一. 题目如下
1、在小文档集合(199801.txt)中建立一个索引文件:每一行是一条term,每个term后面跟着一个索引记录表,包括:文档频率、文档序号(对文档序号进行排序);整个索引对term进行排序。
考虑:Term如何定义?
2、基于上述小文档集(199801.txt) ,建立一个位置索引文件。
199801.txt文档集截图:

索引文件结果效果如下图:
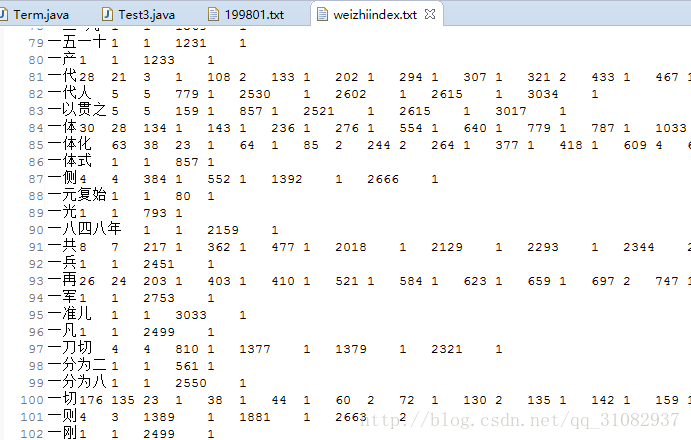
索引文件表结构:
词 出现次数 包含该词的段落个数 段落x… 段落x…中出现词次数
比如图中:”一代” 出现28次 包含该词的段落有21个,其中第3段出现一次,第108段出现两次
二. 实现目标
1. 分段编号,分词
2. 构建索引的数据结构
3. 构建索引
三. 实现步骤
1.段落编号,仔细观察,文档已经给我们分好段了

2.分词,不多解释了,有疑问,请看第一篇自然语言处理基于java实现(1) 之 中文分词
3.索引数据结构
1)词条,何为词条?
如上图中”一代”,那一行数据就为一条词条
词条数据结构如下
/**
*词条
*/
public class Term implements Comparable<Term>{
//单词
private String word;
//包含该单词的文档个数
private int ndoc;
//单词出现的次数
private int freq;
//单词对应的文档的次数
// 文档id 单词次数
private Map<Integer,Integer> map = new TreeMap<Integer,Integer>();
public Term() {
super();
}
@Override
public int hashCode() {
return word.hashCode();
}
@Override
public String toString() {
return word.toString();
}
@Override
public boolean equals(Object obj) {
return word.equals((String)obj);
}
@Override
public int compareTo(Term o) {
return word.compareTo(o.word);
}
public Term add(int docId){
freq++;
ndoc = (map.containsKey(docId))?ndoc:ndoc+1;
map.put(docId, map.getOrDefault(docId, 0)+1);
return this;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public Integer getNdoc() {
return ndoc;
}
public void setNdoc(Integer ndoc) {
this.ndoc = ndoc;
}
public void setFreq(Integer freq) {
this.freq = freq;
}
public Integer getFreq() {
return freq;
}
public Map<Integer, Integer> getMap() {
return map;
}
public void setMap(Map<Integer, Integer> map) {
this.map = map;
}
}
2) 词条列表,也就是索引表罗,写进文本,就成了索引文件了
package experiment3;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import java.util.Map.Entry;
/**
* 词条表
*/
public class TermList {
//文档列表
private final List<String> document = new ArrayList<>();
//词条集合
private final Map<Term,Term> set = new TreeMap<Term,Term>();
/**
* 获得Term词条列表
* @return
*/
public List<Term> getList() {
return new ArrayList<Term>(set.keySet());
}
/**
* 获得文档集合
* @return
*/
public List<String> getDocument(){
return new ArrayList<String>(document);
}
/**
* 根据word获得Term
* @param word
* @return
*/
public Term getTerm(String word){
Term term = new Term();
term.setWord(word);
return set.getOrDefault(term, null);
}
/**
* 根据content构造TermList
* @param content
*/
public TermList(String content){
String[] msg = content
.replaceAll("n.{0,20}/m", "")
.replaceAll(" .{1,8}/m", "")
.replaceAll("\[", "").replaceAll("]", "")
.replaceAll("/[a-z|A-Z]{1,3}", "").split("n");
msg[0] = msg[0].substring(msg[0].indexOf(' ')+1);
for(int i = 0;i<msg.length;i++){
String[] words = msg[i].split("\s");
for(String word:words){
if(!word.trim().equals(""))
addTerm(word, i);
}
msg[i] = msg[i].replaceAll(" ", "").trim();
}
document.addAll(Arrays.asList(msg));
}
/**
* 添加一条词条
* @param word
* @param docId
*/
private void addTerm(String word,int docId){
Term term = new Term();
term.setWord(word);
if(set.containsKey(term)){
term = set.get(term);
}
set.put(term.add(docId), term);
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for(Term term:getList()){
sb.append(term.getWord()+"t"+term.getFreq()+"t"+term.getNdoc());
for(Entry<Integer, Integer> entry:term.getMap().entrySet()){
sb.append("t").append(entry.getKey()).append("t").append(entry.getValue());
}
sb.append("rn");
}
return sb.toString();
}
public String indexOfDocument(int index) {
return document.get(index);
}
}
最后
以上就是鳗鱼咖啡豆最近收集整理的关于自然语言处理基于java实现(3) 之 信息检索的全部内容,更多相关自然语言处理基于java实现(3)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复