本周介绍了 5 个视频相关的 SoTA 模型: VideoMAE 成功在视频模型中加入超高遮蔽率、ViS4mer 处理长视频高效又低成本、Flamingo 只需小样本就能胜任多种视觉语言任务,VDTN 用多模态的概念重新定义对话状态追踪任务,ActionFormer 率先将 Transformer 应用到时空动作定位任务。
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些免费的鼓励:点赞、喜欢、或者分享给你的小伙伴。 towhee/towhee/models at main · towhee-io/towhee · GitHub
第一个视频 MAE 框架:高遮挡、高性能
出品人:Towhee 技术团队 顾梦佳
受到 ImageMAE 的启发,南大与腾讯联合提出 VideoMAE,率先将 MAE 引入视频理解模型。VideoMAE 使用视频掩码自编码器,高效利用数据进行自监督视频预训练(SSVP)。使用一些简单的设计,模型就能够有效地克服视频重建过程中由于时间相关性引起的信息泄漏问题。即使当遮挡率很高的时候(90%-95%),模型仍然可以获得良好的性能。不仅如此,VideoMAE 在小数据集上(大约3-4千视频)上取得了令人印象深刻的结果。此外,无需任何额外数据,VideoMAE 搭配 ViT (视觉 Transformer)骨干网络,在各种公开视频数据集上均能达到优秀的效果(Kinetics-400:83.9%,Something-Something V2:75.3%,UCF101:90.8%,HMDB51:61.1%)。
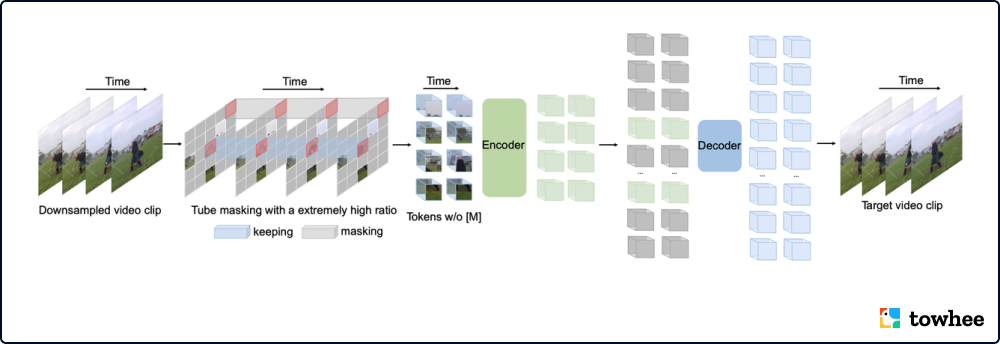
VideoMAE Architecture
VideoMAE 的关键是与掩码相关的两个设计:极高的掩蔽率和tube掩蔽策略。相比于图像 MAE,视频数据在时空维度上存在更多的冗余。为了不让模型从高度相似的相邻帧学到重建的知识,模型使用非常高的遮盖率从视频中删除时间立方体。同时,这一操作也降低了编码器-解码器架构的预训练成本。为了降低重建过程中的信息泄露风险,模型采用了 tube 掩蔽策略加入时间的相关性。
相关资料:
-
模型代码:GitHub - MCG-NJU/VideoMAE: [NeurIPS 2022] VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
-
论文:Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
-
更多资料:VideoMAE:南大MCG&腾讯AI Lab 提出第一个视频版MAE框架,使用90%甚至95%遮挡,性能SOTA!
ViS4mer 仅需1/8内存,数倍提速长视频分类
出品人:Towhee 技术团队 顾梦佳
Vis4mer 是一种高效的长视频模型,结合了自注意力的优势和最近引入的结构化状态空间序列(S4)层。对比相应的纯自注意力模型,Vis4mer的速度提升了2.63倍,而且节省了8倍的显存占用。在长视频理解(LVU)基准的 9个电影视频分类任务中,ViS4mer 取得了其中6个任务的最先进成果。此外,实验证明 Vis4mer 能够成功地被推广到其他领域,在 Breakfast 和 COIN 两个视频动作数据集中取得了具有竞争力的成果。
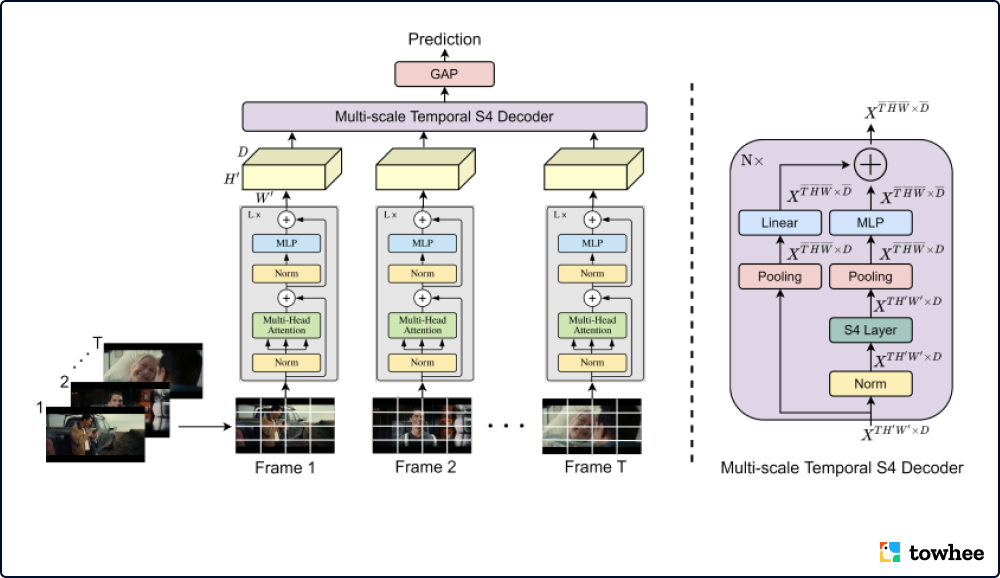
Overview of ViS4mer
已有的大多数视频模型都更适用于短视频,需要复杂的计算和长时间的推理才能完成长视频理解任务。最近引入的视频 Transformer 通过使用远程时间自注意力解决部分问题,然而这需要非常昂贵的成本二次运行注意力机制。Vis4mer 使用标准的 Transformer 编码器提取短距离时空特征,随后使用多尺度的时间 S4 解码器进行长距离的时空推理。逐步减少每层解码器的时空特征分辨率和通道维度,Vis4mer 能从视频中学习复杂的长距离时空依赖性。
相关资料:
-
模型代码:GitHub - md-mohaiminul/ViS4mer
-
论文:Long Movie Clip Classification with State-Space Video Models
DeepMind 又一力作,超小样本学习,视觉语言模型 Flamingo 刷新各种多模态任务榜单!
出品人:Towhee 技术团队 张晨、顾梦佳
仅使用少量注释示例构建可以快速适应众多任务的模型,是多模态机器学习研究的一项公开挑战。由 DeepMind 在今年提出的 Flamingo —— 一种视觉语言模型(VLM)的新架构,就能够仅靠小样本学习就为各种多模态任务(如图像描述、VQA)刷新 SOTA!在许多基准测试中,Flamingo 的性能超过了那些使用数千倍的特定任务数据进行微调的模型。
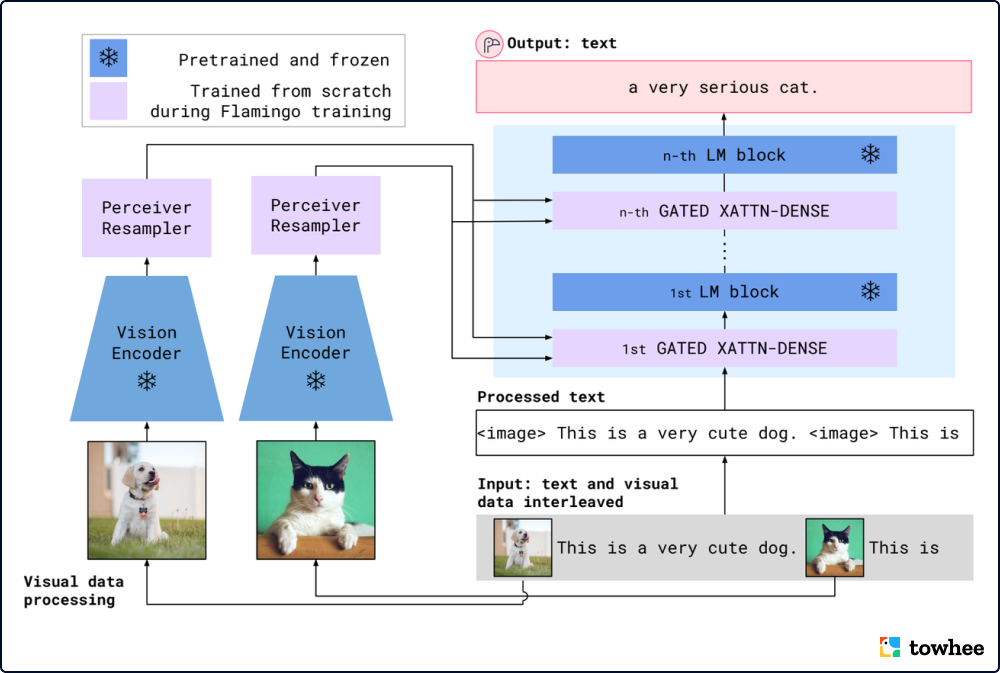
Overview of the Flamingo model.
Flamingo 的关键在于对架构的创新:连接强大的预训练视觉和语言模型、处理任意交错的视觉和文本数据序列、无缝摄取图像或视频作为输入。由于该架构的灵活性,Flamingo 系列模型可以在包含任意交错的文本和图像的大规模多模式网络语料库上进行训练,这也是获得上下文小样本学习能力的关键。Flamingo 探索了开放式多模态任务(例如视觉问答、描述任务)以及封闭式任务(例如多项选择视觉问答),证明了该架构的单个模型就可以使用少量学习的最新技术,只需通过特定任务示例提示模型即可。
相关资料:
-
模型代码:GitHub - lucidrains/flamingo-pytorch: Implementation of ???? Flamingo, state-of-the-art few-shot visual question answering attention net out of Deepmind, in Pytorch
-
论文:Flamingo: a Visual Language Model for Few-Shot Learning
-
更多资料:少到4个示例,击败所有少样本学习:DeepMind新型800亿模型真学会了
多模态模型 VDTN 重新定义对话状态追踪任务
出品人:Towhee 技术团队 王翔宇、顾梦佳
为了在对话中跟踪用户的目标,对话系统中需要一个重要的组件,即对话状态跟踪器。然而,对话状态跟踪很大受限于单模态形式,状态中的字段(slots)都需要根据专业知识预先设计。为了解决这一问题,VDTN 将对话状态拓展成了多模态的形式,追踪视频对话中提到的视觉对象,重新定义了对话状态追踪任务。这一创新成功优化了状态生成任务和自监督学习的视频理解任务(如视频分割、目标识别),让大家看到了多模态对话系统的更多潜力。
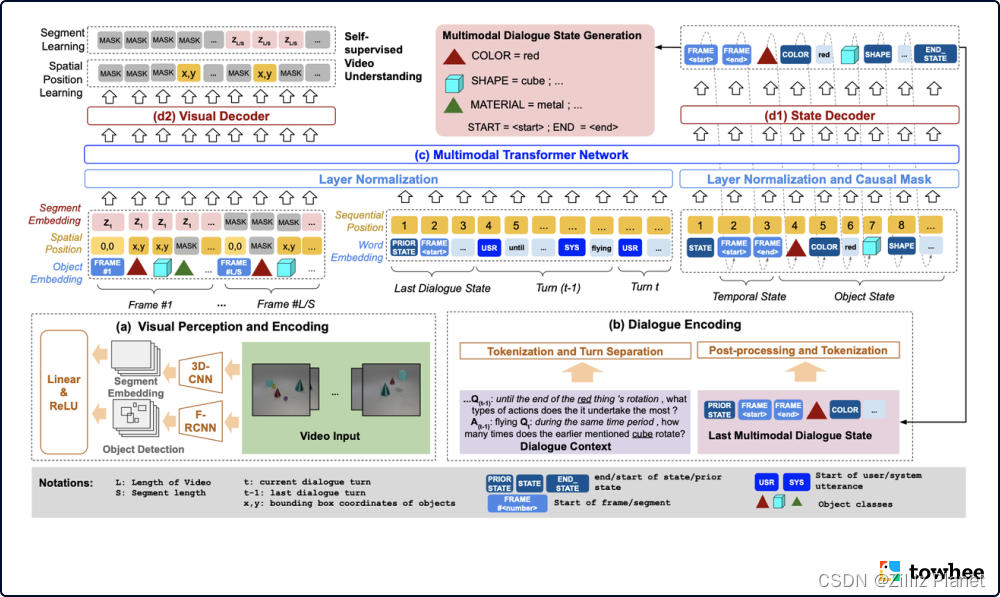
Key components of Video-Dialogue Transformer Network(VDTN)
VTDN 结合物体级别和片段级别的特征,学习视频和对话之间的上下文依赖,从而生成多模态对话状态。该模型由4个核心部分构成:视觉感知和编码、对话编码、多模态 Transformer 网络、状态和视觉解码。视觉感知和编码器使用预训练好的 Faster R-CNN 提取视频帧中的物体特征,并使用 ResNeXt 模型提取视频片段级别的表征。对话编码器将对话文本进行编码,并且与传统对话状态追踪类似,将状态信息展开作为序列处理。然后视觉特征与对话特征一起经过多模态 Transformer 架构后,分别进行解码处理,最终生成多模态对话状态。
相关资料:
-
模型代码:https://github.com/henryhungle/mm_dst
-
论文:Multimodal Dialogue State Tracking
ActionFormer 率先将 Transformer 应用到时空动作定位任务
出品人:Towhee 技术团队 何俊辰、顾梦佳
ActionFormer 结构简单但设计合理,首次在时空动作定位(TAL)任务中提出 single-stage 与 anchor-free,探索了将 Transformer 用于 TAL 的关键设计因素。ActionFormer 在 TAL 上成功获得了 SOTA 表现。例如,ActionFormer 在大型视频数据集 THUMOS14 上大幅超越之前的模型,取得 71.0% mAP;在其他公开的视频数据集上,比如 ActivityNet 1.3 和 EPIC-Kitchens 100,也都表现优异。
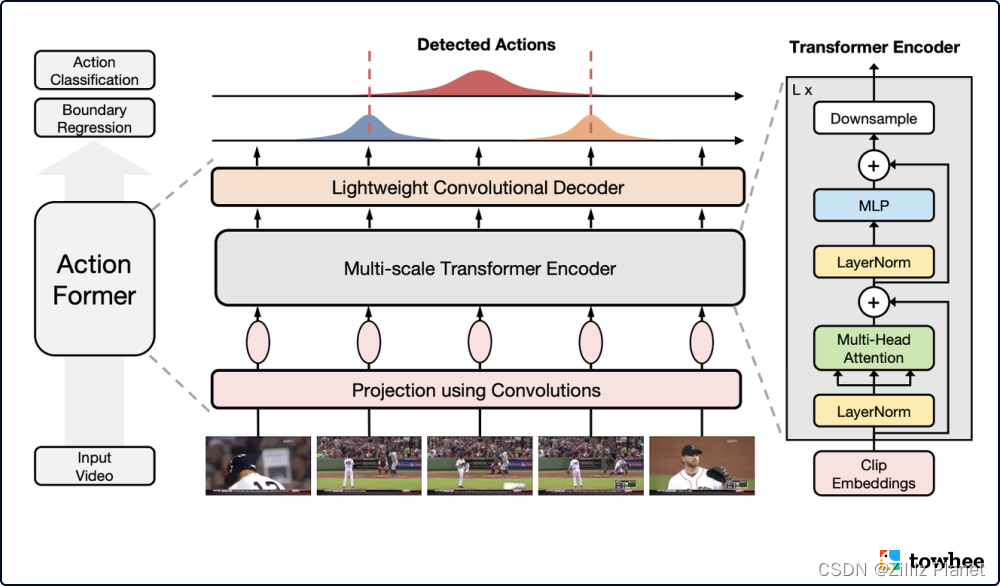
ActionFormer 的基本思想很简单,将长视频中的每一帧都当作 action candidate,然后做分类和回归任务。通过分类得到动作类别,回归得到和动作边界的距离。该模型架构主要由以下部分组成:用于特征提取的骨干网络、用于投影的浅层卷积、堆叠数层 Transformer 模块组成的编码器、利用卷积神经网络的解码器。
相关资料:
-
模型代码:GitHub - happyharrycn/actionformer_release: Code release for ActionFormer
-
论文:ActionFormer: Localizing Moments of Actions with Transformer
-
更多资料:论文阅读笔记:ActionFormer: Localizing Moments of Actions with Transformers - 知乎
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些鼓励:点赞、喜欢或者分享给你的小伙伴!
活动信息、技术分享和招聘速递请关注:你好????,数据探索者 https://zilliz.gitee.io/welcome/
https://zilliz.gitee.io/welcome/
如果你对我们的项目感兴趣请关注:
用于存储向量并创建索引的数据库 Milvus
用于构建模型推理流水线的框架 Towhee
最后
以上就是腼腆背包最近收集整理的关于2022 全球 AI 模型周报的全部内容,更多相关2022内容请搜索靠谱客的其他文章。








发表评论 取消回复