hanlp"
, "search_analyzer": "hanlp"
}
}
}
}
}
索引建立成功会返回如下结果:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "hanlp_test"
}
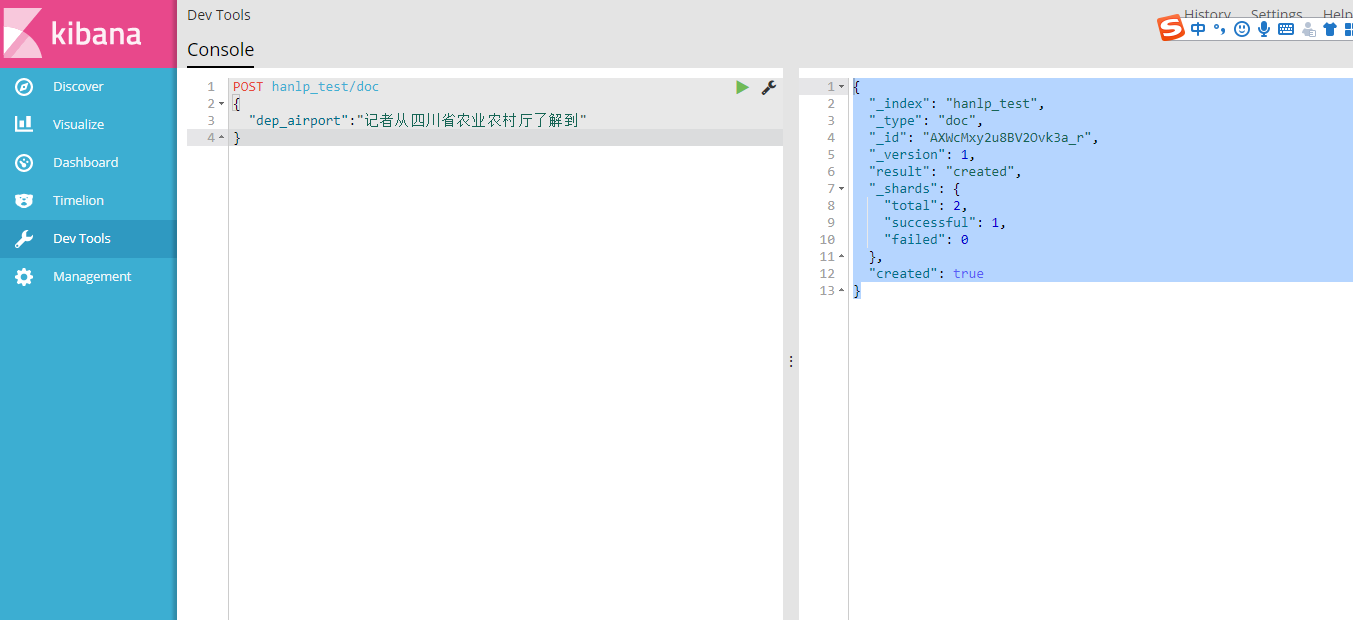
3. 插入测试文本
POST hanlp_test/doc
{
"dep_airport":"记者从四川省农业农村厅了解到"
}
插入成功后会返回如下结果:
{
"_index": "hanlp_test",
"_type": "doc",
"_id": "AXWcMxy2u8BV2Ovk3a_r",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
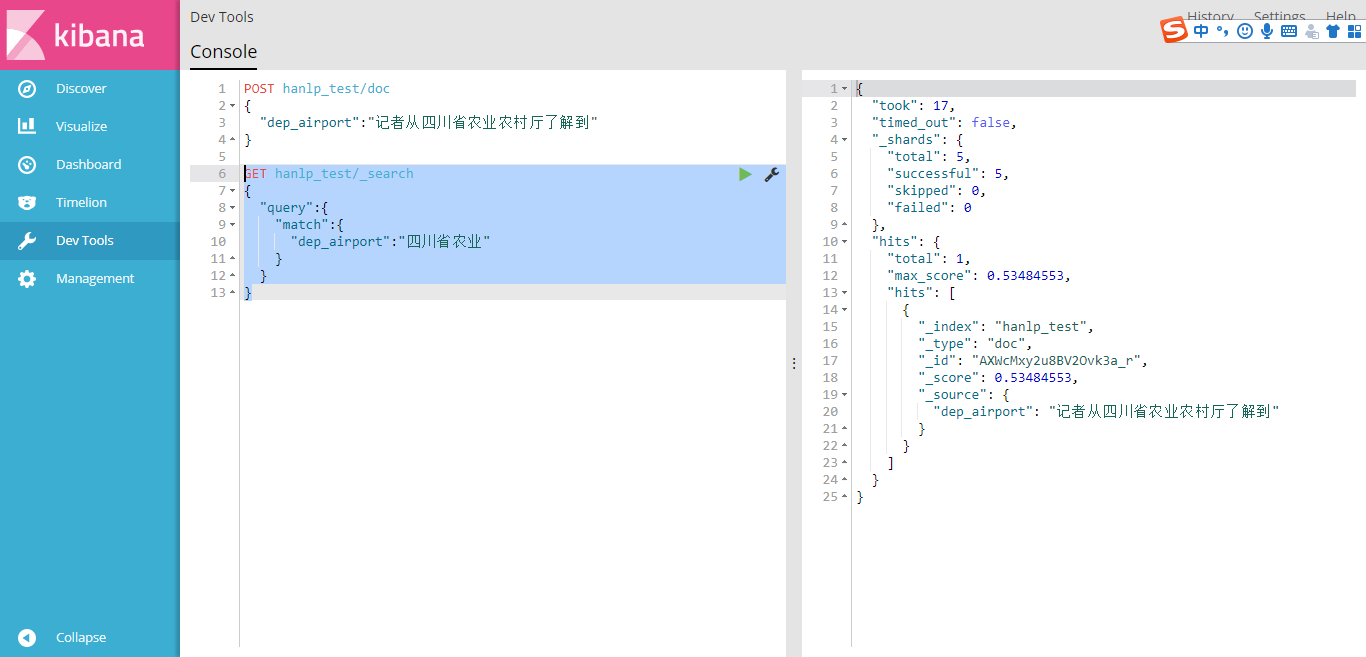
4. 文本检索
GET hanlp_test/_search
{
"query":{
"match":{
"dep_airport":"四川省农业"
}
}
}
返回如下结果:该结果表示查到了1个有效记录,最大匹配度为0.53484553。同时也返回了匹配的文本内容
至此,我们的基于hanlp的文本分词索引样例就完成了~
二.MySQL ES文本导入样例
实际情况下,我们采用python从mysql中将海量文本导入ES,导入时需要指定对应的索引,文本类型,和文本内容。
es.index(index='hanlp_test', doc_type='doc', body={"content":checkStr})import pymysql
from pyhanlp import *
from elasticsearch5 import Elasticsearch
#创建es对象
ES = [
'127.0.0.1:9200'
]
#创建elasticsearch客户端
es = Elasticsearch(
ES,
# 启动前嗅探es集群服务器
sniff_on_start=True,
# es集群服务器结点连接异常时是否刷新es节点信息
sniff_on_connection_fail=True,
# 每60秒刷新节点信息
sniffer_timeout=60
)
#创建mysql对象
db = pymysql.connect("127.0.0.1", "root", "root", "data_source")
cursor = db.cursor()
ite = 0
start = 0
checkSize = 1000
sql = "select id,content from my_data_source limit %s, 1000"
while checkSize == 1000:
ite=ite+1
cursor.execute(sql, start)
list = cursor.fetchall()
checkSize = 0
for item in list:
checkSize = checkSize+1
start = start+1
if item[1] != None:
#过滤无效字符
checkStr = item[1].replace("n","").strip()
#插入es
es.index(index='hanlp_test', doc_type='doc', body={"content":checkStr})
print(checkSize)
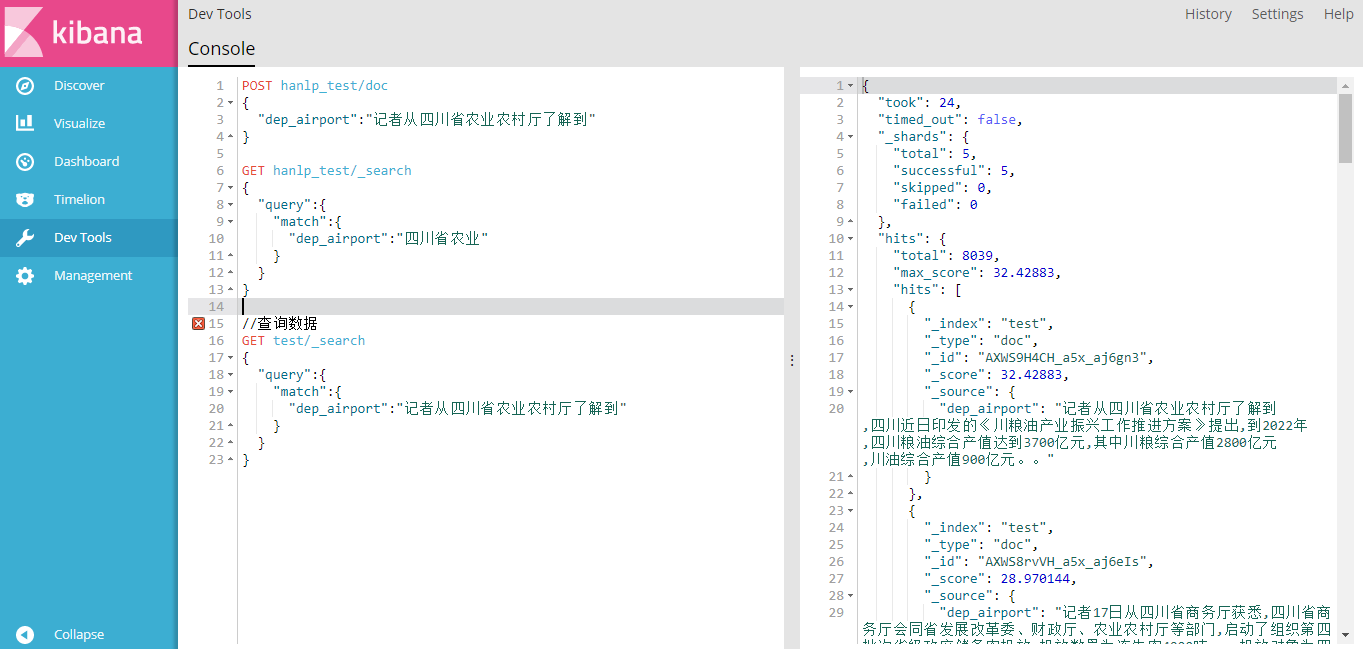
db.close()数据导入成功后,可以参考上面的文本检索样例进行文本检索,效果如下:
最后
以上就是淡定哈密瓜最近收集整理的关于ElasticSearch分词器-hanlp分词索引ES安装和hanlp插件安装参考《ElasticSearch分词器-ElasticSearch环境搭建及hanlp插件安装》一.采用hanlp分词器建立分词索引二.MySQL ES文本导入样例的全部内容,更多相关ElasticSearch分词器-hanlp分词索引ES安装和hanlp插件安装参考《ElasticSearch分词器-ElasticSearch环境搭建及hanlp插件安装》一.采用hanlp分词器建立分词索引二.MySQL内容请搜索靠谱客的其他文章。








发表评论 取消回复