这里写目录标题
- 什么是string
- string的构造函数
- string的赋值重载
- string的遍历
- 第一种方式 [ ]
- 第二种方式 范围for
- 第三种方式 正向迭代器
- 反向迭代器
- string中的capacity
- size length
- max_size
- capacity
- reserve
- resize
- shrink_to_fit
- string的element access
什么是string
那这里大家就只用记住这么几点就够了,首先string他是一个类,这个类他是定义在string这个文件里面的,并且我们还用了std这个命名空间将他围了起来以免发生命名冲突,所以在下面的代码中我们首先要干的事情就是包含sting这个头文件,然后在用using namespace来释放std这个命名空间,那么这里我们的代码就如下:
#include<string>
using namespace std;
其次我们要知道的就是string这个类他是专门用来处理字符串的,在这个类里面有这么几个成员变量:
#include<iostream>
class basic_string
{
public:
private:
char* _str;
size_t _size;
size_t _capacity;
};
其中_str就是一个指针,这个指针指向的就是我们的字符串,其次这里的_size就是用来表示这里字符串的有效长度(就是不包括�),最后这里的_capacity表示的意思就是容量,也就是当前能够存储有效字符的个数,比如_capacity=20的意思就是此时最多能够储存20个有效字符,当然!当_size等于_capacity的时候,他就会自动进行扩容使其能够容纳下更多的字符,那么这就是这三个成员变量的意义,其次还有一件事就是在文件里面我们还对这个类实现了一个模板其代码的形式是这个样子:
template<class T>
class basic_string
{
public:
private:
T* _str;
size_t _size;
size_t _capacity;
};
那这里之所以实现一个模板的原因是因为:在不同的环境下我们的字符有着不同的类型,比如说:utf-8,utf-16,utf-32,w_char等等不同的类型,而这些不同的类型他们所占的空间以及对应的规则是不一样的,而我们平时使用最多的是utf-8这个类型,这个类型的字符占8个比特位而且他还能兼容ascall,所以他在内存消耗方面和使用范围方面都占了很大的优势,所以我们平时使用最多的就是utf-8这个类型,但是其他的类型不代表从今往后我们都不使用了,所以为了处理这些不同类型的字符,这个库的作者就采用了模板的形式来解决这个问题,并且对这个模板所创建出来的类型进行typedef重命名,以此来简化他的名字长度,那么我们平时所用的string就是对应的utf-8这个类型的字符他就是由typedef class basic_string<char> string重命名得来的,然后对于utf-16这个类型的字符我们就得使用u16string来对其进行处理,对于utf-32这个类型的字符我们就得使用u32string来对其进行处理等等,那么知道了这些我们就可以来跟大家介绍如何使用这里的string来对字符串进行操作。
string的构造函数
一个类中必定少不了构造函数,就算你不写编译器也会自动的给你补上一个,那么对于string这个类,开发者们给了我们多个构造函数来方便我们的日常使用:

第一个:
string();
大家可以看到第一个构造函数中是没有参数的,那么这个用这个构造函数来对其进行初始化的话,我们实例化出来的对象中是不会储存任何的有效字符的,比如说我们下面的代码:
void test1()
{
string s1;
cout << s1.size() << endl;//获取该对象中size的值
cout << s1.capacity() << endl;//获取该对象中capacity的值
}
运行结果如下:
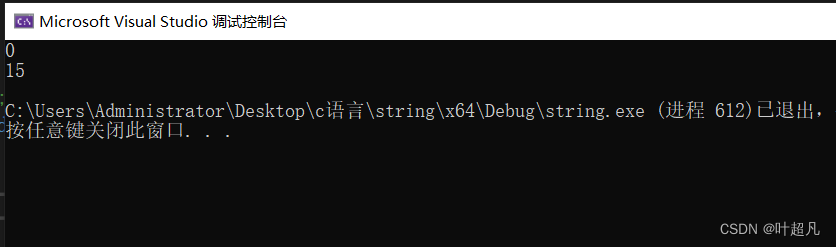
这里大家就可以看到该对象中的字符串有效长度为0,但是他的容量却不为0,那么这就是第一个构造函数所带来的结果。那么这里大姐可以看看官方给的英文解释:

第二个:
string (const string& str);
大家根据这里的参数类型就不难看出第二种形式是一个拷贝构造函数,经过前面的学习想必大家对拷贝构造函数已经非常的熟悉,我们就直接通过下面的代码来大家看看这里的使用结果是如何:
void test1()
{
string s1;
cout << s1.size() << endl;
cout << s1.capacity() << endl;
string s2("abcdefg");//第四种初始化方式
string s3(s2);
cout << s3.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s3.size() << endl;
cout << s3.capacity() << endl;
}
其代码的运行结果如下:
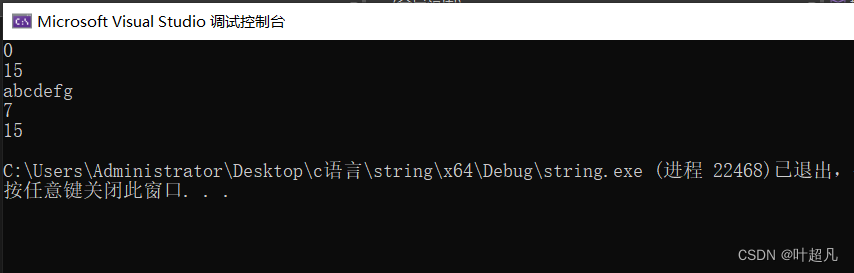
我们可以看到这里s3的中的字符串的内容和s2中字符串的内容是一样的,那么这就是第二种构造函数初始化的结果。下面是官方对这个初始化方式的介绍:

第三种:
string (const string& str, size_t pos, size_t len = npos);
第三种初始化的方式就是在第二种的基础上做出了一点改变,我们可以通过后面两个参数来控制我们想要拷贝的内容,第二个参数pos表示的是复制的开始,第三个参数参数表示的是你想要复制的长度,我们可以通过下面的代码来理解一下:
void test1()
{
string s1;
cout << s1.size() << endl;
cout << s1.capacity() << endl;
string s2("abcdefg");//第四种初始化方式
cout << "第二种构造函数的结果为:" << endl;
string s3(s2);
cout << s3.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s3.size() << endl;
cout << s3.capacity() << endl;
cout << "第三种构造函数的结果为:" << endl;
string s4(s2,1,3);
cout << s4.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s4.size() << endl;
cout << s4.capacity() << endl;
}
这段代码的运行结果为:
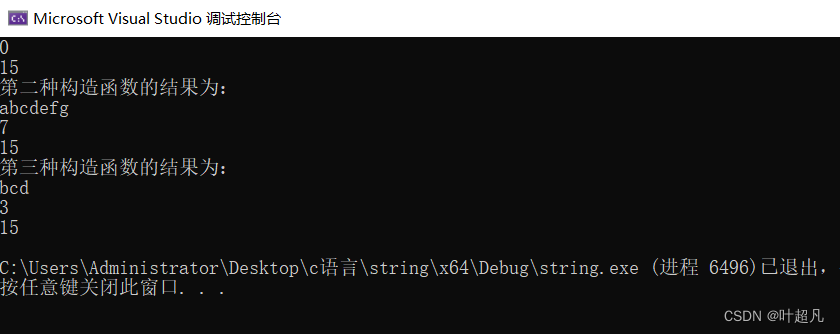
首先s2的内容是abcdefg,然后我们在用第三种构造函数进行初始化的时候给的起始位置是1,那这里对应的就是第二个元素d,给的长度是3,那么这里表示的意思就是从第二个元素开始往后数三个元素,将这三个元素来对s4进行初始化,所以这里s4的内容就是bcd,最后这里有两个小点需要大家注意一下
第一点:给的起始位置一定要合法,如果不合法的话就会报错,比如说我们下面的代码:
void test2()
{
string s1("abcdefg");
string s2(s1, 100, 2);
}
那么我们将这个代码运行一下就可以看到编译器报错了:
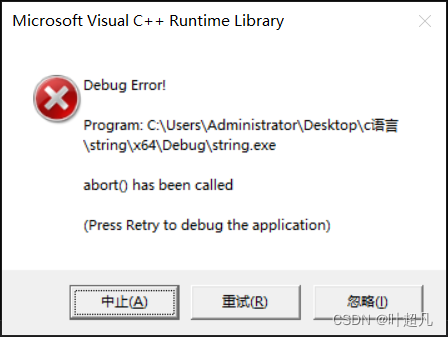
报错的原因就是因为:我们这里给的起始位置不合法,s1初始化的内容是abcdefg�所以s1中一共有8个元素,所以当我们用第三种方式进行初始化的时候,我们给的起始位置就只能是0到7,而我们上面的代码给的却是100,那毫无疑问肯定是错的,所以就报错了。
第二点:该构造函数的第三个参数表示的意思是想要拷贝过来的字符串的长度,所以这里肯定就会出现一个问题就是,如果我们给的长度非常的大超出了从起始位置开始剩余的字符串长度,那会出现什么情况呢?那这里我们就可以看看下面的代码:
void test2()
{
string s1("abcdefg");
string s2(s1, 2, 100);
cout << s2.c_str() << endl;
}
int main()
{
test2();
return 0;
}
该代码的运行结果如下:
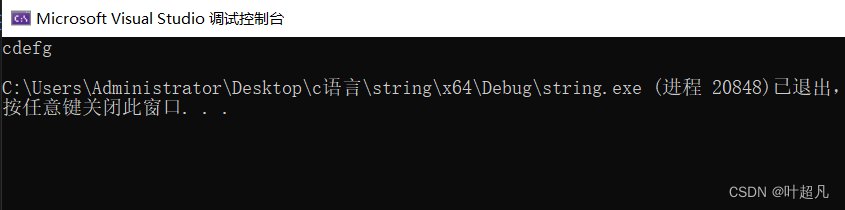
那这里我们就发现,如果给的长度过长的话,那编译器在执行拷贝构造的时候也只会拷贝到字符串的结尾为止,并不会报错或者多拷贝的情况,那么这里细心的小伙伴们肯定可以观察到第三个参数我们是给了缺省值的,而这个缺省值的大小是npos也就是-1,而第三个参数的类型是无符号整型,所以这里的-1并不表示数学上的-1,而是一个非常大的正整数,那么以后大家在使用这个函数的时候就可以利用这个缺省值来方便使用这个函数,如果你想从某个位置开始将后面的所有元素都进行拷贝的话,我们就可以不对第三个参数进行传参直接利用其缺省值,这样我们就可以不用数这里的长度,从而提升我们写代码的效率,那么下面就是官方对这个函数的英语介绍,大家可以看看:

第四个:
string (const char* s);
这个构造函数的参数是一个字符指针,那么他表示的意思就是可以使用一个字符串常量来对其进行初始化,比如说我们下面的代码:
cout << "第四种构造函数的结果为:" << endl;
string s5("abcdefg");
cout << s5.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s5.size() << endl;
cout << s5.capacity() << endl;
该代码的运行结果如下:
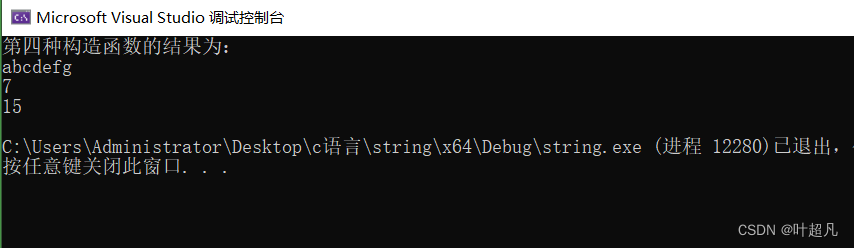
其次我们这个构造函数他没有用explicit进行修饰,所以我们还可以利用隐式类型转换通过等于号来进行赋值,比如说下面的代码:
cout << "第四种构造函数的结果为:" << endl;
string s5 = "abcdefg";
cout << s5.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s5.size() << endl;
cout << s5.capacity() << endl;
那么运行的结果也是一模一样的:
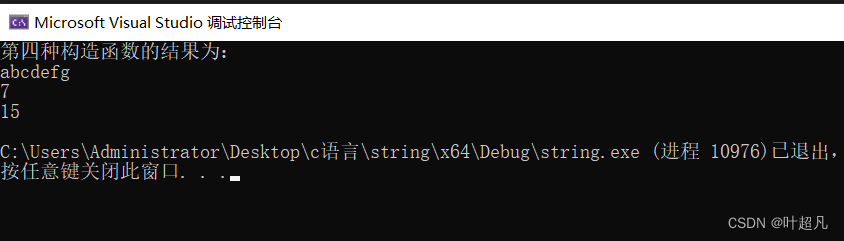
那么这就是第四种初始化的方法,大家可以看看官方对他的英文介绍:

第五种:
string (const char* s, size_t n);
这种初始化方式和第四种差不多,最大的区别就是多了一个参数n,那么这个n表示的意思就是拷贝该字符串的前几个字符,比如说下面的代码:
cout << "第四种构造函数的结果为:" << endl;
string s5 = "abcdefg";
cout << s5.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s5.size() << endl;
cout << s5.capacity() << endl;
cout << "第五种构造函数的结果为:" << endl;
string s6 ("abcdefg",3);
cout << s6.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s6.size() << endl;
cout << s6.capacity() << endl;
该代码的运行结果为:
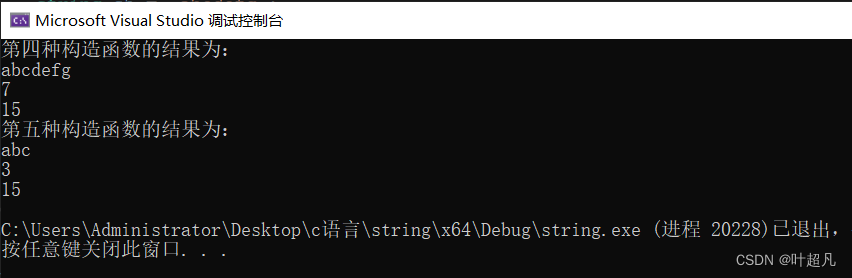
那这里我们传给n的值是3,所以他就会拷贝该字符串的前3个字符也就是这里的abc,那么这里他也会遇到同样的一个问题就是,当我们给这里n的值大于字符串的长度时编译器会报错吗?答案是不会的,这里的处理方式和上面是一样的,他会直接拷贝到字符串结束而不会报错,那这就是第五种拷贝构造函数,其官方给的英语解释如下:

第六种:
string (size_t n, char c);
这个构造函数的意思就是用多少个字符来对其进行初始化,第一个参数n表示的就是字符的个数,第二个参数c表示的就是字符,比如说我们想用10个字符’ * '来进行初始化,那我们的代码就是这样的:
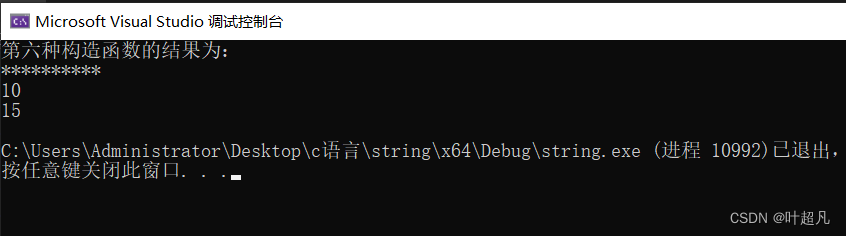
cout << "第六种构造函数的结果为:" << endl;
string s7(10, '*');
cout << s7.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s7.size() << endl;
cout << s7.capacity() << endl;
其运行的结果就如下:
该函数的官方介绍如下图所示:

第七种:
template <class InputIterator>
string (InputIterator first, InputIterator last);
那么这种方式就是用迭代器来进行初始化,那这里大家就看个例子就行,具体是什么意思大家得学了下面的内容就可以理解:
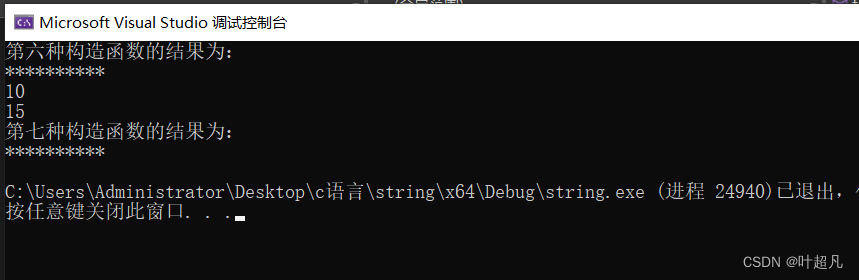
cout << "第六种构造函数的结果为:" << endl;
string s7(10, '*');
cout << s7.c_str() << endl;//打印这个对象指向的字符串的内容
cout << s7.size() << endl;
cout << s7.capacity() << endl;
cout << "第七种构造函数的结果为:" << endl;
string s8(s7.begin(), s7.end());
cout << s8.c_str() << endl;
这段代码的运行结果为:
该函数的官方英文解释如下:
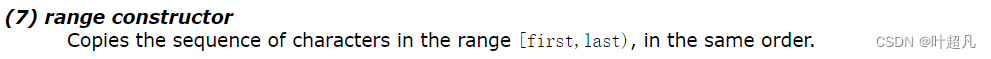
string的赋值重载
在该库当中实现了三种类型的赋值重载:
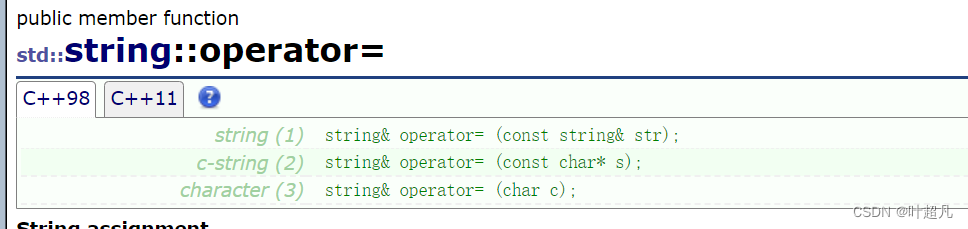
分别是用一个string类型的对象来完成赋值重载,用一个字符串来完成赋值重载,用一个字符来完成赋值重载,那这里的代码样例就如下:
void test3()
{
string s1("abcdefg");
string s2, s3, s4;
s2 = s1;
s3 = "hijklmn";
s4 = 'h';
cout << s2.c_str() << endl;
cout << s3.c_str() << endl;
cout << s4.c_str() << endl;
}
这段代码的运行结果就如下:
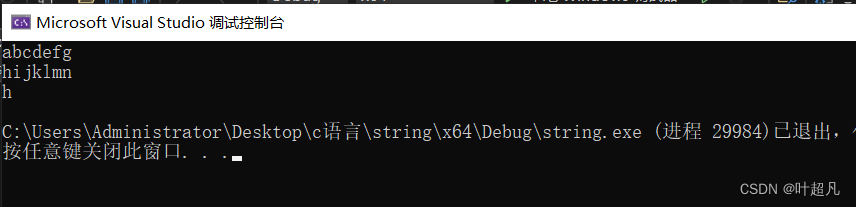
string的遍历
既然我们能对string所创建的对象进行初始化赋予他内容的话,那么接下来我们要做的就是遍历这个对象中的数据,那么这里我们有三种方式来进行遍历。
第一种方式 [ ]
第一种遍历的方式就是通过下标引用操作符( [ ] )来实现遍历,在库中实现了对该操作符的重载,这样就能够让我们直接访问并修改这个对象中的数据,比如说下面的代码:
void test4()
{
string s1("abcdefg");
int i = 0;
while (i < s1.size())
{
s1[i++]++;
}
cout << s1.c_str() << endl;
}
这段代码运行的结果为:
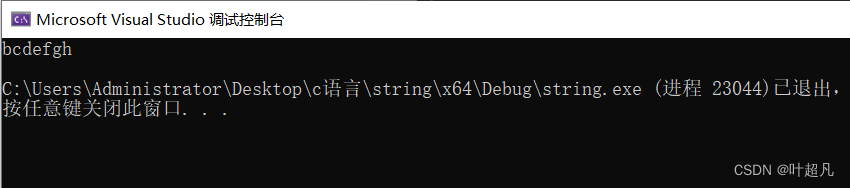
那么这里大家可以看到原来的abcdefg变成了bcdefgh,而英语字母的ascll码值是连续的,所以我们这里的执行结果就是正确的,那么这里大家应该能够理解这里[ 的]作用,他可以让我们以下标的方式来访问到string对象中的数据,并且还能对其进行修改,而且库中还提供了两个不同的版本:

一个是const版本另外一个是非const版本,那const版本就只能读不能写,而非const版本是既可以读还可以写,下面是官方对这个操作符重载的介绍:


第二种方式 范围for
第二种遍历的方式就是通过范围for来实现string的遍历,那这里我们跟上面一样对内容进行修改使其每个元素的ascall值都加一,那这样的话我们就得在auto后面加上一个&将其形式变成引用这样得话,我们就可以直接对其内容进行修改,那么这里我们的代码就如下:
void test4()
{
string s1("abcdefg");
int i = 0;
while (i < s1.size())
{
s1[i++]++;
}
cout << s1.c_str() << endl;
for (auto& ch : s1)
{
ch++;
}
cout << s1.c_str() << endl;
}
代码得运行结果如下:
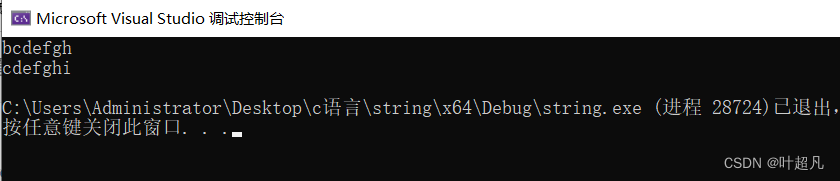
字符串由bcdefgh变成了cdefghi,每个元素得ascll值都加上了1,那么这就说明我们得代码是真确的。
第三种方式 正向迭代器
第三种方式是通过正向迭代器来实现对字符串的遍历,我们首先看看迭代器在库中的形势:

首先迭代器的一个关键是iterator ,这是一个类型这个类型属于string这个类,然后我们用这个类型创建变量的时候就得用上面的这些函数来进行初始化,比如说我们下面这行代码:
string::iterator it1 = s1.begin();
那这里我们就来看看上面的这两个函数是什么意思,首先来看看begin:
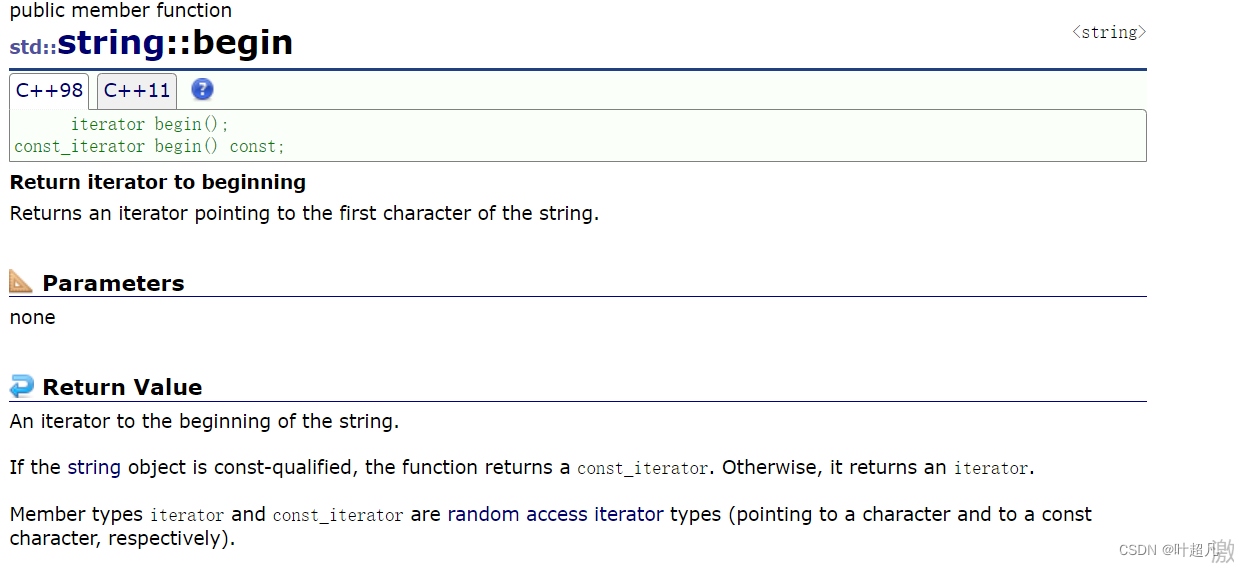
begin这个函数的作用就是让迭代器指向字符串的第一个元素,那么同样的道理end函数的作用就应该是让迭代器指向字符串的末尾也就是�,那么该函数的介绍如下:
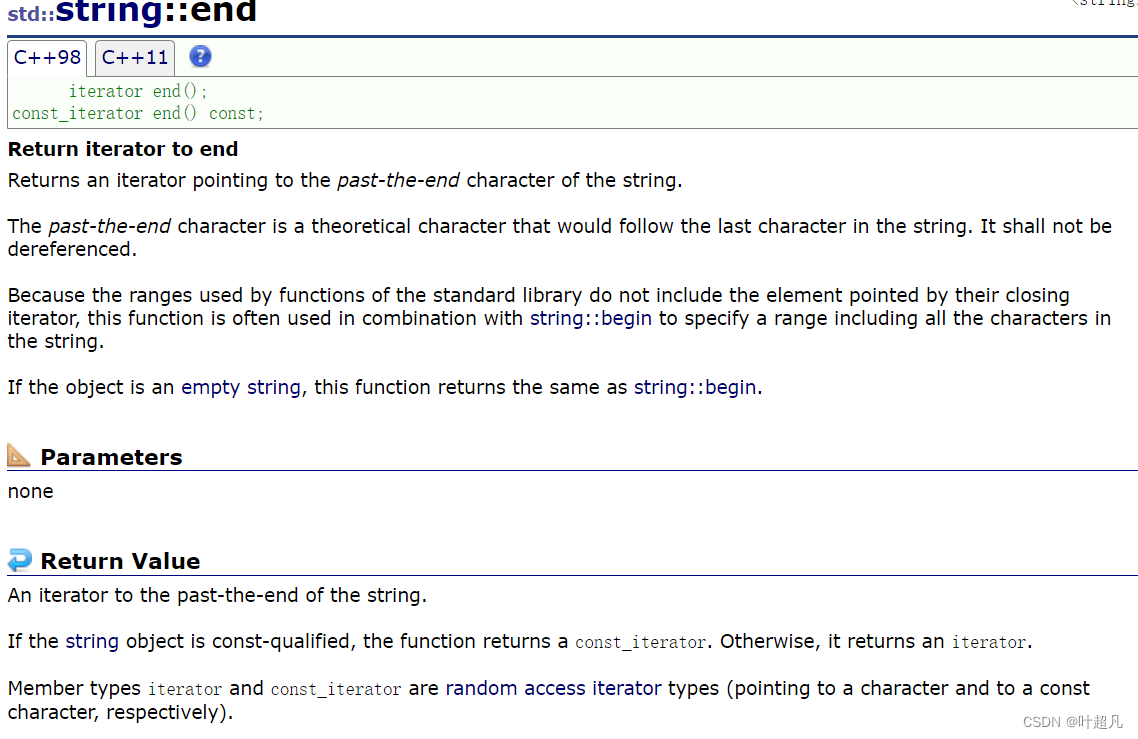
我们说迭代器行为上像指针,所以在使用的时候我们就以指针的形式来使用他,比如说下面的代码:
void test4()
{
string s1("abcdefg");
int i = 0;
while (i < s1.size())
{
s1[i++]++;
}
cout << s1.c_str() << endl;
for (auto& ch : s1)
{
ch++;
}
cout << s1.c_str() << endl;
string::iterator it1 = s1.begin();
while (it1 != s1.end())
{
(*it1)++;
it1++;
}
cout << s1.c_str() << endl;
}
这段代码的运行结果如下:
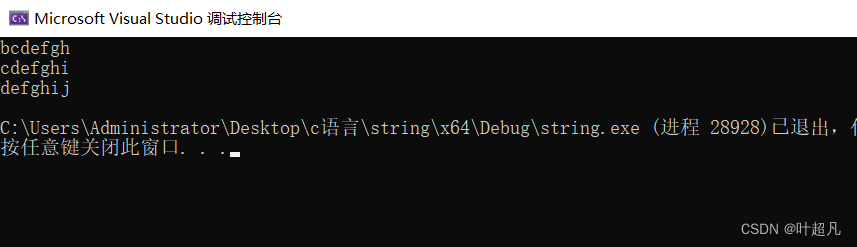
字符串cdefghi变成了defghij,所以我们这里的代码实现的就是正确的,那这里肯定有很多小伙伴们有疑问说:为什么得搞一个迭代器呢?我们前面的两种方式用的不是挺好的吗?那这里大家要知道的是迭代器遍历数据是一个通用的形式,对于string这个类可以使用对于我们后面学的其他库他也可以使用,而前两种遍历方式他对于现在string这个库可以很好的遍历并修改,但是对于其他的库他就不会那么容易了,有可能就完全遍历不了,所以这就是我们学习迭代器的原因,这里还有一点大家要注意的就是,迭代他是行为上类似于指针,那有些小伙伴就会认为他就是指针,既然是指针的话那他就会直接将上面的代码修改成这样:
char* it1 = s1.begin();
while (it1 != s1.end())
{
(*it1)++;
it1++;
}
cout << s1.c_str() << endl;
那这里就是一个非常严重的错误,因为我们学的stl他只是一个规范,并没有准确的规定其实现的原理,也就是说不同的平台下实现的原理是不一样,那在有些平台下他会通过指针来实现这个迭代器,而有些平台却不会,那这里我们拿char*来进行接收的话就可能会导致该代码在一些平台上跑的了,在另外的一些平台跑不了的情况,这里大家要注意一下。
反向迭代器
既然有正向迭代器,那么也就一定有反向迭代器,反向迭代器就得将iterator改成了reverse_iterator,将begin改成rbegin,将end改成rend,但是跳转数据的++可不能改成–,下面是rbegin的函数介绍:
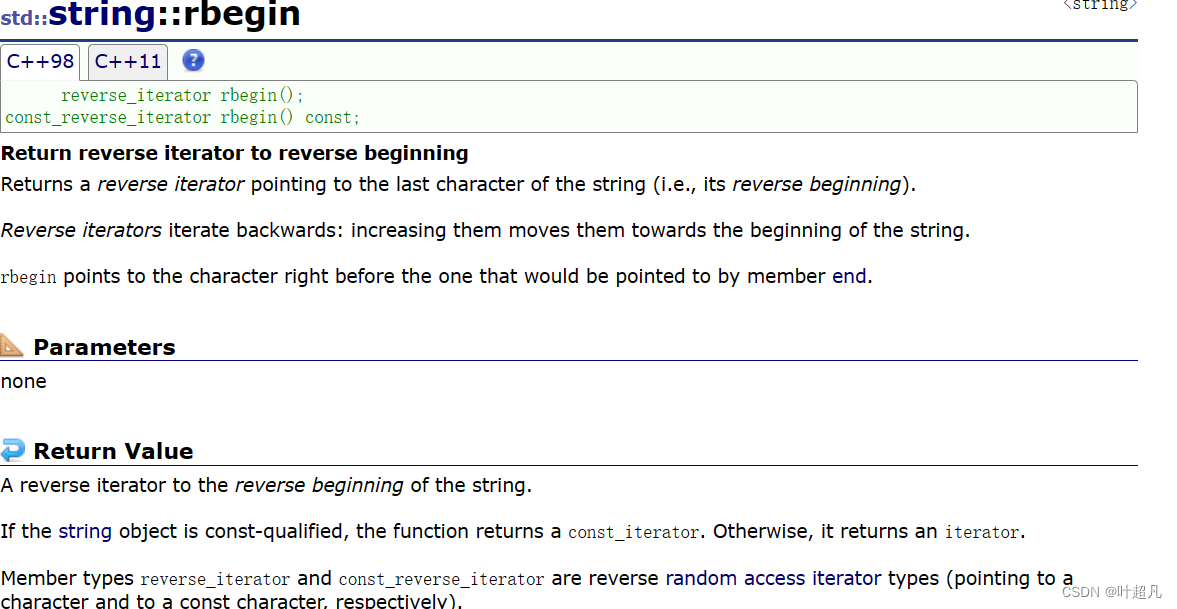
rend的函数介绍:
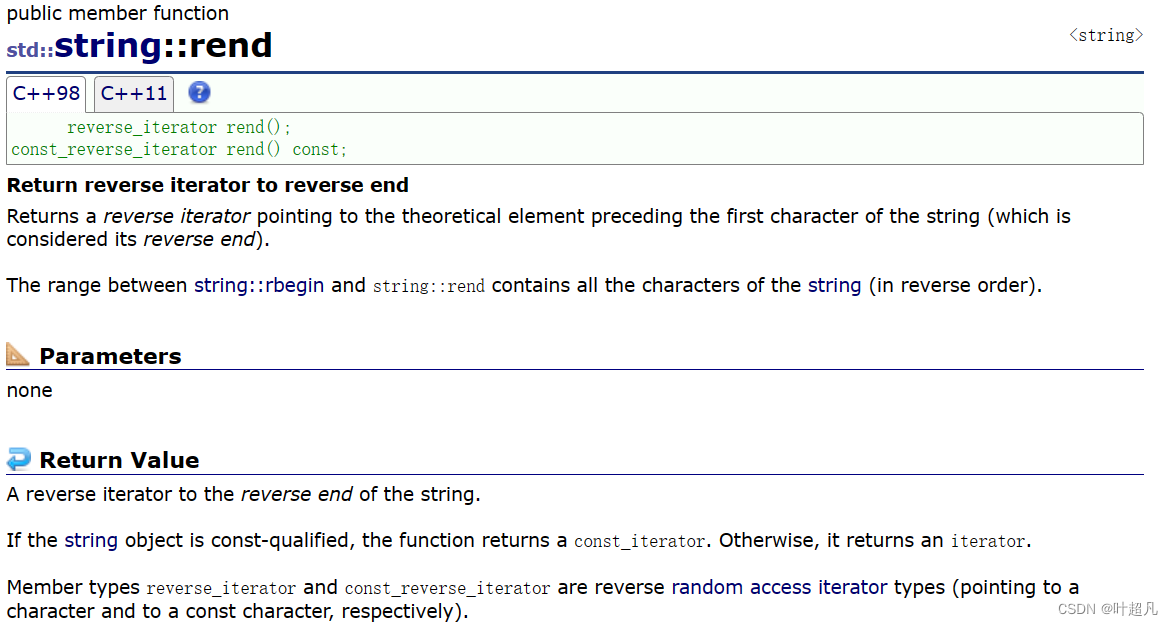
这里大家可以看看下面的代码来看看反向迭代器是如何使用的:
void test5()
{
string s1("abcdefg");
string::reverse_iterator it1 = s1.rbegin();
while (it1 != s1.rend())
{
cout << *it1;
it1++;
}
}
代码的运行结果如下:

正向迭代器是从左向右遍历数据,那我们这里的反向迭代器就是从右向左的遍历数据,所以我们这里打印出来的数据就是gfedcba,那这里打击要注意的一点就是rend和end不能混着使用,比如说在while循环中的判断语句就不能写成这样:
string s1("abcdefg");
string::reverse_iterator it1 = s1.rbegin();
while (it1 != s1.end())
因为it1的类型是reverse_iterator类型,而end返回的类型是iterator类型,这两个类型是不一样的,所以就不能一起进行比较,这里大家要注意一下。最后再说一点就是我们这里使用的end rend,begin rbegin都有两个类型一个是const,另外一个是非const,那下面的这四个函数就与上面的4个函数一一对应只不过他们只用一个类型就是const:

所以他们也就叫cbegin,cend,crbegin,crend,这里大家可以看看下面的函数介绍:
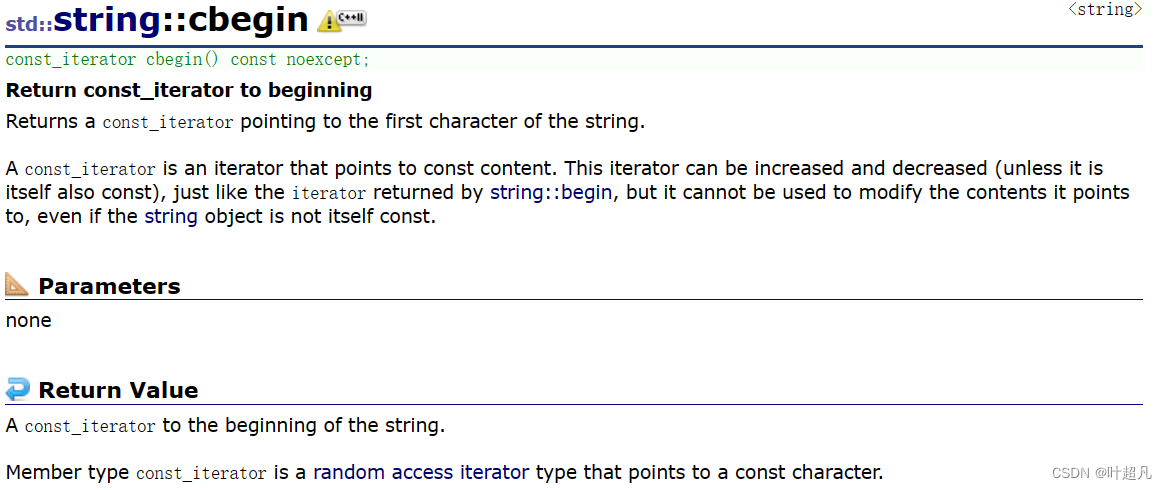
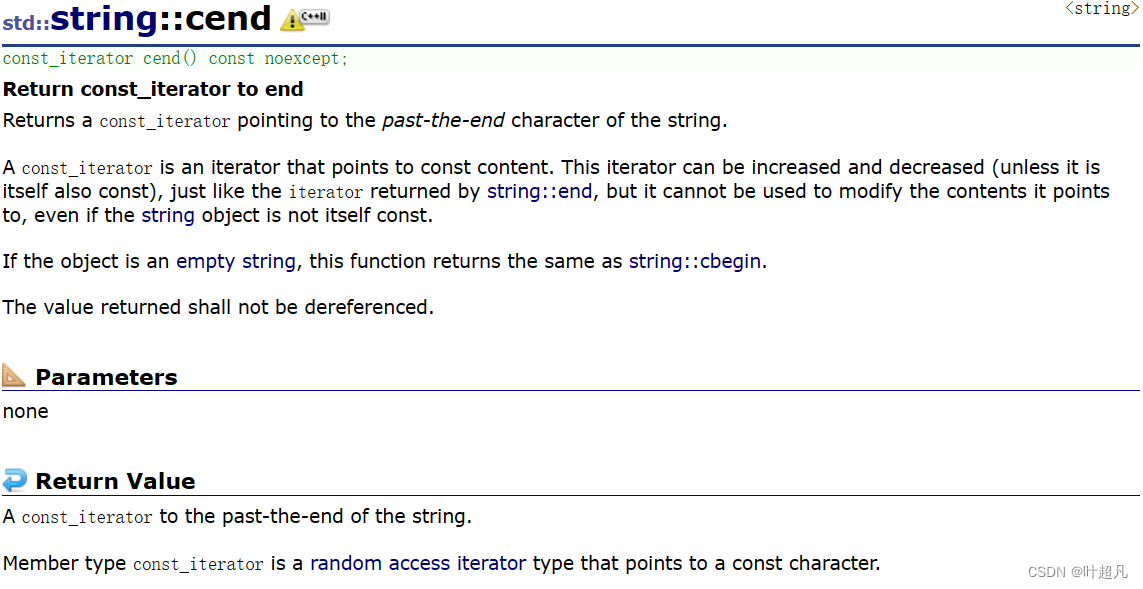
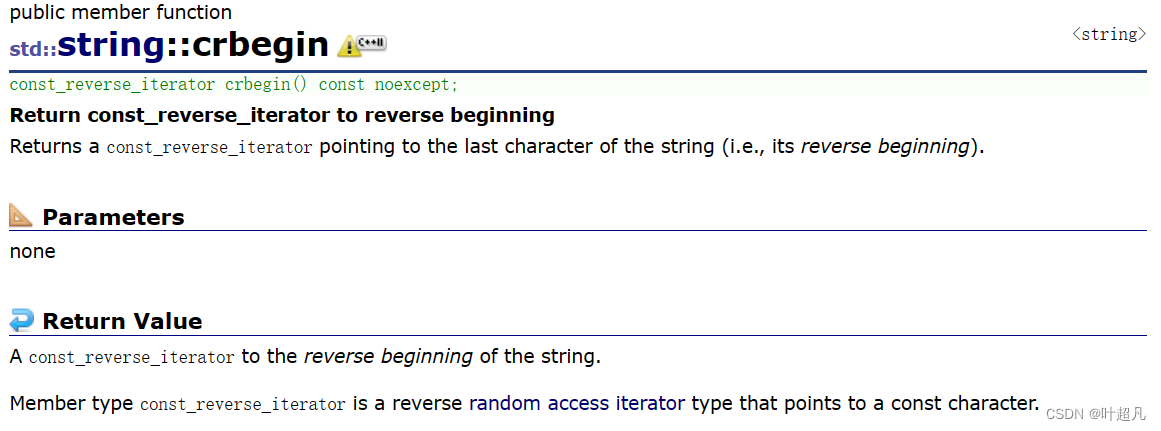

string中的capacity
我们来看看这一块有哪些函数

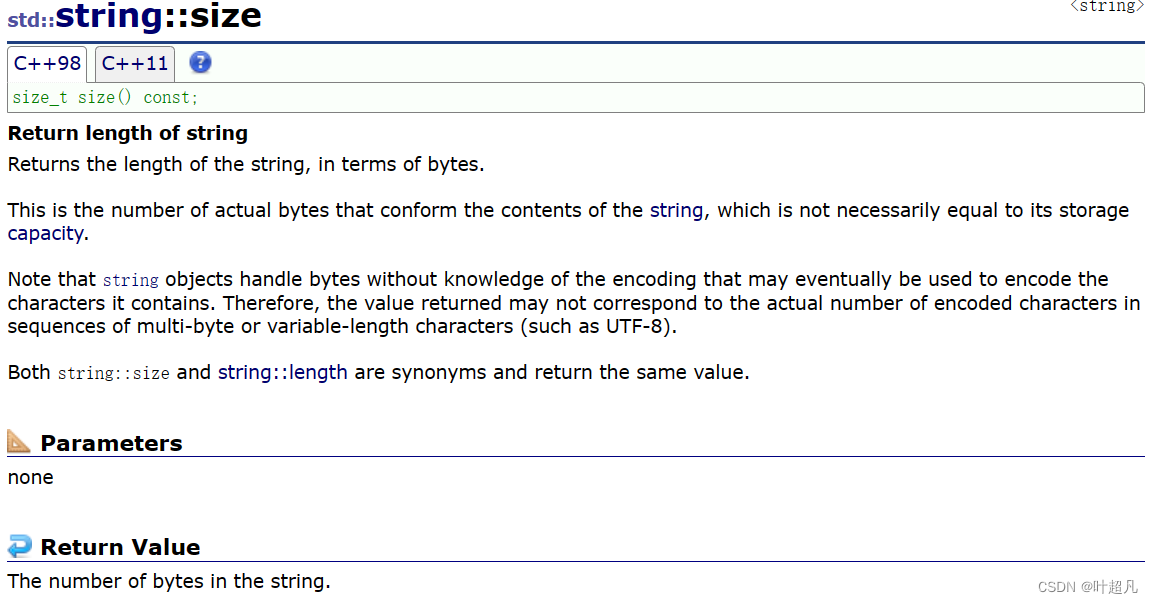
size length
这两个函数size和length的作用是一样的,都是返回对象中的字符串的长度:
void test6()
{
string s1("abcdefg");
cout << s1.size() << endl;
cout << s1.length() << endl;
}
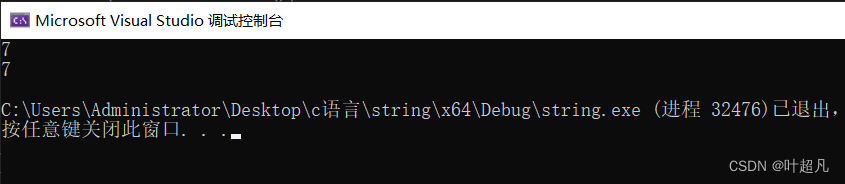
这里初始化的内容是abcdefg有7个有效字符,所以这里打印出来的字符串长度就是7。这里的用法都非常的简单哈,大家可以来看看官方给的英文介绍;
max_size
这个函数用的就很少,他的功能就是告诉使用者使用string创建的对象最多能够容纳多少个有效字符。
void test6()
{
string s1("abcdefg");
cout << s1.size() << endl;
cout << s1.length() << endl;
string s2("abcd");
cout << s1.max_size() << endl;
cout << s2.max_size() << endl;
}
这段代码的运行结果为:
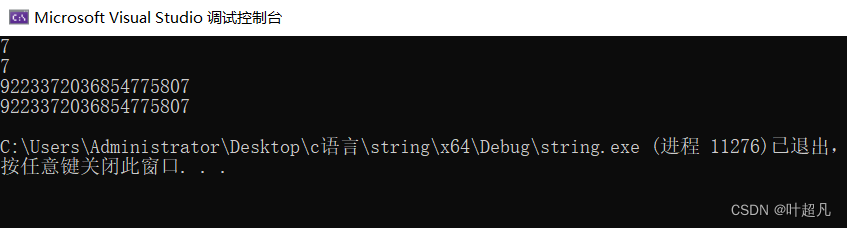
那么这里大家可以看到这里我们初始化的长度不一样,但是他们所能够达到的最大长度都是一样的是一个非常大的数。
capacity
这个函数的作用就是告诉使用者当前对象的容量是多少,比如说下面的代码:
string s1("abcdefg");
cout << s1.size() << endl;
cout << s1.capacity() << endl;
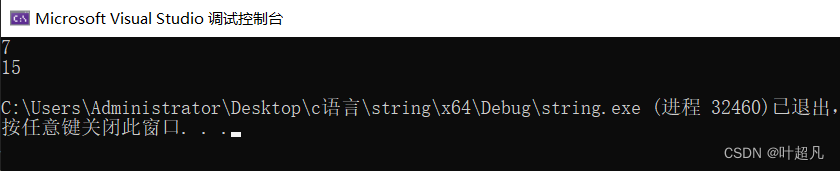
那么这就表明当前对象中含有7个有效字符容量为15,当size的值大于capacity的值时,该对象就会自动的扩容增加capacity的值,比如说我们下面的代码:
string s2;
int i = 0;
size_t _capacity = s2.capacity();
while (i < 1000)
{
s2 += 'a';//向字符串尾插一个字符
if (s2.capacity() != _capacity)//如果容量发生了改变就打印改变后的值
{
cout << _capacity << endl;
_capacity = s2.capacity();
}
i++;
}
cout << _capacity << endl;
其代码的运行结果如下:
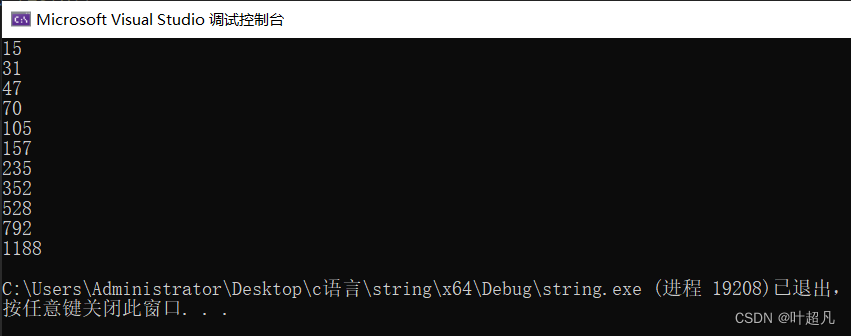
我们可以看到这里随着字符串的长度不断地变长,该对象的容量也在不断地变大,其变大的规律为每次扩大1.5倍,当然这里扩大的规律不同的编译器下是不一样的,gcc编译器就是每次都扩容两倍,那么这就是capacity函数的用法,他的英文解释如下:
reserve
大家可以看到,当我们不断地往对象中插入数据时,对象就会自动的进行扩容,那这里就会存在一个问题:扩容是会损失效率的,如果扩容的次数过多的话就会导致代码的执行效率降低,所以当我们知道了要操作的字符串的长度时,我们最好能够一次性将容量开够以免进行多次扩容,那这里我们要用的函数就是reserve,他可以一次性开辟一个我们想要的空间的大小,比如说下面的代码:
string s1;
s1.reserve(1000);
cout << s1.capacity() << endl;
这段代码的运行结果为:
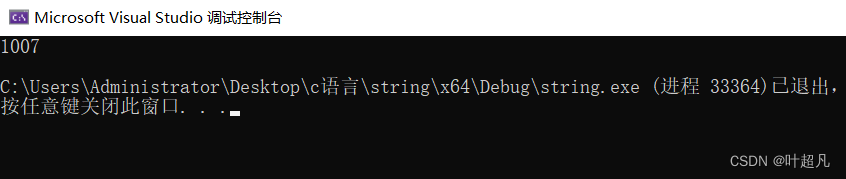
我们给reserve函数传的参数是1000,表明的意思是想将容量开到1000,但是打印出来的capacity的值却变成了1007,那这就是因为在扩容的过程中存在着内存对齐的行为,所以编译器会多开一点空间,那么这就是该函数的作用,大家可以看看对应的英文介绍:
resize
这个函数的作用就是修改有效字符的长度,比如说下面的代码:
string s1("abcdefg");
string s2("abcdefg");
string s3("abcdefg");
cout << s1.size() << endl;
cout << s2.size() << endl;
cout << s3.size() << endl;
cout << s1.capacity() << endl;
cout << s2.capacity() << endl;
cout << s3.capacity() << endl;
s1.resize(4);
s2.resize(10,'*');
s3.resize(19,'#');
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
cout << s3.c_str() << endl;
cout << s1.size() << endl;
cout << s2.size() << endl;
cout << s3.size() << endl;
cout << s1.capacity() << endl;
cout << s2.capacity() << endl;
cout << s3.capacity() << endl;
如果你给的长度小于原来字符串的长度的话,那么经过resize操作你的字符串将变的更小,如果你给的长度大于字符串的长度但是小于容量的值的话,那么该字符串的长度将边长并且读出来的地方将由你给的字符来填充,当你给的长度大于字符串的长度还大于容量的话,那么编译器将自动的扩容并且将多余的长度用你给的第二个字符来进行填充,当然这里你可以不使用第二个参数,这样的话编译器就会拿�来进行填充,上面的代码运行结果如下:
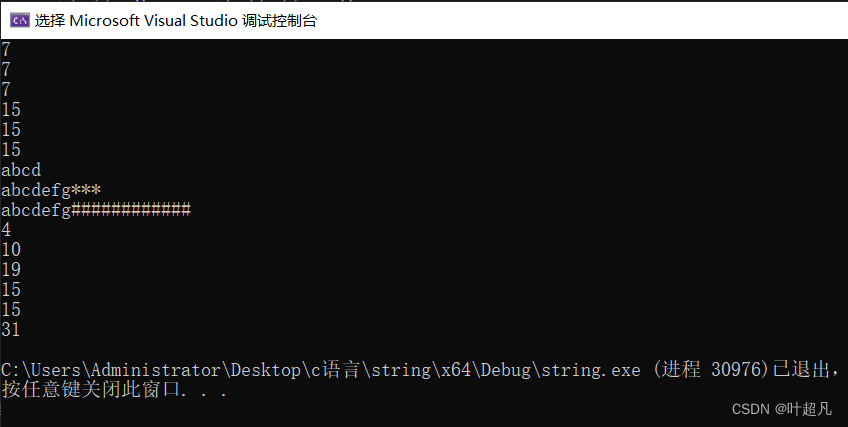
这里大家可以看到这三个对象的长度都发生了变化,s1的长度变小,s2 s3的长度变大,而s1 s2的容量没有变但是s3的容量却变大了,那么这就是resize的作用他可以改变有效字符的长度,并且还能按我们给的字符来对多余的长度进行填充,下面就是该函数的英文解释:

shrink_to_fit
这个函数的作用就是将对象中容量的大小与size的大小保持一致,比如说下面的代码:
#include <iostream>
#include <string>
int main ()
{
std::string str (100,'x');
std::cout << "1. capacity of str: " << str.capacity() << 'n';
str.resize(10);
std::cout << "2. capacity of str: " << str.capacity() << 'n';
str.shrink_to_fit();
std::cout << "3. capacity of str: " << str.capacity() << 'n';
return 0;
}
这个代码的运行结果如下:

这里我们用resize函数将对象的有效长度降为10之后,再用shrink_to_fit就会使得capacity的值和size的值保持一致都变成了 10,当然这段代码的运行结果我是抄官网的,我的vs编译器执行的结果与官网的不一样,他只能做到尽量保持一致,那么这里大家了解一下就行这个在实际使用中用到的地方很少。
string的element access

这里at的功能和上面的[ ]的功能是一样的,都是访问对象中字符串的元素,但是区别就在于对于不合法的位置[ ]会直接报错而at他会抛异常,比如说我们下面的代码:
void test7()
{
string s1("abcdefg");
s1[100]++;
}
我们将这段代码运行起来就可以发现编译器直接报错了:
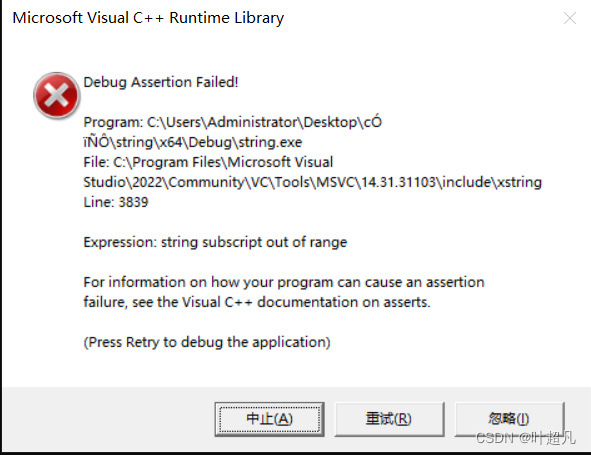
我们再看这段代码:
void test7()
{
string s1("abcdefg");
//s1[100]++;
s1.at(100) = 'd';
}
int main()
{
try
{
test7();
}
catch (exception& e)
{
cout << e.what() << endl;
}
return 0;
}
将这段代码运行一下就可以发现,他并没有直接报出错误,而是抛出了异常:

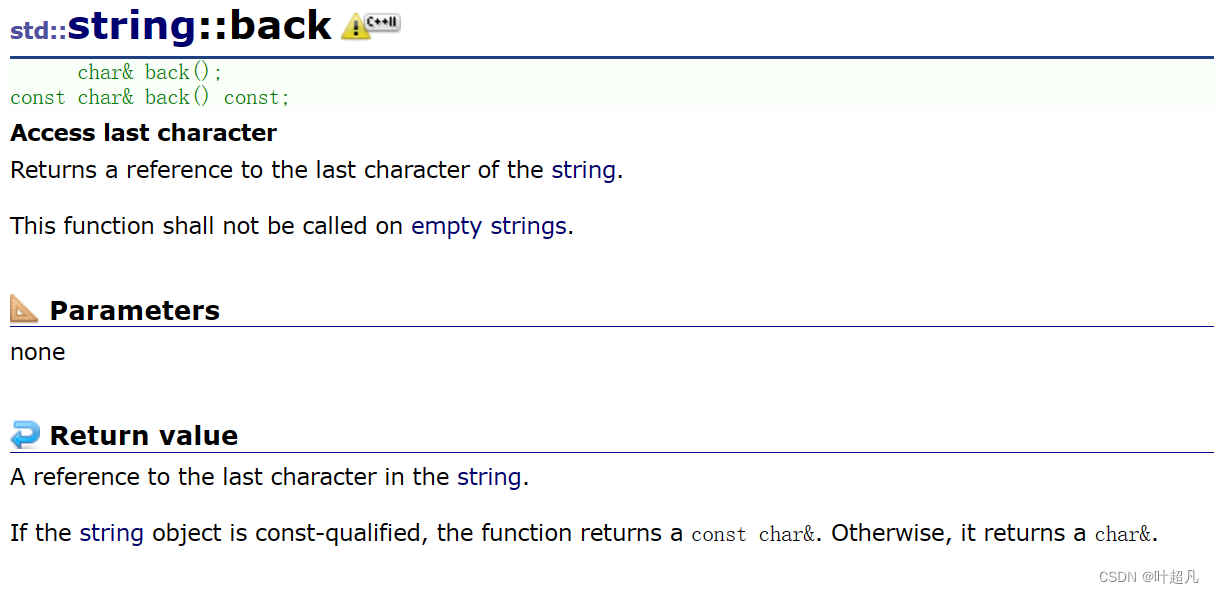
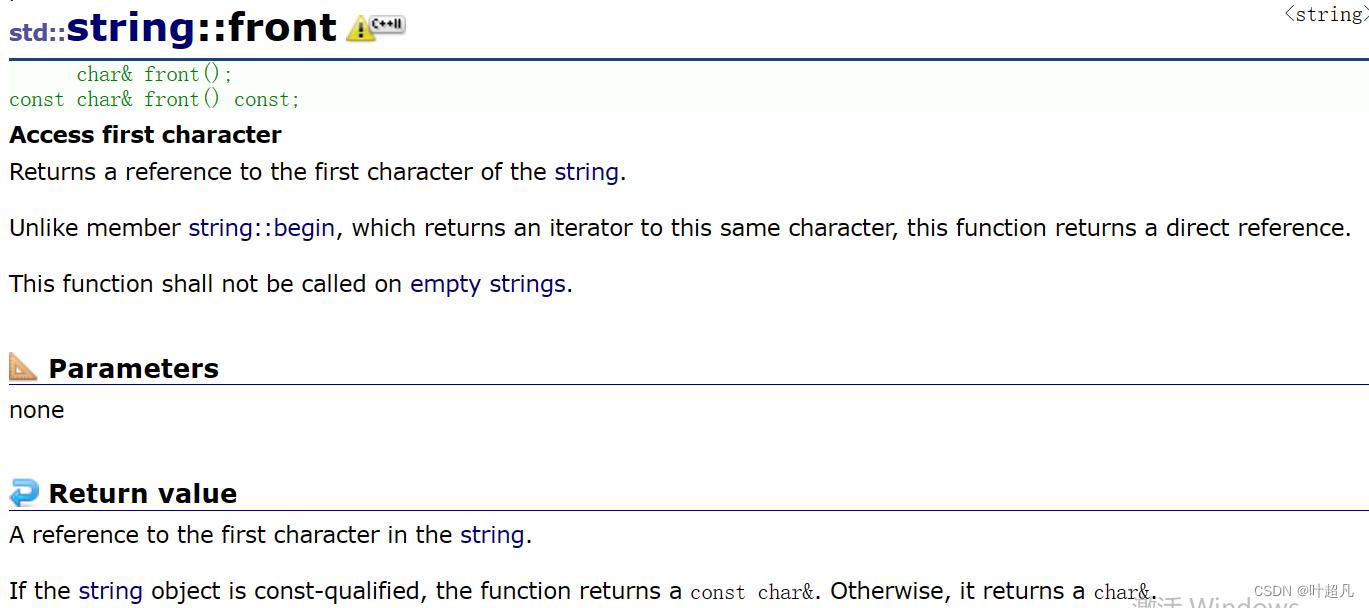
说这是一个不正常的字符位置,那么这就是at和[ ]的区别,大家这里注意一下就行,在平时使用过程中我们还是用[ ]用的多一些,然后在这个模块当中还有back和front这两个函数,这两个函数的作用就分别是返回字符串中的最后一个元素和返回字符串中的第一个元素,这里的返回是引用返回,所以我们就可以通过该函数来直接修改字符串中的内容,比如说下面的代码:
string s1("abcdefg");
s1.front() = 'g';
s1.back() = 'a';
cout << s1.c_str() << endl;
该代码的运行结果为:
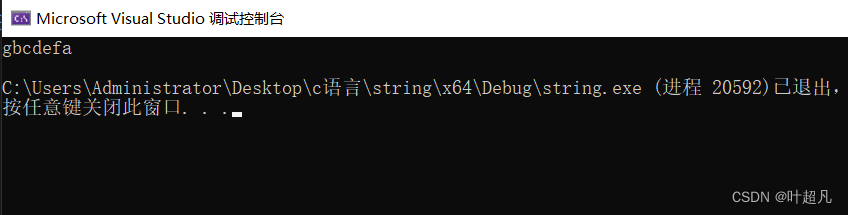
该对象中的字符串确实发生了修改那么这就说明我们的代码实现的是正确的这四个函数的英文介绍如下图所示:


最后
以上就是清爽电源最近收集整理的关于详解c++---string的介绍(上)什么是stringstring的构造函数string的赋值重载string的遍历string中的capacitystring的element access的全部内容,更多相关详解c++---string的介绍(上)什么是stringstring的构造函数string的赋值重载string的遍历string中的capacitystring的element内容请搜索靠谱客的其他文章。


![[C++] C++标准库中的string类的使用(下)、4、C++标准库中string类的类体外已显示实现的常见的非类成员函数(全局函数)接口](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)





发表评论 取消回复