目录
- 版本
- 阅读说明
- 一、简介
- Prometheus
- Grafana
- 安装规划
- 二、安装Prometheus
- 1 下载安装包
- 2 配置使用Systemd管理Prometheus
- 3 启动Prometheus
- 4 页面大致介绍(可选)
- 5 常用命令(可选)
- 1 删除job数据
- 2 热重载配置规则
- 二、安装Grafana
- 1 添加repo
- 2 安装
- 3 启动
- 三、监控linux服务器
- 1 安装node_exporter
- 1 下载包
- 2 配置使用Systemd管理node_exporter
- 3 启动node_exporter
- 2 修改prometheus配置
- 3 验证是否配置成功
- 4 配置grafana
- 4.1 创建数据源
- 4.2 添加Dashboard
- 四、监控Flink
- 1 安装PushGateway
- 1.1 下载PushGateway
- 1.2 用system管理push_gateway
- 1.3 启动PushGateway
- 2 修改Flink配置
- 3 配置prometheus
- 4 配置Grafana
- 五、配置告警
- 1 创建钉钉机器人
- 2 安装dingtalk
- 2.1 下载
- 2.2 修改dingtalk配置文件
- 2.3 用system管理dingtalk
- 2.4 启动dingtalk
- 3 安装alertmanager
- 3.1 下载alertmanager
- 3.2 修改alertmanger配置文件
- 3.3 用system管理alertmanager
- 3.4 启动alertmanager
- 4 修改prometheus配置文件
- 1 编辑规则文件
- 1 创建cpu告警文件,内容如下
- 2 创建磁盘告警文件,内容如下
- 3 创建内存告警文件,内容如下
- 4 创建flink任务存活个数告警文件
- 5 判断flink某任务是否存活
- 2 编辑配置文件
- 5 验证配置结果
- 5.1 杀死任务
版本
Centos 7.6
Prometheus 2.31.1
Grafana v8.2.4
node_exporter 1.2.2
CDH 6.3.2
Apache Flink 1.12.0
阅读说明
标记有(可选)的部分会说明一些额外的知识,如果跳过也不影响正常流程。
一、简介
当前有一个flink任务监控告警的需求,经过对Zabbix与Prometheus+Grafana两种方案的优劣势对比,在监控flink的表现上Prometheus+Grafana更为优秀,所以最终选择了使用Prometheus+Grafana。
Prometheus
Prometheus是一套开源的系统监控报警框架。它受启发于Google的Brogmon监控系统,由工作在SoundCloud的前google员工在2012年创建,作为社区开源项目进行开发,并于 2015年正式发布。
2016年,Prometheus正式加入Cloud Native Computing Foundation(CNCF)基金会的项目,成为受欢迎度仅次于Kubernetes 的项目。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。和展示工具Grafana有很好的集成性。
项目地址:https://github.com/prometheus/prometheus
截止到2022-02-18为止
- watch 1.1k
- star 41.1k
- fork 6.8k
架构图,排查未发送告警等问题的时候,一定要先仔细看看这张图
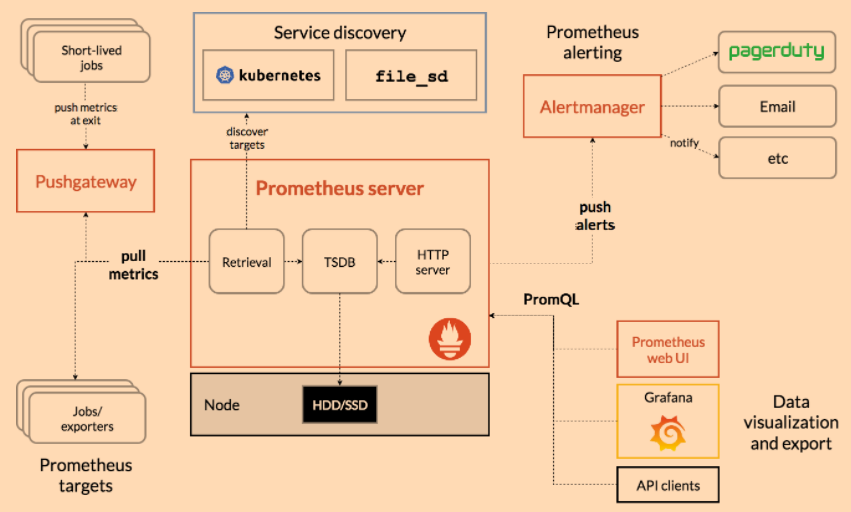
Grafana
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。
项目地址:https://github.com/grafana/grafana
截止到2022-02-18为止
- watch 1.2k
- star 47.1k
- fork 9.3k
安装规划
有3台节点node01、node02、node03
| 服务 | node01 | node02 | node03 |
|---|---|---|---|
| prometheus | 1 | 0 | 0 |
| grafana | 1 | 0 | 0 |
| node_exporter | 1 | 1 | 1 |
| pushgateway | 1 | 0 | 0 |
| alertmanager | 1 | 0 | 0 |
| prometheus-webhook-dingtalk | 1 | 0 | 0 |
二、安装Prometheus
在node01安装
1 下载安装包
# 1 进入安装目录
cd /opt/soft
# 2 下载安装包
wget https://github.com/prometheus/prometheus/releases/download/v2.31.1/prometheus-2.31.1.linux-amd64.tar.gz
# 3 解压
tar -zxvf prometheus-2.31.1.linux-amd64.tar.gz
# 4 创建链接,方便统一管理目录
ln -sv /opt/soft/prometheus-2.31.1.linux-amd64 /usr/local/prometheus
2 配置使用Systemd管理Prometheus
# 编辑脚本
vim /etc/systemd/system/prometheus.service
# 粘贴如下内容(内容可酌情自行修改)
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/usr/local/prometheus/data --web.listen-address=:9290 --web.enable-lifecycle
ExecStop=/usr/bin/pkill -f prometheus
[Install]
WantedBy=multi-user.target
# 保存退出
:wq
prometheus启动命令详细参数可以通过prometheus -h查看
因为默认端口号9090已被占用,通过启动时指定--web.listen-address=:9290修改端口号为9290
3 启动Prometheus
# 重载systemd 配置,修改完systemd配置文件后需重载才会生效。
systemctl daemon-reload
# 设置服务开机启动
systemctl enable prometheus
# 启动服务
systemctl start prometheus
# 查看服务状态
systemctl status prometheus
此时就可以访问ui了,地址:http://ip:9290/
页面长这样,可以访问代表启动成功
4 页面大致介绍(可选)
- Alerts界面。展示告警的信息,每个告警有3种状态:
Inactive(正常状态,未满足告警条件)
Pending(待办状态,已满足告警条件,未满足持续时间,未发送告警信息)
Firing(已产生告警,已经满足告警条件和时间,已发送告警信息) - Graph
使用Promql语言查询prometheus里保存的指标(metric),结果查看形式可以是表格,也可以是图 - Status
- TSDB Status 时序数据库的状态
- Configuration 配置信息
- Rules 告警规则详细信息
- Targets 所有prometheus采集的指标
- Help
- Classic UI
其他未提到的请自行研究。
5 常用命令(可选)
1 删除job数据
如果一个job已经不再使用,想要删除对应数据,就要用到删除命令了
注意:使用删除命令前必须开启管理员命令,删除数据无法恢复
删除名为node_exporter_local的job
curl -X POST -g 'http://host:9290/api/v1/admin/tsdb/delete_series?match[]={__name__=~".+"}&match[]={job="jobname"}'
- host 为prometheus的ip或者hostname
- jobname 要删除的job的名字
2 热重载配置规则
curl -XPOST http://host:9290/-/reload
- host 为prometheus的ip或者hostname
二、安装Grafana
建议Grafana安装在Prometheus所在节点
1 添加repo
vim /etc/yum.repos.d/grafana.repo
# 粘贴如下内容
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
2 安装
yum install grafana -y
3 启动
# 设置grafana开机启动
systemctl enable grafana-server
# 启动grafana服务
systemctl start grafana-server
访问grafana页面: http://ip:3000 用户名密码 admin admin
访问地址看到如下界面,说明启动成功
三、监控linux服务器
监控linux服务器的cpu、内存、磁盘等信息。
流程:
- node_exporter采集指标
- prometheus从exporter拉取指标保存起来
- grafana从prometheus查询数据,可视化展示
1 安装node_exporter
node_exporter的作用是报告单个节点的服务器指标给prometheus,例如内存、磁盘、cpu。
所有需要监控的节点都需要按照如下流程安装node_exporter。
1 下载包
# 1 进入安装目录
cd /opt/soft/
# 2 下载安装包
wget https://github.com/prometheus/node_exporter/releases/download/v1.2.2/node_exporter-1.2.2.linux-amd64.tar.gz
# 3 解压
tar -zxvf node_exporter-1.2.2.linux-amd64.tar.gz
# 4 创建链接,方便统一管理目录
ln -sv /opt/soft/node_exporter-1.2.2.linux-amd64 /usr/local/node_exporter
2 配置使用Systemd管理node_exporter
# 编辑脚本
vim /etc/systemd/system/node_exporter.service
# 粘贴如下内容(内容可酌情自行修改)
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/node_exporter/node_exporter --web.listen-address=:9120
ExecStop=/usr/bin/pkill -f node_exporter
[Install]
WantedBy=multi-user.target
# 保存退出
:wq
因为默认端口号9100已被占用,通过启动时指定参数修改端口号为9120
–web.listen-address=:9120
3 启动node_exporter
# 重载systemd 配置,修改完systemd配置文件后需重载才会生效。
systemctl daemon-reload
# 设置服务开机启动
systemctl enable node_exporter
# 启动服务
systemctl start node_exporter
# 查看服务状态
systemctl status node_exporter
每个node_exporter都会启动一个简易页面:http://ip:9120/,如果可以访问代表启动成功
2 修改prometheus配置
默认配置
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
修改配置文件
注意:yml文件的缩进不能乱,乱了就识别不了
# 进入prometheus安装目录
cd /usr/local/prometheus
# 编辑配置文件
vim prometheus.yml
# 在文件最后粘贴如下内容
- job_name: 'all_node'
static_configs:
- targets: ['node01:9120']
labels:
nodename: node01
- targets: ['node02:9120']
labels:
nodename: node02
- targets: ['node03:9120']
labels:
nodename: node03
- targets: ['node01:9120']这里的node01是1台启动了node_exporter的服务器的hostname,这里也可以换成ip。9120则是node_exporter启动端口。其余2台服务器配置以此类推。
这里的配置是告诉prometheus从哪个服务器的哪个端口拉取数据。
修改后的配置文件如下所示
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: 'all_node'
static_configs:
- targets: ['node01:9120']
labels:
nodename: node01
- targets: ['node02:9120']
labels:
nodename: node02
- targets: ['node03:9120']
labels:
nodename: node03
修改完配置后,重启prometheus服务配置才生效
systemctl stop prometheus
systemctl start prometheus
3 验证是否配置成功
此时打开prometheus的地址 http://ip:9290/
操作步骤: 点击Status —> 点击Targets
这里图片是后截的,这里all_node(N/N up)的根据上面的配置来的。如果配置了3台,那么应该像这样all_node(3/3 up)
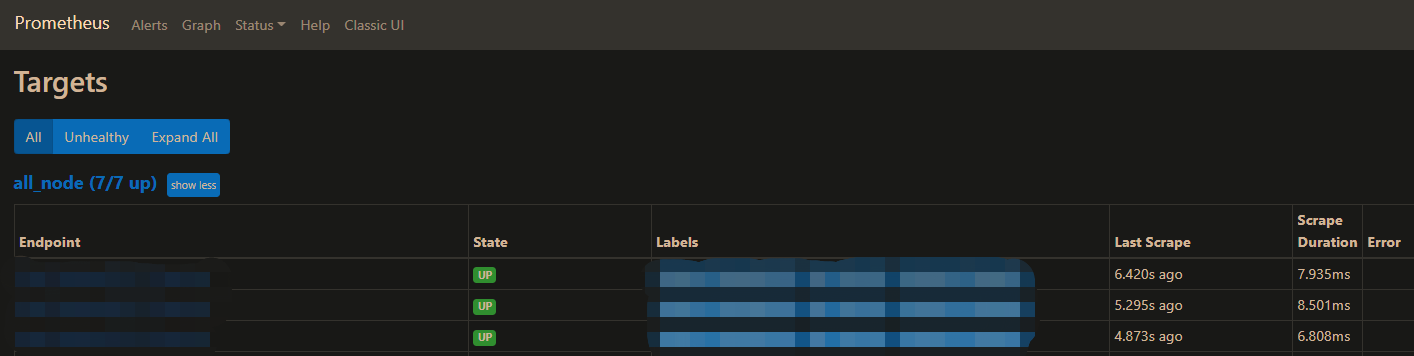
上面配置文件里配置了几台,这里看到几台就是配置正确了。如果不对,可以排查一下hostname或者端口是否有误,或者node_exporter是否启动成功。
4 配置grafana
4.1 创建数据源
1 浏览器打开grafana地址 http://ip:3000 用户名密码 admin admin
登录后,进入主界面
2 点击左侧齿轮(设置按钮) —> 点击Data sources
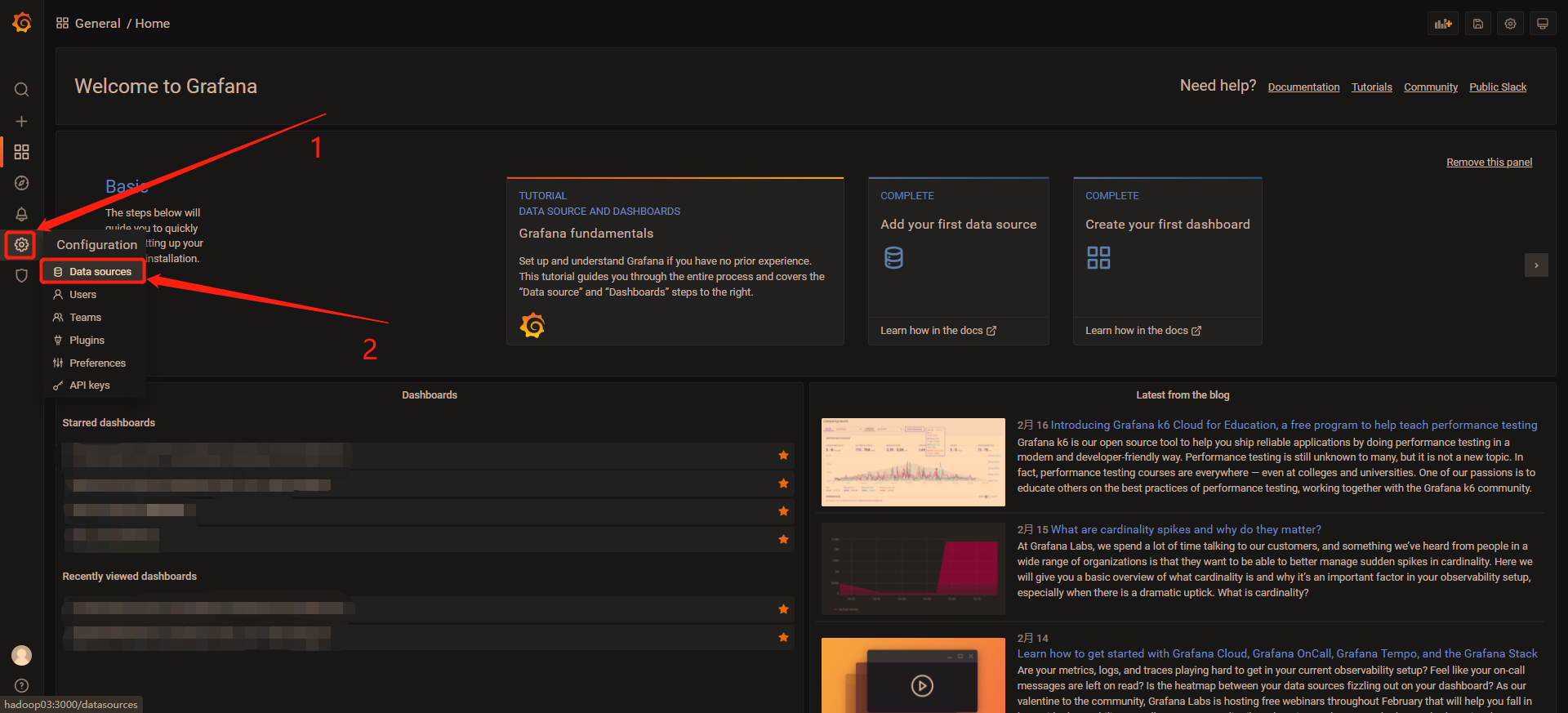
3 点击Add data source
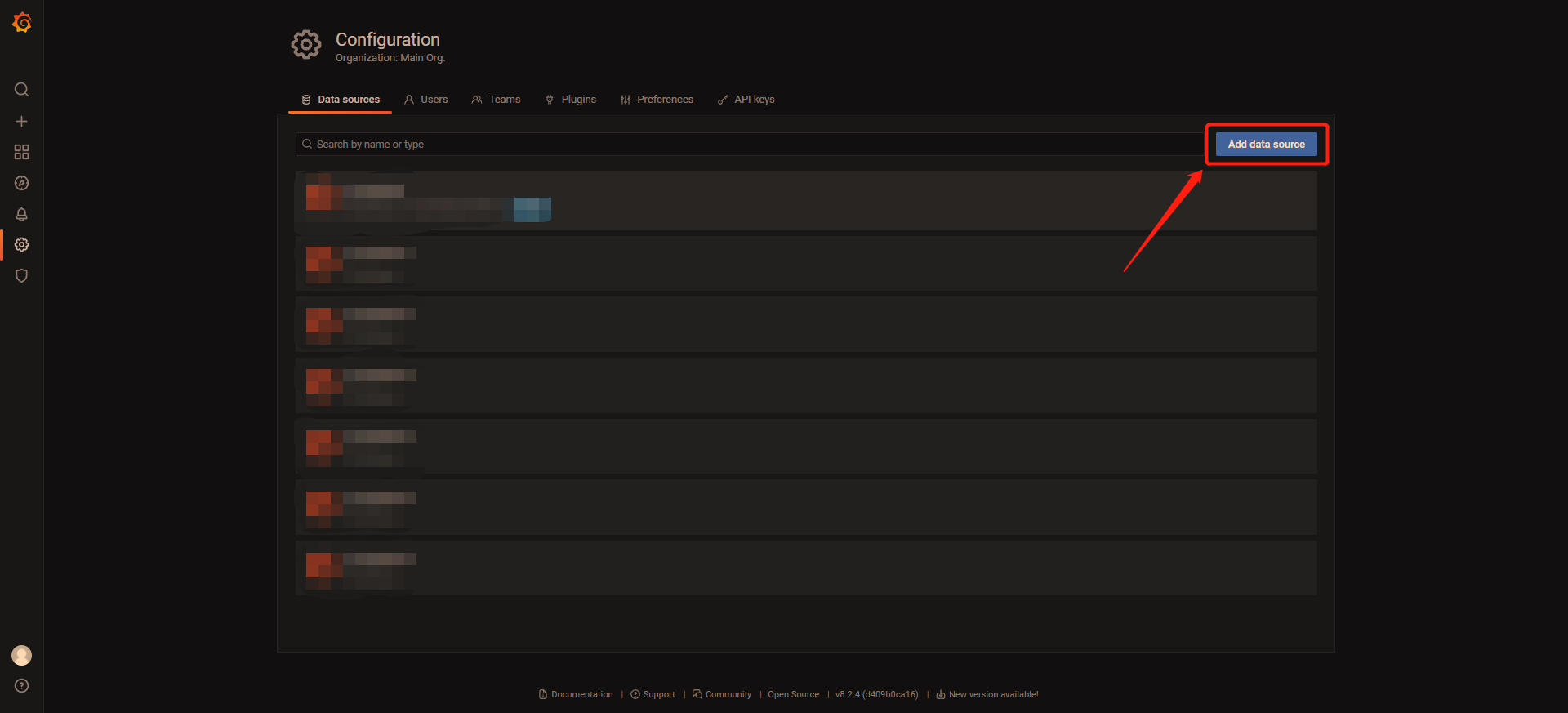
4 点击Select,在搜索框输入prometheus,点击Select
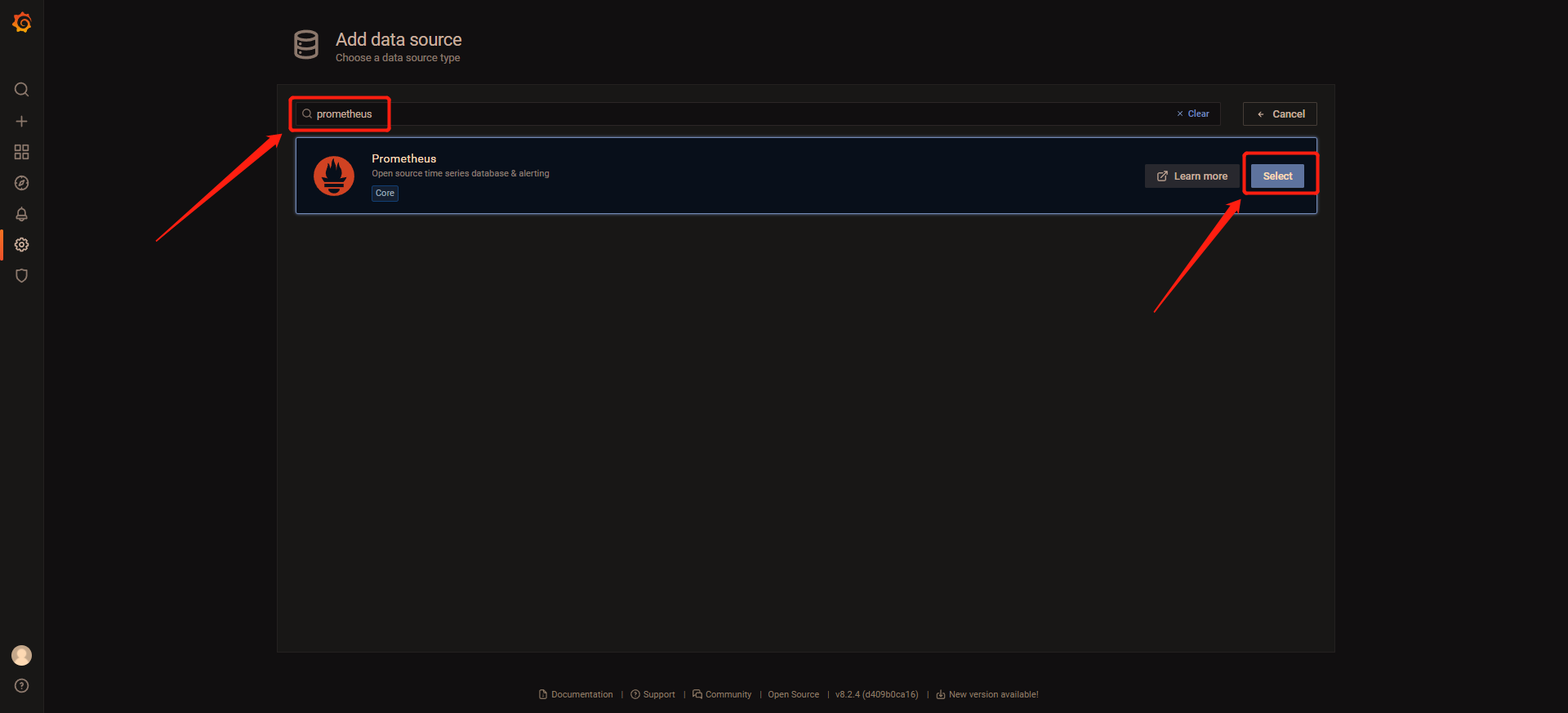
5 输入数据源名字(名字默认即可),输入prometheus的地址 http://localhost:9290/。这里我的prometheus和grafana部署在同一台上所以host为localhost,如果不在一台机器上请自行更改。
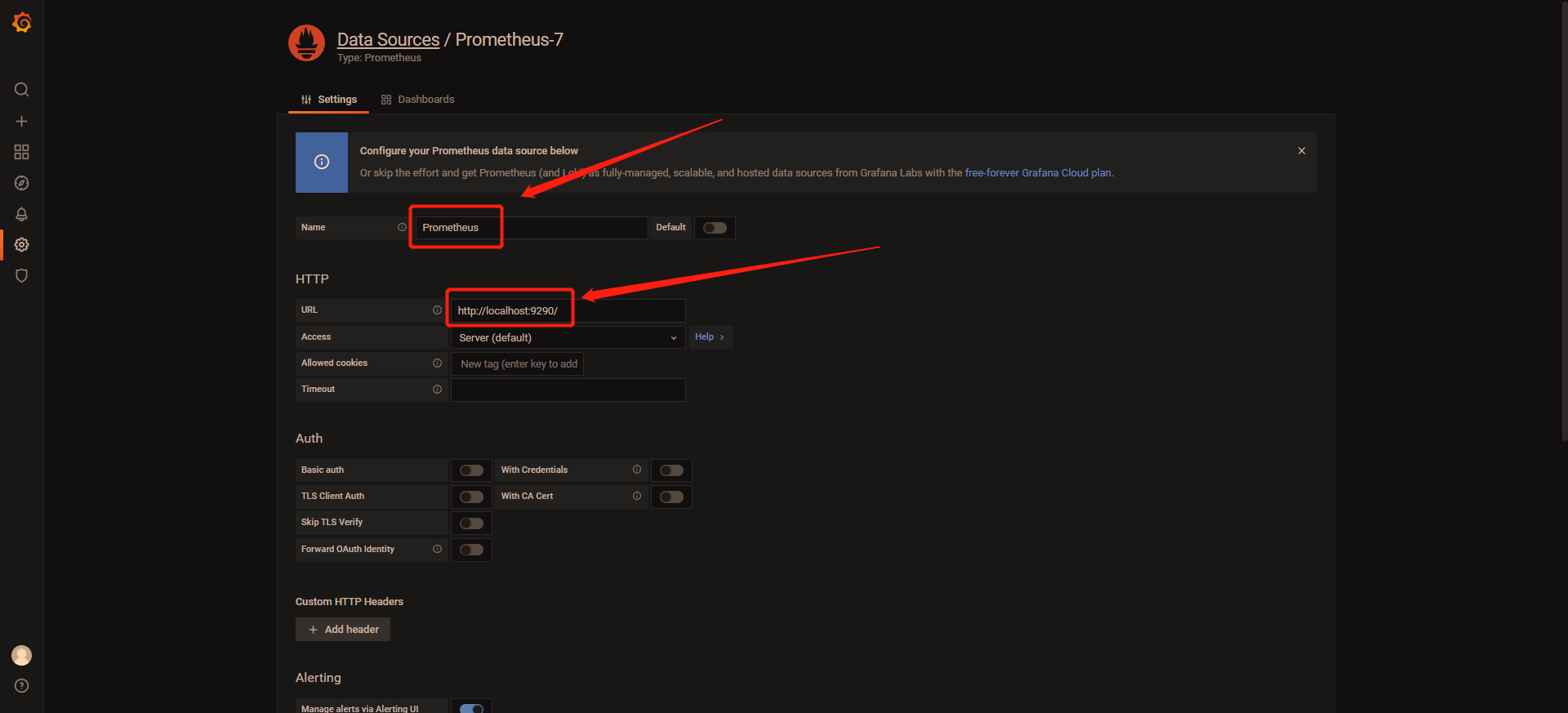
6 点击Save & test。
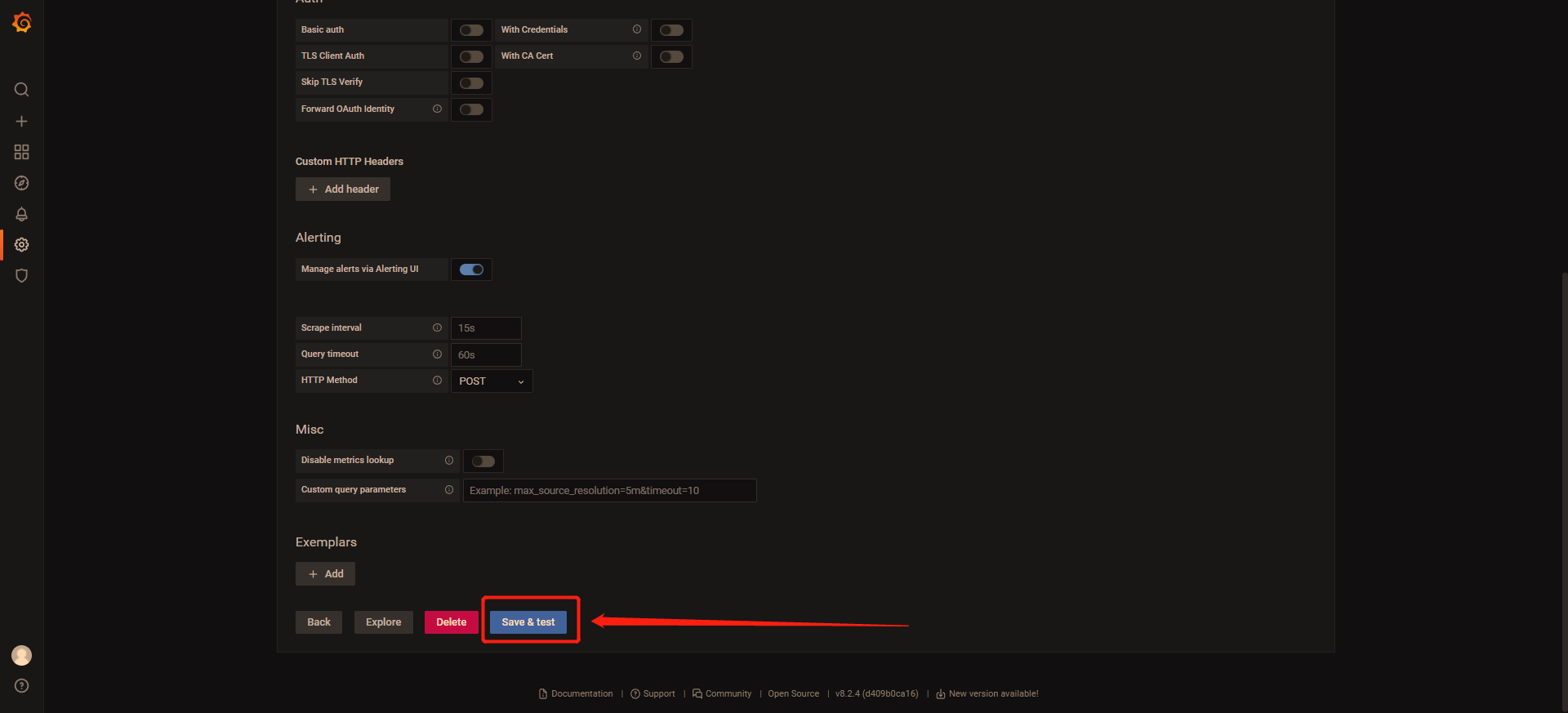
这样一个prometheus数据源就创建好了。
7 点击左上角图标回到主界面
4.2 添加Dashboard
1 点击 + ,点击Import

2 输入8919,点击Load
这个8919是一个其他人发布的一个Dashboard。这个id是我从Grafana官方提供的Dashboard网站 https://grafana.com/grafana/dashboards/ 里找到的。以后要添加其他类型的比如flink或者mysql监控报表,都可以从这个网站找到。
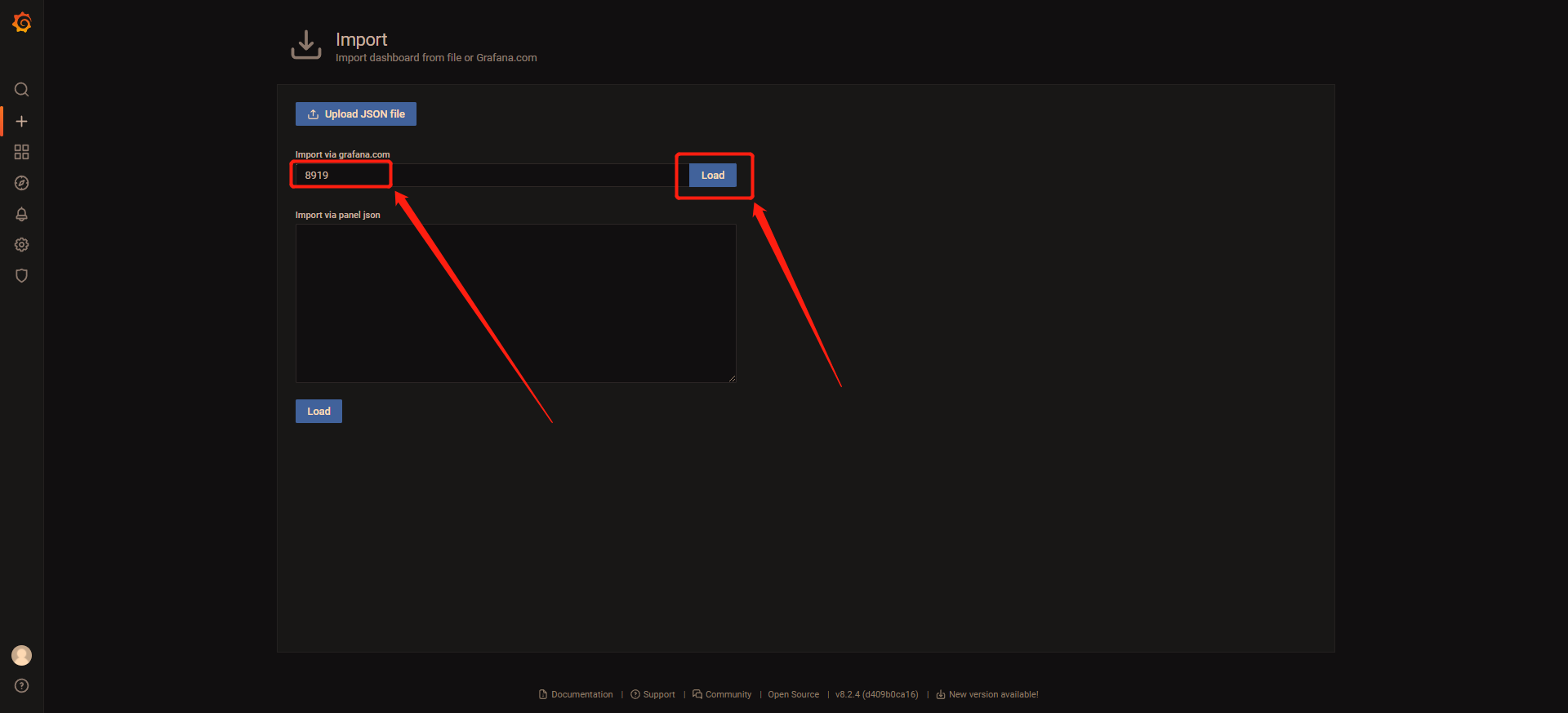
3 输入名字,选择数据源,点击Import
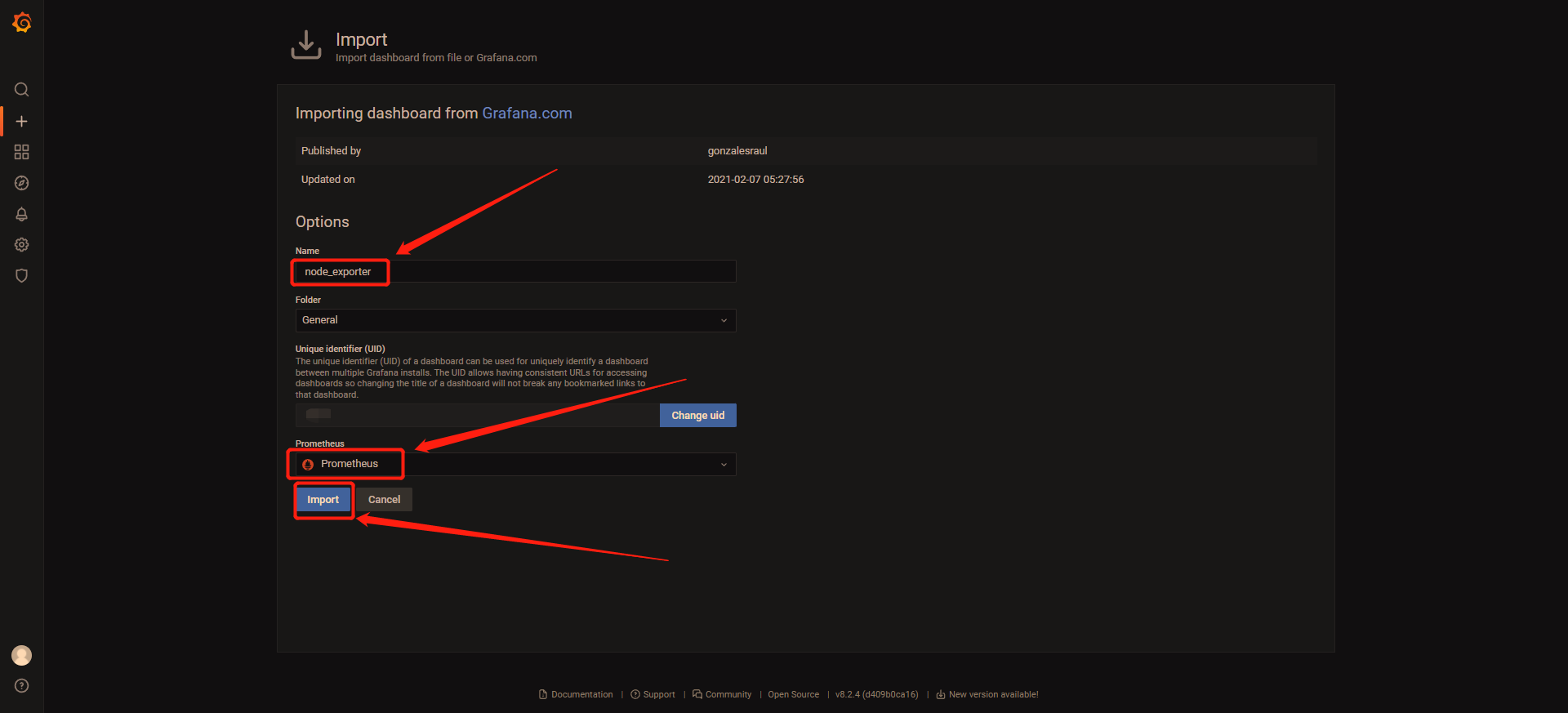
看到如下的Dashboard,就说明配置成功了
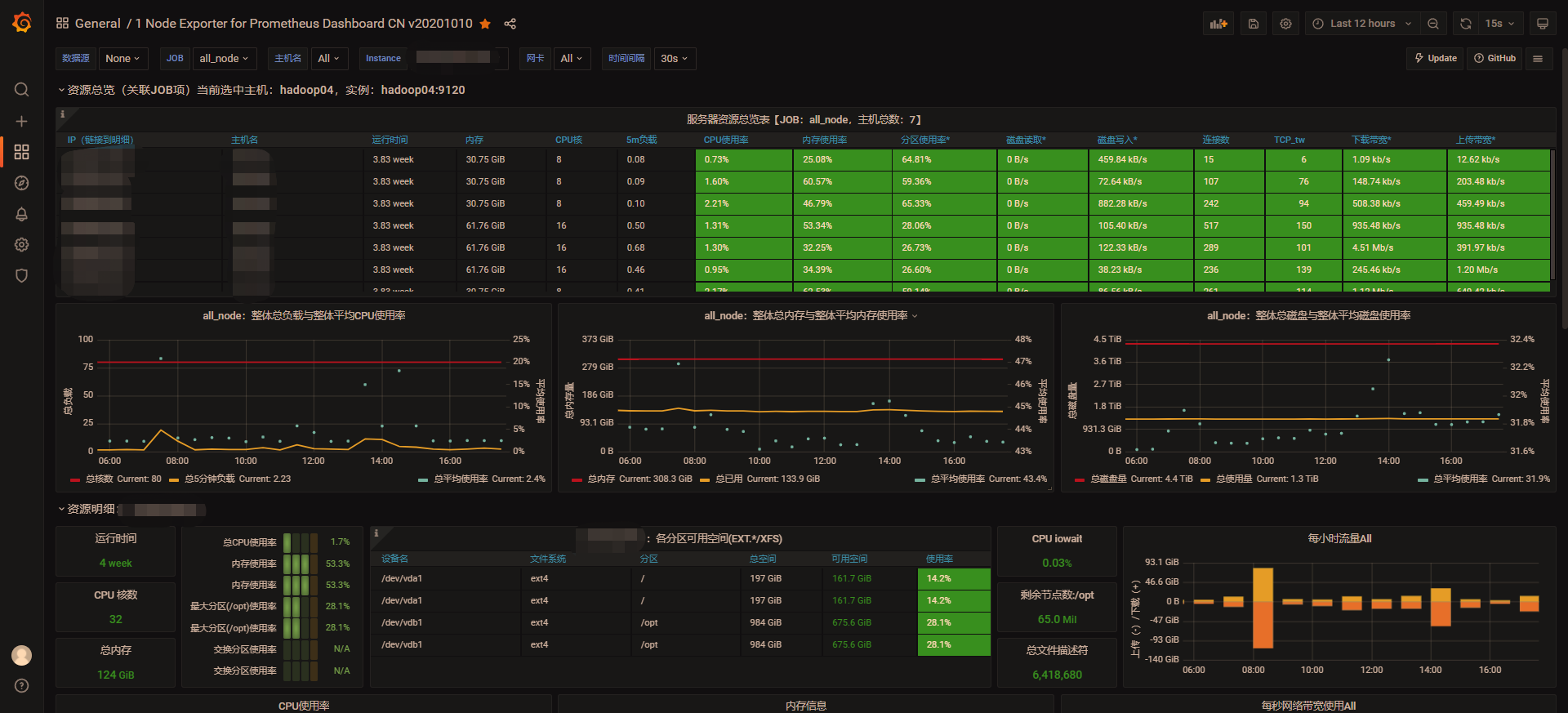
四、监控Flink
flink默认提供了报道数据的实现类将指标上报给PushGateway;Prometheus再从PushGateway拉取指标,保存起来;Grafana从Prometheus查询数据展示出来。
注意:如果是CDH集成的Flink-yarn服务,那么任务必须提交到Flink-yarn服务启动时随之启动的session中,否则无法监控到任务运行指标
1 安装PushGateway
建议PushGateway安装到Prometheus所在节点
1.1 下载PushGateway
# 进入安装目录
cd /opt/soft/
# 下载安装包
wget -c https://github.com/prometheus/pushgateway/releases/download/v1.4.2/pushgateway-1.4.2.linux-amd64.tar.gz
# 解压
tar -zxvf /pushgateway-1.4.2.linux-amd64.tar.gz
# 创建软连接,方便管理
ln -sv /opt/soft/pushgateway-1.4.2.linux-amd64 /usr/local/pushgateway
1.2 用system管理push_gateway
vim /etc/systemd/system/pushgateway.service
# 粘贴如下内容
[Unit]
Description=pushgateway
After=network.target
[Service]
Type=simple
ExecStart=/opt/soft/pushgateway-1.4.2.linux-amd64/pushgateway --web.listen-address=:9291
ExecStop=/usr/bin/pkill -f pushgateway
[Install]
WantedBy=multi-user.target
# 保存退出
:wq
–web.listen-address=:9291 默认端口为9091,避免冲突改为9291
1.3 启动PushGateway
# 重载systemd 配置,修改完systemd配置文件后需重载才会生效。
systemctl daemon-reload
# 设置服务开机启动
systemctl enable pushgateway
# 启动服务
systemctl start pushgateway
# 查看服务状态
systemctl status pushgateway
2 修改Flink配置
开源版本
在flink.conf中添加如下内容
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: 192.168.66.66
metrics.reporter.promgateway.port: 9291
metrics.reporter.promgateway.jobName: flink_pushgateway
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.interval: 10 SECONDS
配置项解释
- metrics.reporter.promgateway.host 启动pushgateway的ip或者hostname
- metrics.reporter.promgateway.port 启动pushgateway的端口
- metrics.reporter.promgateway.jobName 上传到prometheus的任务名称
- metrics.reporter.promgateway.randomJobNameSuffix 是否给任务名称添加随机后缀,这里建议添加,不添加会任务名重复从而导致指标被覆盖。
- metrics.reporter.promgateway.deleteOnShutdown 挂掉时是否删除指标数据
- metrics.reporter.promgateway.interval 上报间隔
CDH版本
1 点击Flink-yarn
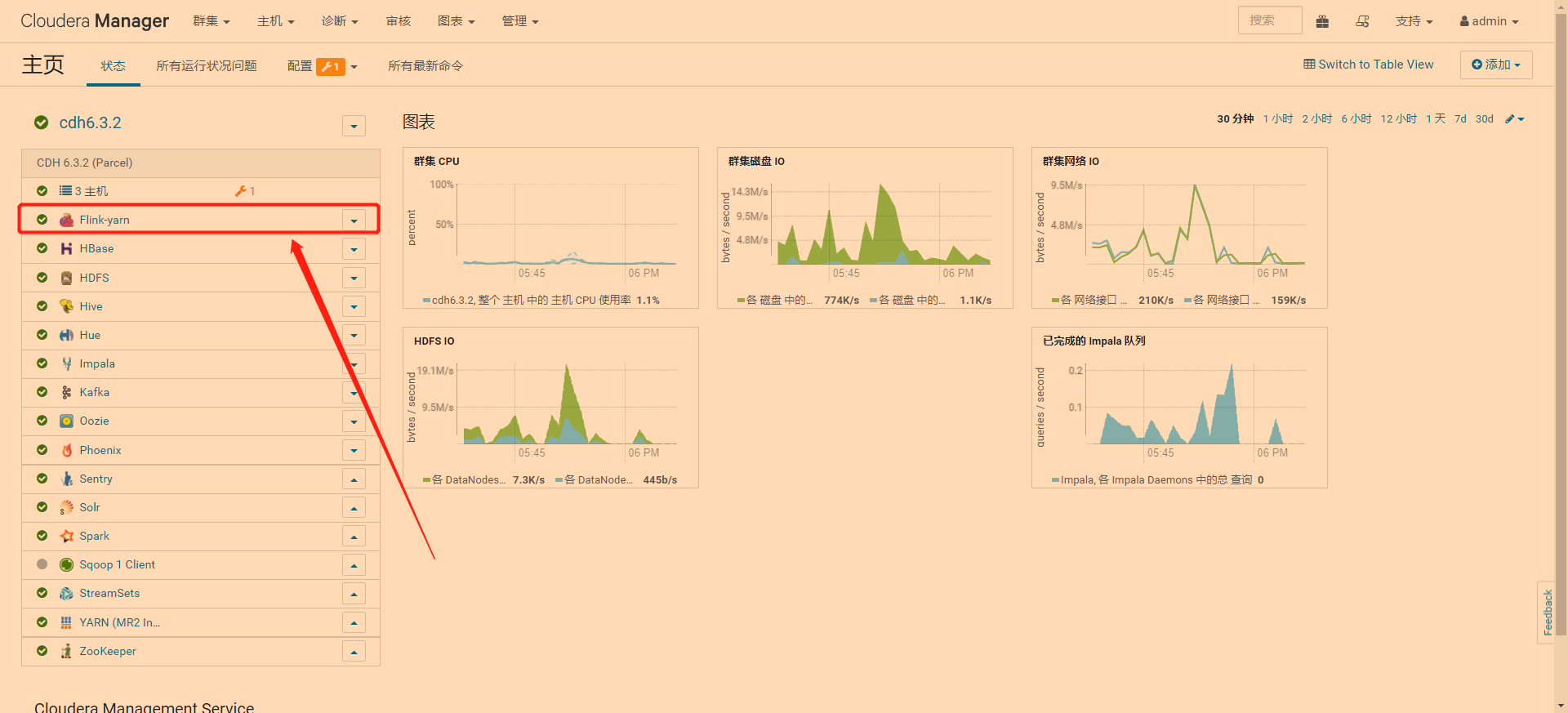
2 点击配置
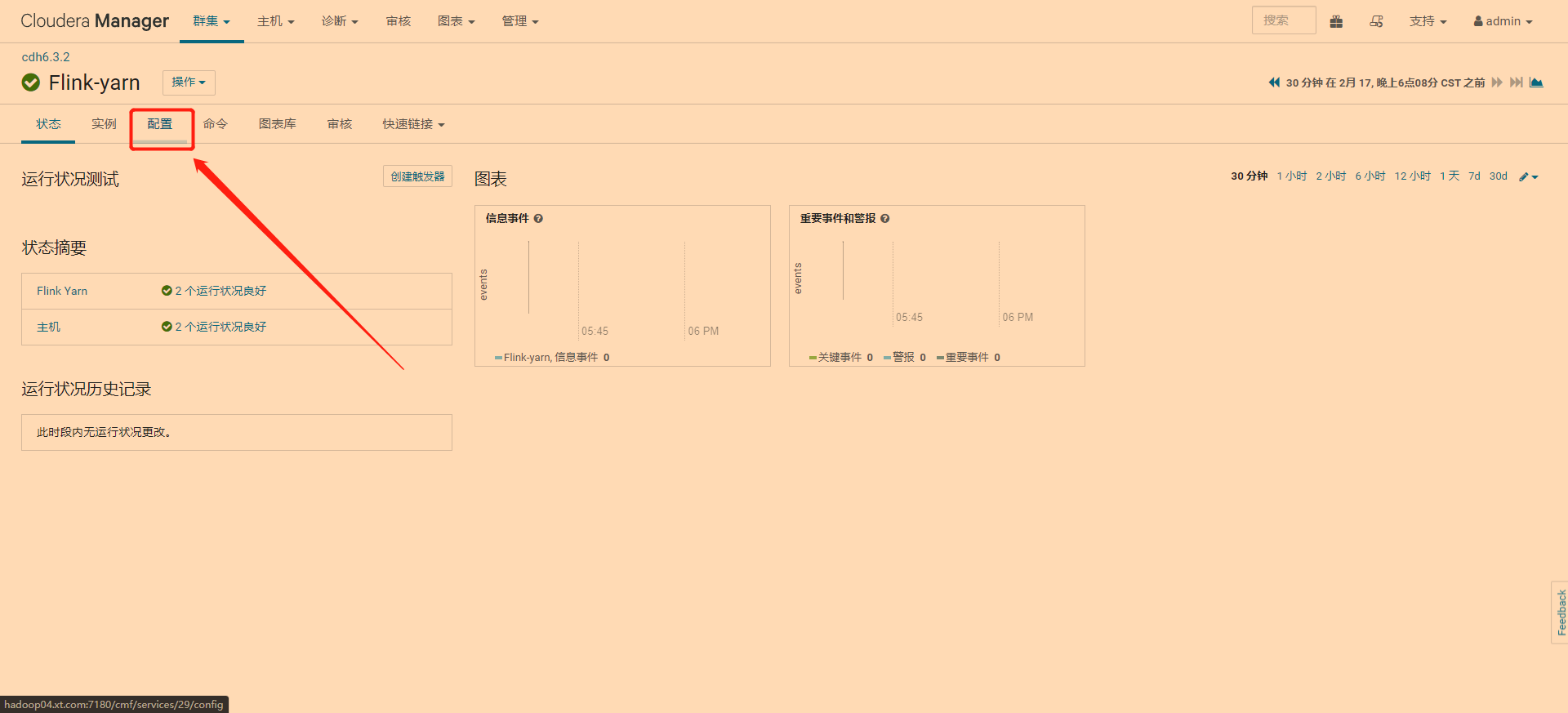
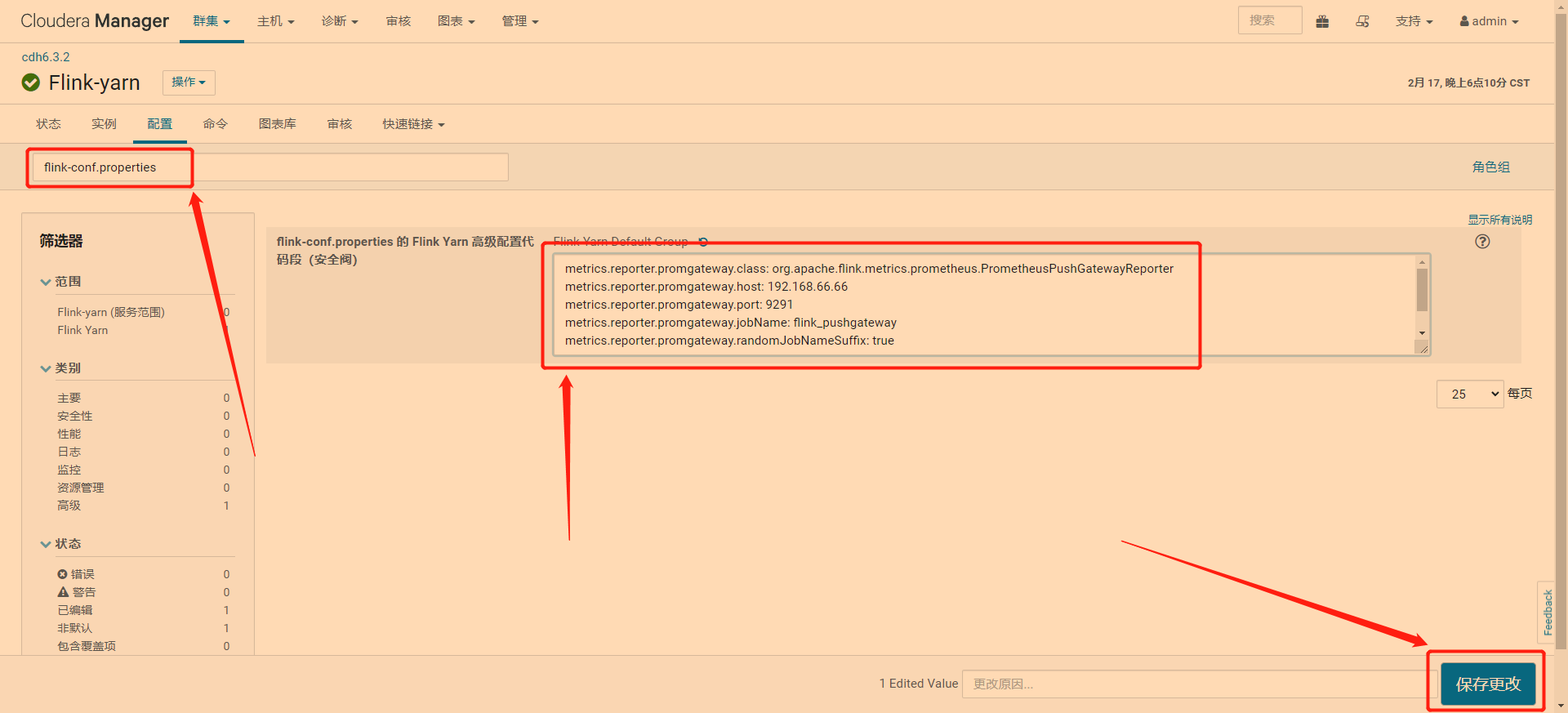
3 在搜索框输入flink-conf.properties,在文本框输入,点击保存更改
文本框内容
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: 192.168.66.66
metrics.reporter.promgateway.port: 9291
metrics.reporter.promgateway.jobName: flink_pushgateway
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.interval: 10 SECONDS
4 重启Flink-yarn服务
5 验证是否配置成功
打开prometheus地址 http://ip:9290/targets,可以看到如下内容即是成功

3 配置prometheus
vim /usr/local/prometheus/prometheus.yml
# 在文件最后追加如下内容
- job_name: 'pushgateway'
honor_labels: true
static_configs:
- targets: ['node01:9291']
labels:
instance: 'pushgateway'
注意:yml文件的缩进不能乱,乱了就识别不了
4 配置Grafana
1 点击 + ,点击Import
2 输入14911,点击Load
这个14911是一个其他人发布的一个Dashboard。这个id是我从Grafana官方提供的Dashboard网站 https://grafana.com/grafana/dashboards/ 里找到的。以后要添加其他类型的比如flink或者mysql监控报表,都可以从这个网站找到。
这里偷个懒,就没重新截图,你们应该懂的????
3 输入名字,选择上面创建的Prometheus数据源,点击Import
如果成功就可以看到如下界面,默认都是折叠的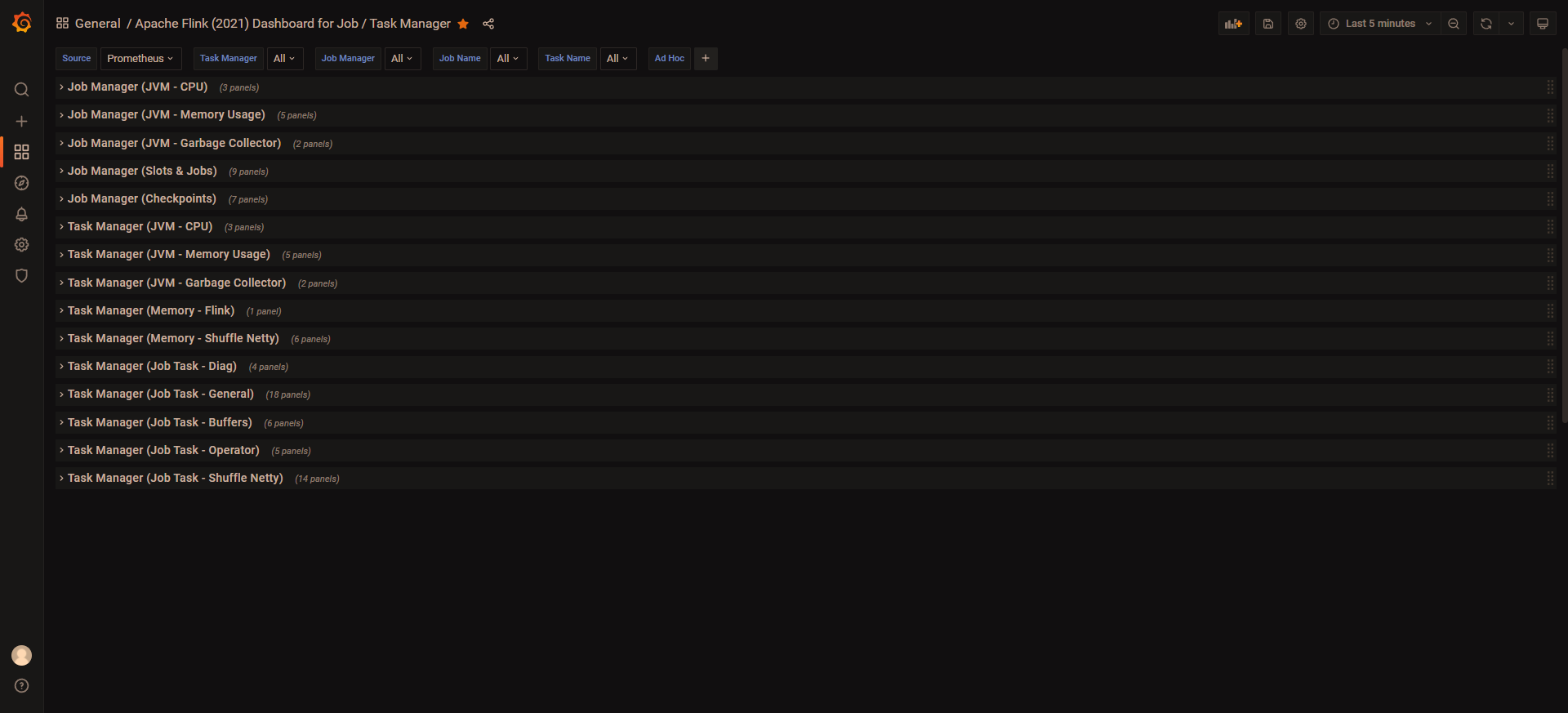
展开大概是这样
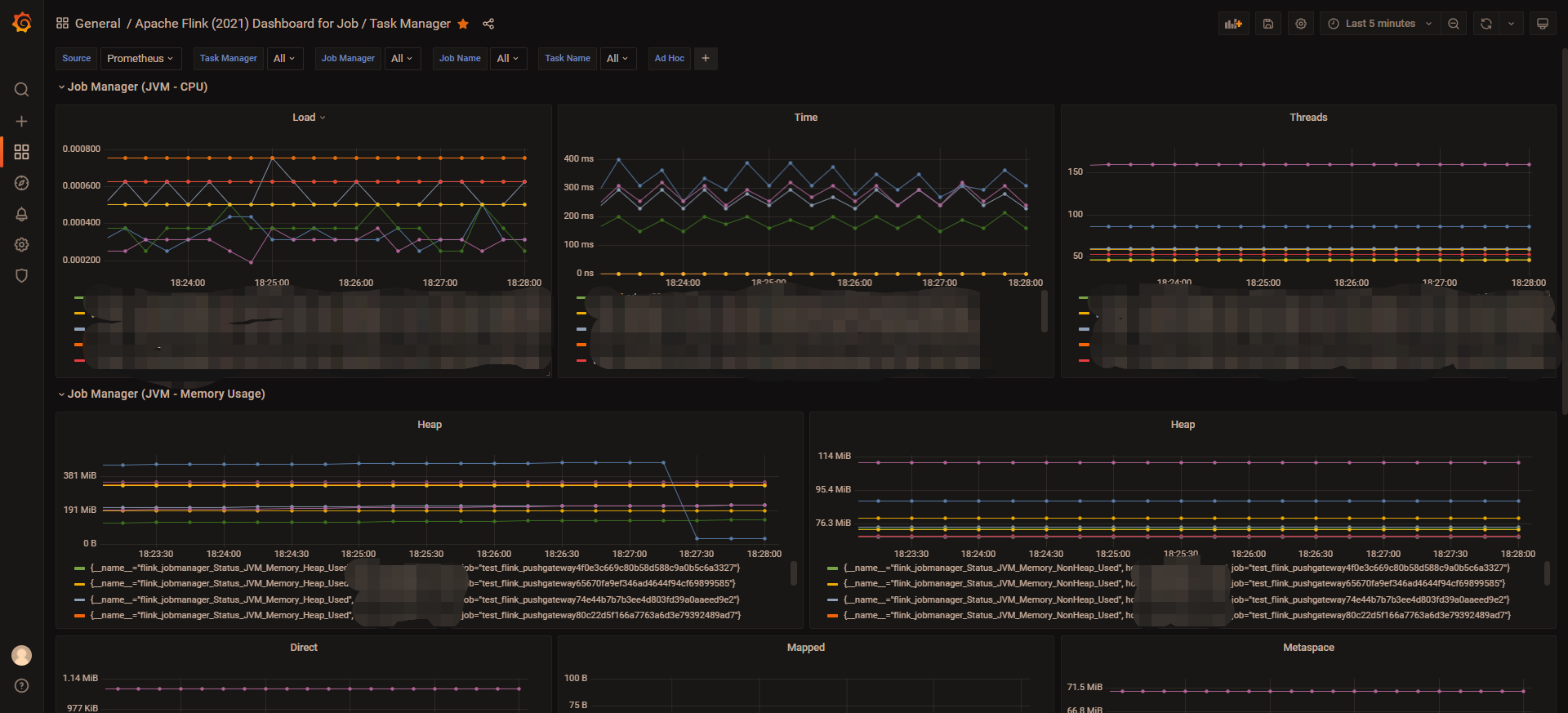
五、配置告警
告警流程
- exporter采集指标数据
- prometheus从exporter拉取指标数据保存起来
- prometheus向alertmanager推送触发了的告警
- alertmanager通过email、dingding等方式发送告警信息
1 创建钉钉机器人
1 找一个群打开对话框,点击右上角齿轮
2 点击智能群助手
3 点击 +
4 点击+
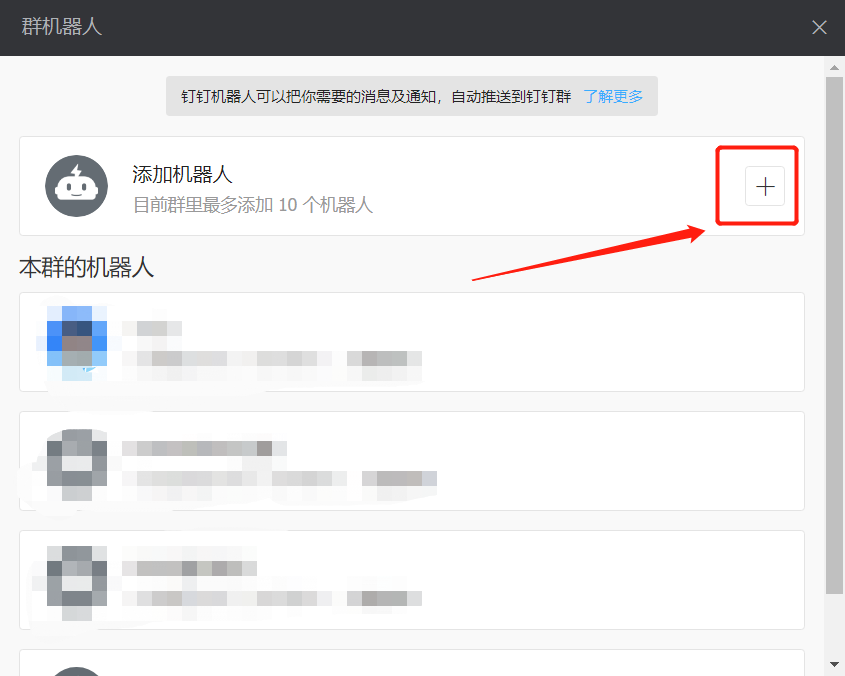
5 往下滑滑轮,点击自定义
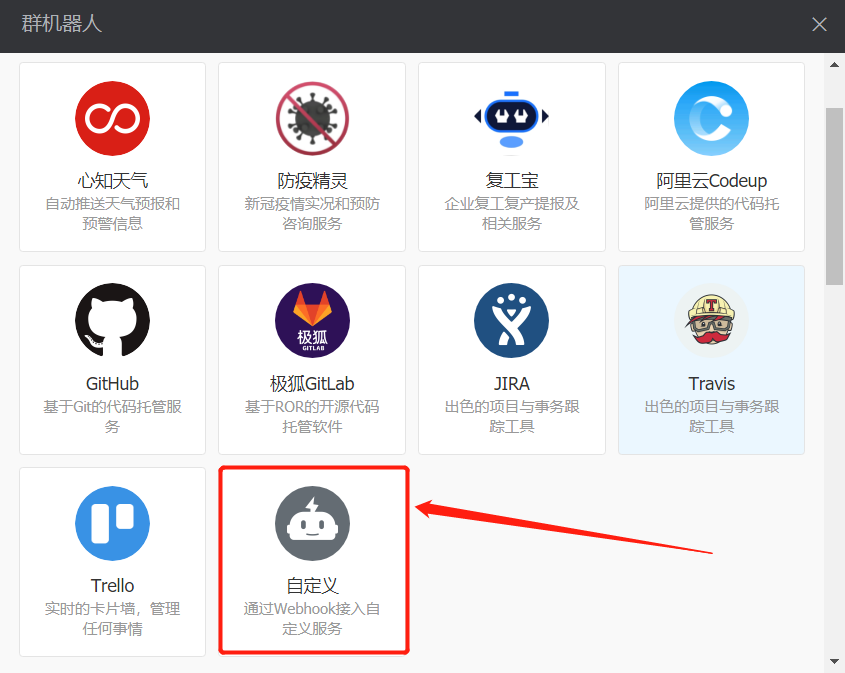
6 点击添加
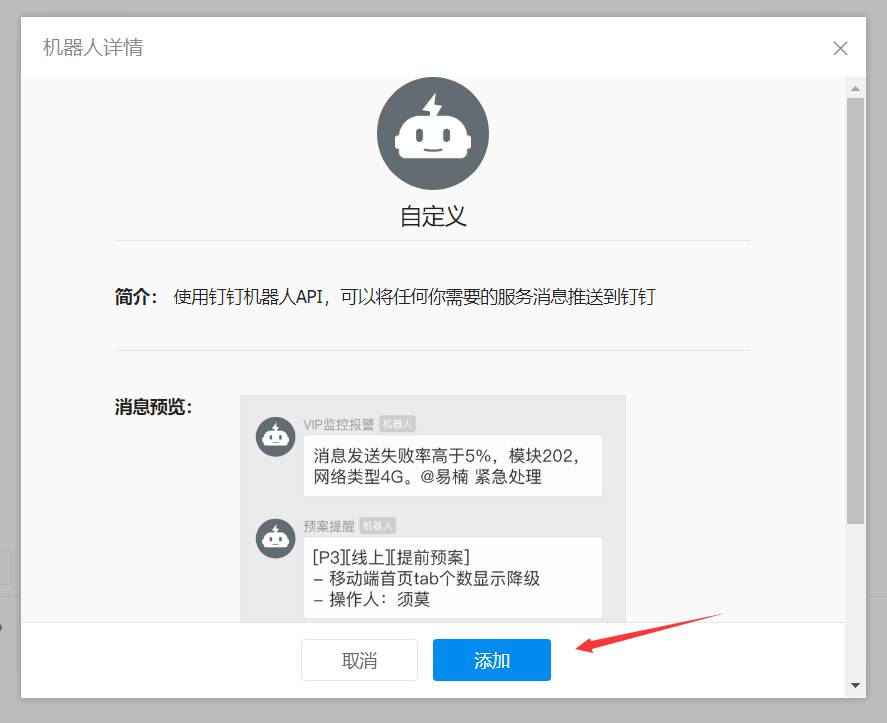
7 填入机器人名字,选择加签,点击我已阅读并同意,点击完成
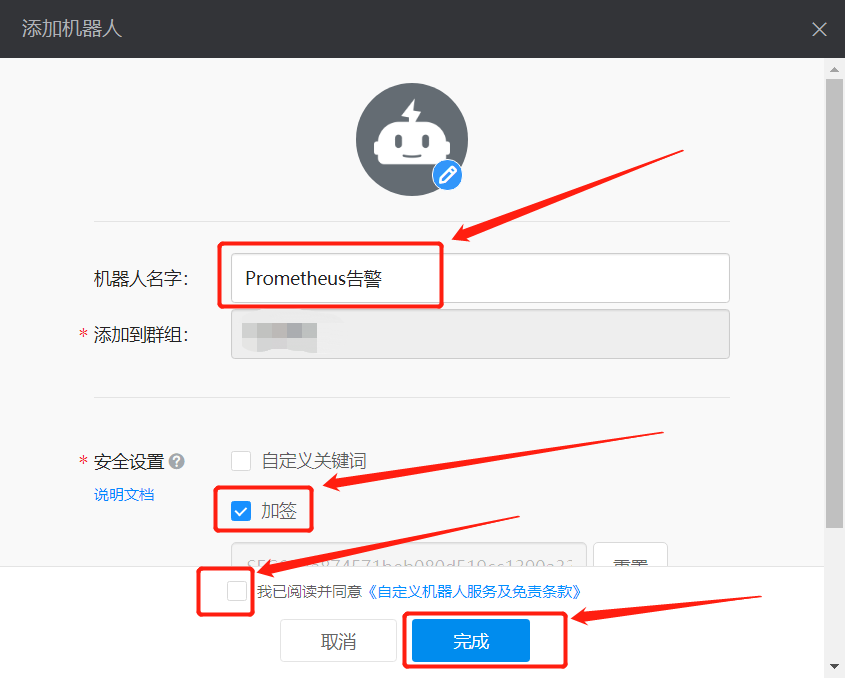
这样一个机器人就添加完成了
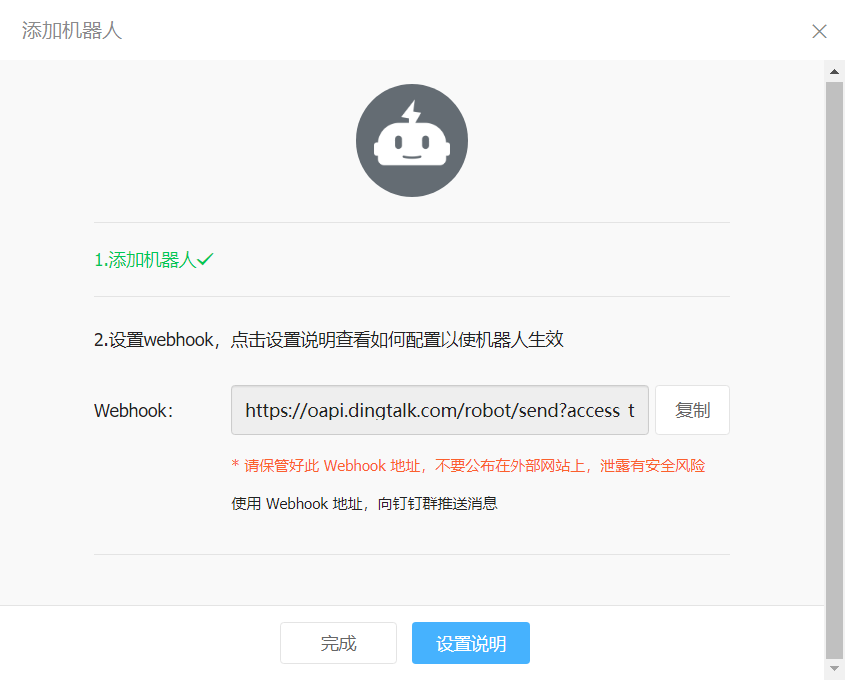
这里建议点击复制,把Webhook的url保存一下,后面会用到
2 安装dingtalk
dingtalk是一个用来发送钉钉告警通知的prometheus插件
2.1 下载
cd /opt/soft
# 下载安装包
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.0.0/prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz
# 解压
tar -zxvf prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz
# 创建软连接
ln -sv /opt/soft/prometheus-webhook-dingtalk-2.0.0.linux-amd64/ /usr/local/prometheus-webhook-dingtalk
2.2 修改dingtalk配置文件
# 拷贝一份新配置文件,命名为config.yml
cp config.example.yml config.yml
# 编辑配置文件
vim config.yml
# 把配置里所有的url改为上一步保存的Webhook的url
# 假设我的Webhook的url=https://oapi.dingtalk.com/robot/send?access_token=abc,那么配置就像这样
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=abc
# 修改签名秘钥为配置机器人时生成的秘钥
secret: SEC000000000000000000000
webhook2:
url: https://oapi.dingtalk.com/robot/send?access_token=abc
webhook_legacy:
url: https://oapi.dingtalk.com/robot/send?access_token=abc
# Customize template content
message:
# Use legacy template
title: '{{ template "legacy.title" . }}'
text: '{{ template "legacy.content" . }}'
webhook_mention_all:
url: https://oapi.dingtalk.com/robot/send?access_token=abc
mention:
all: true
webhook_mention_users:
url: https://oapi.dingtalk.com/robot/send?access_token=abc
mention:
mobiles: ['156xxxx8827', '189xxxx8325']
2.3 用system管理dingtalk
# 编辑配置
vim /etc/systemd/system/prometheus-webhook-dingtalk.service
# 粘贴如下内容
[Unit]
Description=prometheus-webhook-dingtalk
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/usr/local/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/usr/local/prometheus-webhook-dingtalk/config.yml --web.listen-address=:8260
ExecStop=/usr/bin/pkill -f prometheus-webhook-dingtalk
[Install]
WantedBy=multi-user.target
# 保存退出
:wq
–web.listen-address=:8260 默认端口为8060,避免冲突修改为8260
2.4 启动dingtalk
# 重载systemd 配置,修改完systemd配置文件后需重载才会生效。
systemctl daemon-reload
# 设置服务开机启动
systemctl enable prometheus-webhook-dingtalk
# 启动服务
systemctl start prometheus-webhook-dingtalk
# 查看服务状态
systemctl status prometheus-webhook-dingtalk
# 查看端口
lsof -i :8260
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
prometheu 7893 root 3u IPv6 110639539 0t0 TCP *:8260 (LISTEN)
3 安装alertmanager
建议alertmanager安装到prometheus所在节点
3.1 下载alertmanager
cd /opt/soft
# 下载安装包
wget https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz
# 解压
tar -zxvf alertmanager-0.23.0.linux-amd64.tar.gz
# 创建软连接
ln -sv /opt/soft/alertmanager-0.23.0.linux-amd64/ /usr/local/alertmanager
3.2 修改alertmanger配置文件
# 编辑配置文件
vim /usr/local/alertmanager/alertmanager.yml
# 修改为如下
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- send_resolved: true
url: 'http://node01:8260/dingtalk/webhook1/send'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
#route:
#group_by: ['alertname']
# group_wait: 10s
# group_interval: 10s
# repeat_interval: 1h
# receiver: 'ops_dingding'
#receiver: 'ops_dingding' #默认的接收器
# 发送钉钉告警
#- name: 'ops_dingding'
#webhook_configs:
#- url: 'http://172.16.184.127:8060/dingtalk/webhook1/send'
#send_resolved: true
3.3 用system管理alertmanager
vim /etc/systemd/system/alertmanager.service
# 粘贴如下内容
[Unit]
Description=alertmanager
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager --web.listen-address=:9293 --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/usr/local/alertmanager/data/
ExecStop=/usr/bin/pkill -f alertmanager
[Install]
WantedBy=multi-user.target
# 保存退出
:wq
3.4 启动alertmanager
# 重载systemd 配置,修改完systemd配置文件后需重载才会生效。
systemctl daemon-reload
# 设置服务开机启动
systemctl enable alertmanager
# 启动服务
systemctl start alertmanager
# 查看服务状态
systemctl status alertmanager
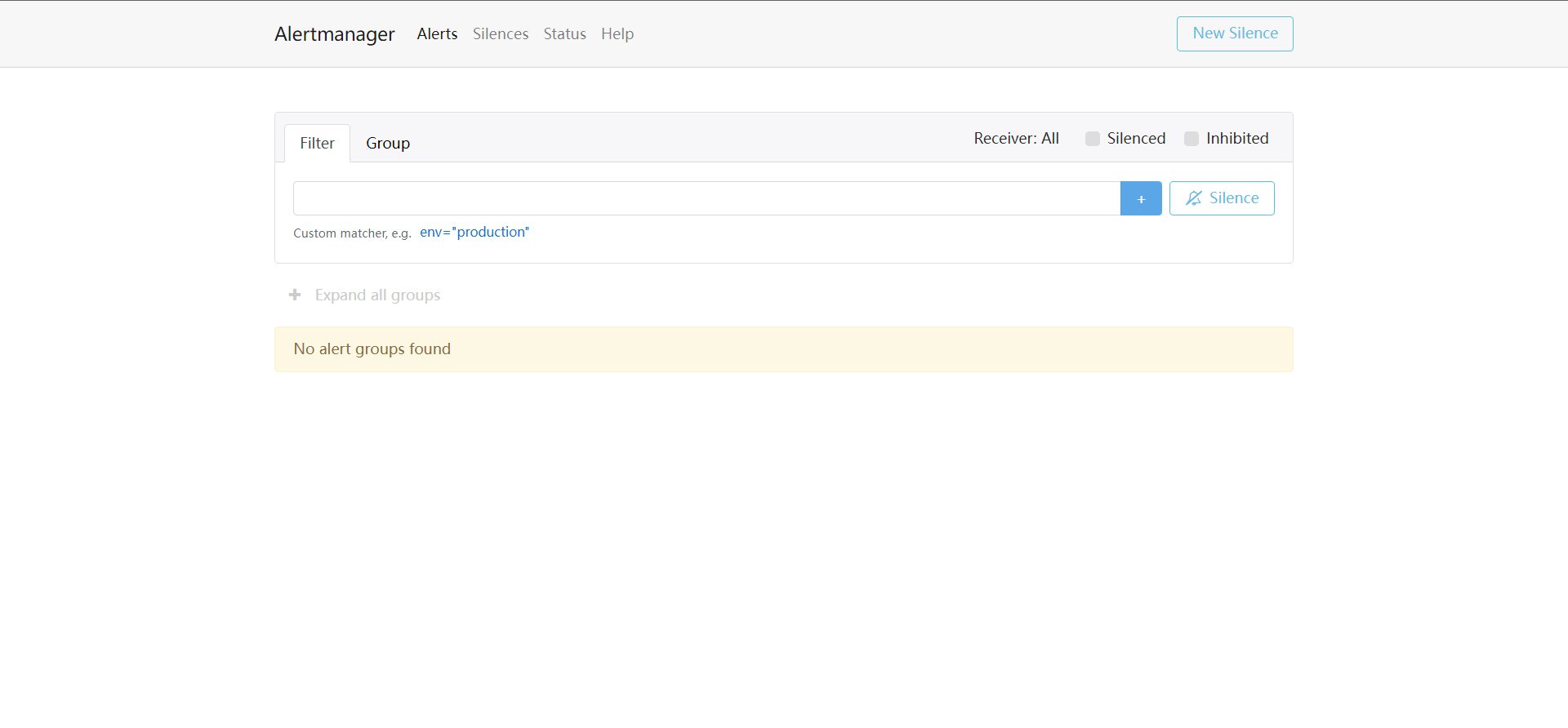
访问alertmanager的地址 http://localhost:9293/ ,如果出现如下界面,说明启动成功,如果不能启动请检查配置
4 修改prometheus配置文件
1 编辑规则文件
# 创建告警规则文件目录
mkdir /usr/local/prometheus/rules
# 进入目录
cd /usr/local/prometheus/rules
1 创建cpu告警文件,内容如下
groups:
- name: CPU报警规则
rules:
- alert: 服务器-CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 85
for: 3m
labels:
severity: warning
annotations:
summary: "CPU使用率正在飙升。"
description: "CPU使用率超过85%(当前值:{{ $value }}%)"
2 创建磁盘告警文件,内容如下
groups:
- name: 磁盘使用率报警规则
rules:
- alert: 服务器-磁盘使用率告警
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 85
for: 30m
labels:
severity: warning
annotations:
summary: "硬盘分区使用率过高"
description: "分区使用大于85%(当前值:{{ $value }}%)"
3 创建内存告警文件,内容如下
groups:
- name: 内存报警规则
rules:
- alert: 服务器-内存使用率告警
expr: (1 - (node_memory_MemAvailable_bytes{job="all_node"} / (node_memory_MemTotal_bytes{job="all_node"}))) * 100 > 85
for: 3m
labels:
severity: warning
annotations:
summary: "服务器可用内存不足。"
description: "内存使用率已超过85%(当前值:{{ $value }}%)"
4 创建flink任务存活个数告警文件
第一个文件
groups:
- name: 生产-实时-flink-任务执行失败
rules:
- alert: 生产-实时-flink-任务失败告警
expr: flink_jobmanager_numRunningJobs{job=~"flink_pushgateway.*"} < 3
for: 1m
labels:
severity: warning
annotations:
summary: "生产-flink 某个任务执行失败"
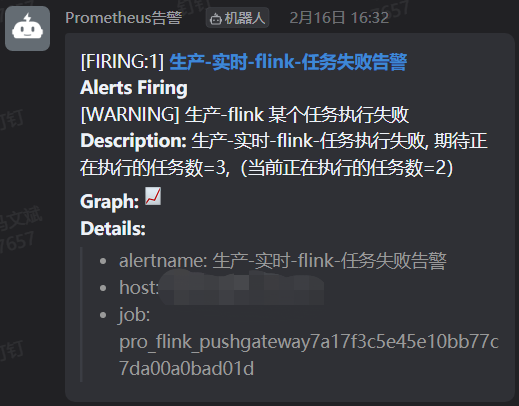
description: "生产-实时-flink-任务执行失败, 期待正在执行的任务数=3,(当前正在执行的任务数={{ $value }})"
- expr: flink_jobmanager_numRunningJobs{job=~“flink_pushgateway.*”} < 3
当前正在运行的任务有3个,判断当前正在运行的任务数量小于3吗,小于3说明有任务挂了 - for: 1m
expr条件触发后,这种情况持续了1分钟,则发出告警
5 判断flink某任务是否存活
groups:
- name: MainClassName 执行失败
rules:
- alert: 生产-实时-flink-任务失败告警
expr: ((flink_jobmanager_job_uptime{ job_name="MainClassName"})-(flink_jobmanager_job_uptime{ job_name="MainClassName"} offset 10s))/1000 == 0
for: 1m
labels:
severity: warning
annotations:
summary: "生产-实时任务执行失败"
description: "MainClassName(xxx任务) 执行失败(当前值:{{ $value }})"
注意:这里只能根据任务启动时的MainClassName主类名监控指定任务
原理是根据一个不断增加的指标uptime来判断
如果任务存活,当前时间戳减去10秒前的时间戳就等于10秒,则表达式 ((flink_jobmanager_job_uptime{ job_name="MainClassName"})-(flink_jobmanager_job_uptime{ job_name="MainClassName"} offset 10s))/1000的值会是一个固定值约等于10秒的一个数
如果任务失败,那么值uptime的值不会在随时间增加而是一个固定值,那么当前时间戳减去10秒前的时间戳就回等于0。则当表达式((flink_jobmanager_job_uptime{ job_name="MainClassName"})-(flink_jobmanager_job_uptime{ job_name="MainClassName"} offset 10s))/1000 == 0成立时触发告警
2 编辑配置文件
vim /usr/local/prometheus/prometheus.yml
# 修改如下部分
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9293
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- rules/*.yml
# - "first_rules.yml"
# - "second_rules.yml"
重启prometheus
systemctl stop prometheus
systemctl start prometheus
5 验证配置结果
访问prometheus的alert地址 http://node01:9290/alerts
可以看到如下
5.1 杀死任务
打开flink的jobmanager地址 http://localhost:8081
cancel 某个任务
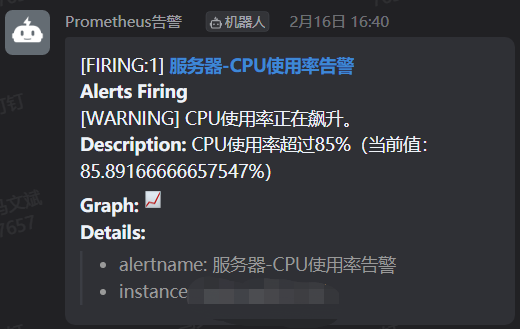
钉钉群里就收到告警信息了
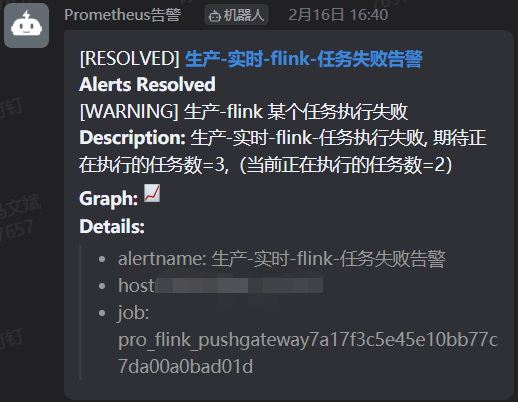
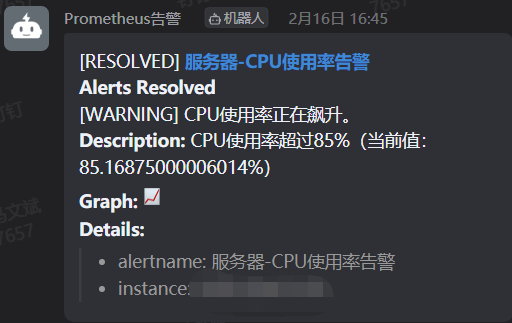
再次启动取消的任务后,可以看到问题解决的通知
多跑几个hive任务,cpu也告警了
任务执行完毕后,钉钉群发送了任务解决的通知
最后
以上就是执着哑铃最近收集整理的关于Prometheus+Grafana系统部署,linux、flink的监控与告警版本阅读说明一、简介安装规划二、安装Prometheus二、安装Grafana三、监控linux服务器四、监控Flink五、配置告警的全部内容,更多相关Prometheus+Grafana系统部署,linux、flink内容请搜索靠谱客的其他文章。








发表评论 取消回复