上篇:第5章 Hive数据操作—DML数据操作
做一个简单的查询测试
(1)首先把一个dept表清空,清空这个表必须是内部表,外部表是无法清空的,执行命令如下:
无法清空,说明是外部表:
hive (default)> truncate table dept;
FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table dept.
hive (default)>
我们需要把dept表把外部表改成内部表,执行命令如下:
hive (default)> alter table dept set tblproperties('EXTERNAL'='FALSE');
OK
Time taken: 0.635 seconds
hive (default)>
接下来,再次清空dept表就可以,执行命令如下:
hive (default)> truncate table dept;
OK
Time taken: 0.325 seconds
hive (default)>
当清空成功之后,我们再次查询dept这张表是否还有数据
hive (default)> select * from dept;
OK
dept.deptno dept.dname dept.loc
Time taken: 0.707 seconds
hive (default)>
发现dept表,已经没有数据了
接下来,我们就可以在dept下的表,加载一些数据进去
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/dept.txt' into table dept;
Loading data to table default.dept
Table default.dept stats: [numFiles=1, numRows=0, totalSize=69, rawDataSize=0]
OK
Time taken: 2.245 seconds
hive (default)>
当加载一些数据进去之后,再次查询dept表的数据
hive (default)> select * from dept;
OK
dept.deptno dept.dname dept.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.142 seconds, Fetched: 4 row(s)
hive (default)>
说明已经有数据了
1、查询
官方地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
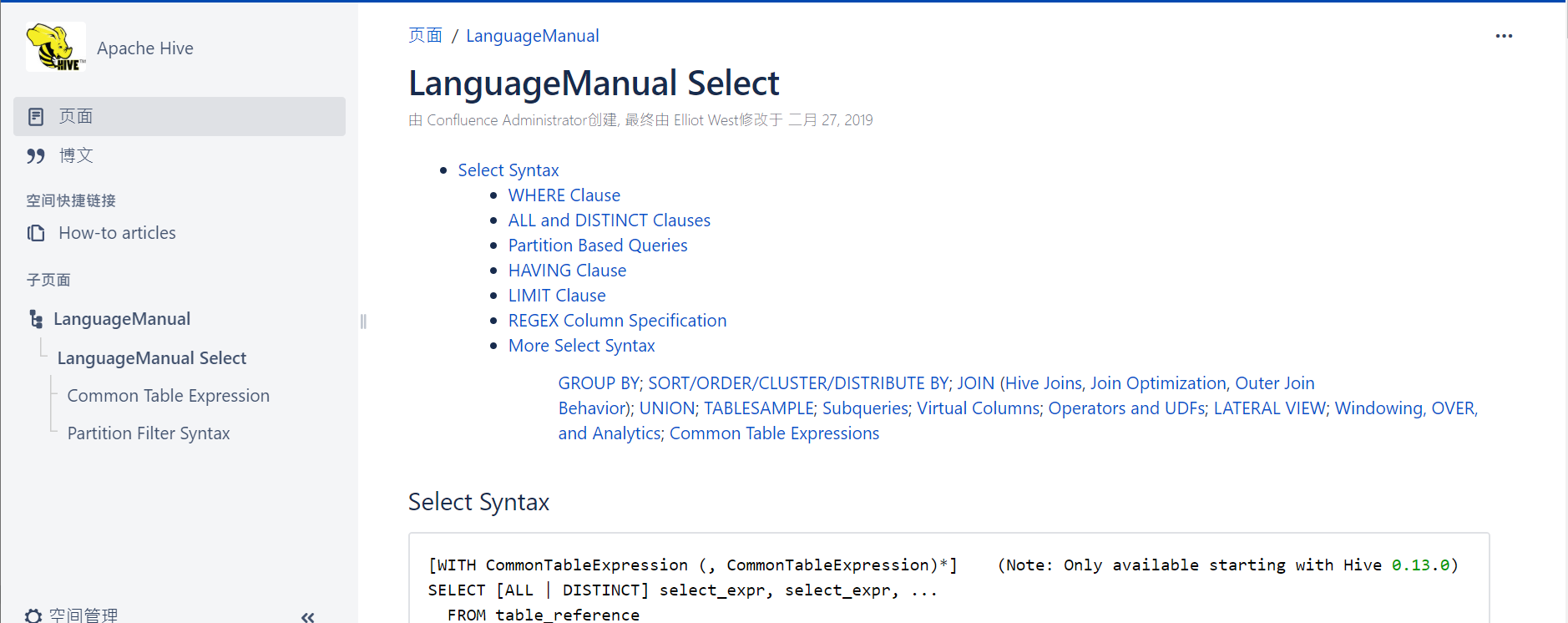
查询语句语法:
[WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available
starting with Hive 0.13.0)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
1.1 基本查询(Select…From)
1.1.1全表和特定列查询
(1)全表查询
hive (default)> select * from emp;
(2)选择特定列查询
hive (default)> select empno, ename from emp;
注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。
1.2 列别名
(1)重命名一个列
(2)便于计算
(3)紧跟列名,也可以在列名和别名之间加入关键字‘AS’
(4)案例实操
查询名称和部门
hive (default)> select ename AS name, deptno dn from emp;
1.3 算术运算符
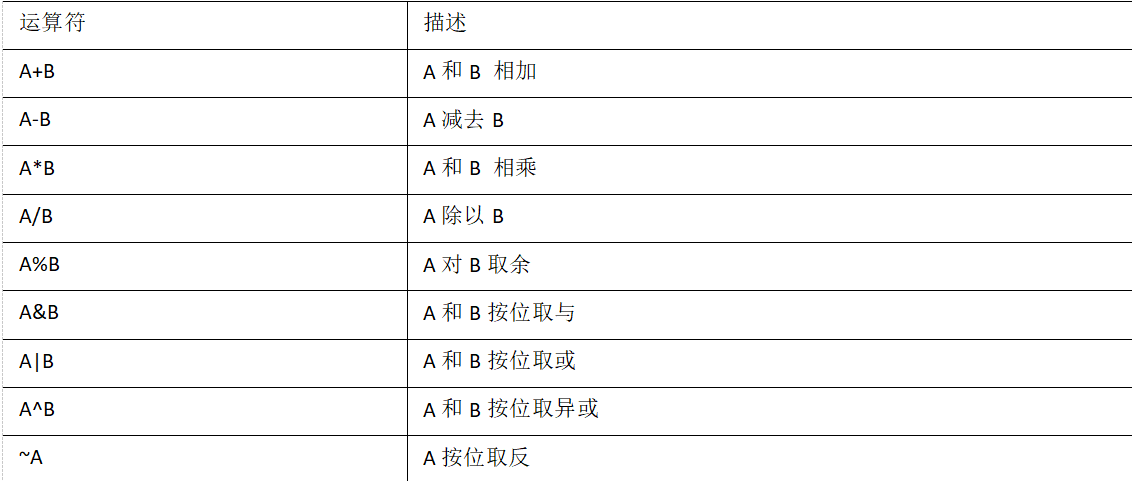
案例实操
查询出所有员工的薪水后加1显示(sal_1:添加名称)
hive (default)> select sal +1 sal_1 from emp;
OK
sal_1
801.0
1601.0
1251.0
2976.0
1251.0
2851.0
2451.0
3001.0
5001.0
1501.0
1101.0
951.0
3001.0
1301.0
Time taken: 0.284 seconds, Fetched: 14 row(s)
hive (default)>
1.4 常用函数
(1)求总行数(count)
hive (default)> select count(*) from emp;
.....
OK
_c0
14
Time taken: 45.924 seconds, Fetched: 1 row(s)
hive (default)>
了解一下,面试问过
count(1)、count(*)、count(column(列))这三者的区别?
(2)求工资的最大值(max)
hive (default)> select max(sal) from emp;
....
OK
_c0
5000.0
Time taken: 38.153 seconds, Fetched: 1 row(s)
hive (default)>
(3)求工资的最小值(min)
hive (default)> select min(sal) from emp;
....
OK
_c0
800.0
Time taken: 33.707 seconds, Fetched: 1 row(s)
hive (default)>
(4)求工资的平均值(avg)
hive (default)> select avg(sal) from emp;
....
OK
_c0
2073.214285714286
Time taken: 32.588 seconds, Fetched: 1 row(s)
hive (default)>
(5)求工资的总和(sum)
hive (default)> select sum(sal) from emp;
......
OK
_c0
29025.0
Time taken: 37.091 seconds, Fetched: 1 row(s)
hive (default)>
1.5、 Limit语句
典型的查询会返回多行数据。LIMIT子句用于限制返回的行数。
hive (default)> select * from emp limit 5;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
Time taken: 0.137 seconds, Fetched: 5 row(s)
hive (default)>
2、 Where子查询
(1)使用WHERE子句,将不满足条件的行过滤掉
(2)WHERE子句紧随FROM子句
(3)案例实操
如:
查询出薪水大于2000的所有员工
hive (default)> select * from emp where sal >2000;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
Time taken: 0.315 seconds, Fetched: 6 row(s)
hive (default)>
2.1 比较运算符(Between/In/ Is Null)
1)下面表中描述了谓词操作符,这些操作符同样可以用于JOIN…ON和HAVING语句中。
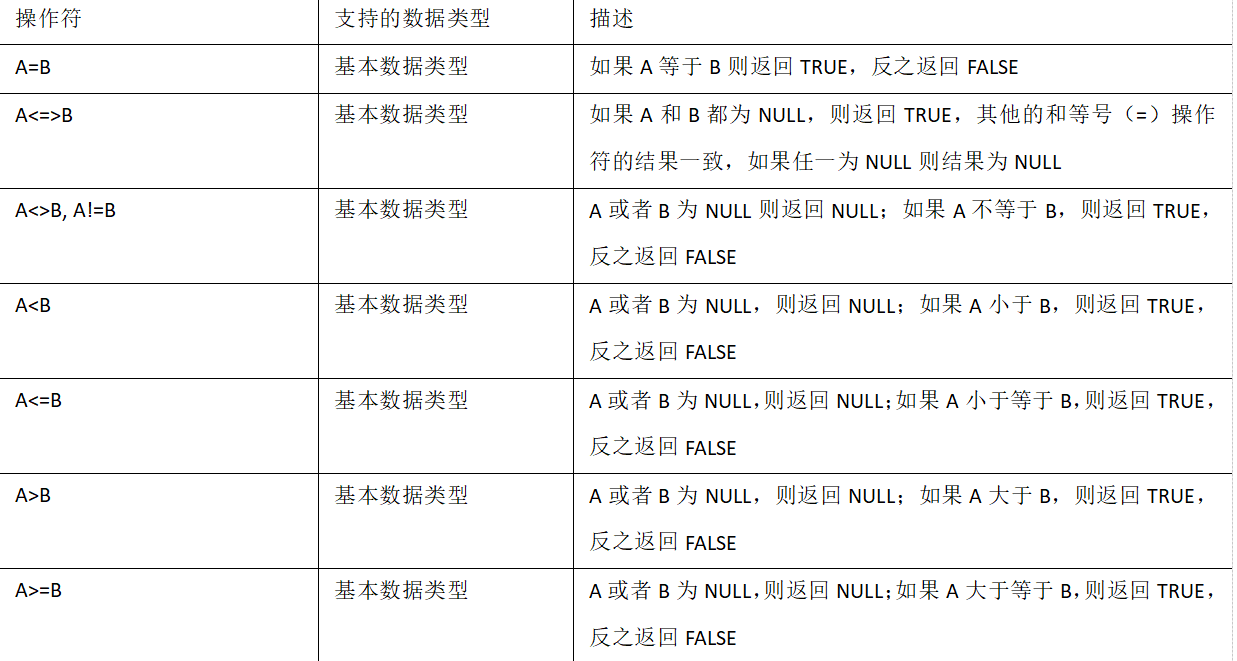
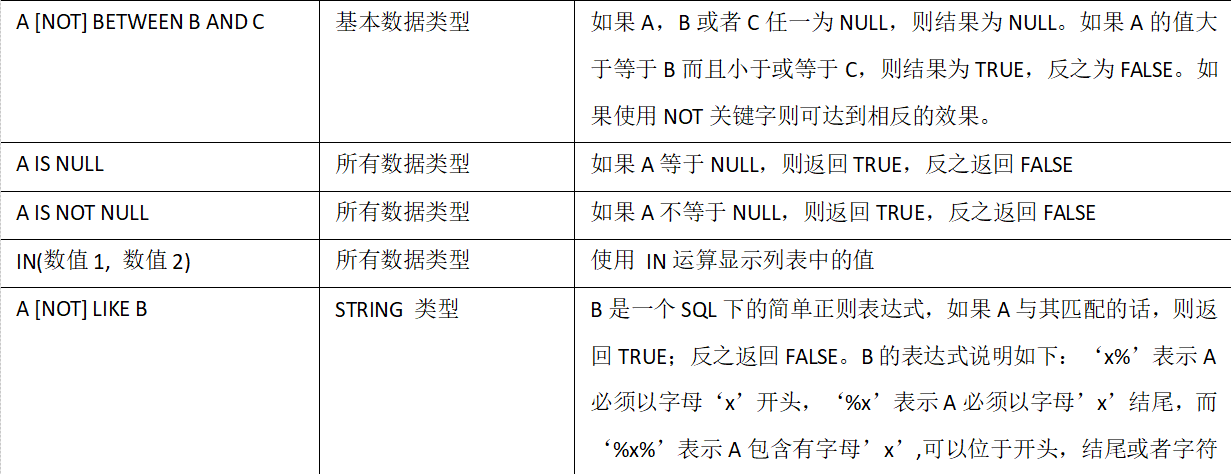
2)案例实操
(1)查询出薪水等于5000的所有员工
hive (default)> select * from emp where sal =5000;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
Time taken: 0.151 seconds, Fetched: 1 row(s)
hive (default)>
(2)查询工资在500到1000的员工信息
hive (default)> select * from emp where sal between 500 and 1000;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
Time taken: 0.128 seconds, Fetched: 2 row(s)
hive (default)>
(3)查询comm为空的所有员工信息
hive (default)> select * from emp where comm is null;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.124 seconds, Fetched: 10 row(s)
hive (default)>
(4)查询工资是1500或5000的员工信息
hive (default)> select * from emp where sal IN (1500, 5000);
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
Time taken: 0.107 seconds, Fetched: 2 row(s)
hive (default)>
(5)查询薪水以2开头的
hive (default)> select * from emp where sal like '2%';
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
Time taken: 0.11 seconds, Fetched: 3 row(s)
hive (default)>
(6)查询第二个数字为2的薪水数字
hive (default)> select * from emp where sal like '_2%';
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
Time taken: 0.101 seconds, Fetched: 2 row(s)
hive (default)>
(7)查询薪水包含2的数字,可以采用正则表达式
hive (default)> select sal from emp where sal rlike '[2]';
OK
sal
1250.0
2975.0
1250.0
2850.0
2450.0
Time taken: 0.143 seconds, Fetched: 5 row(s)
hive (default)>
2.2 逻辑运算符(And/Or/Not)

案例实操
(1)查询薪水大于1000,部门是30
hive (default)> select * from emp where sal>1000 and deptno=30;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
Time taken: 0.091 seconds, Fetched: 5 row(s)
hive (default)>
(2)查询薪水大于1000,或者部门是30
hive (default)> select * from emp where sal>1000 or deptno=30;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.127 seconds, Fetched: 13 row(s)
hive (default)>
(3)查询除了20部门和30部门以外的员工信息
hive (default)> select * from emp where deptno not IN(30, 20);
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.101 seconds, Fetched: 3 row(s)
hive (default)>
3、 分组
2.3.1 Group By语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
案例实操:
(1)计算emp表每个部门的平均工资
hive (default)> select avg(sal)avg_sal from emp
> group by deptno;
.......
OK
avg_sal
2916.6666666666665
2175.0
1566.6666666666667
Time taken: 34.524 seconds, Fetched: 3 row(s)
hive (default)>
(2)计算emp每个部门中每个岗位的最高薪水
hive (default)> select deptno,job,avg(sal)avg_sal from emp
> group by deptno,job;
......
OK
deptno job avg_sal
10 CLERK 1300.0
10 MANAGER 2450.0
10 PRESIDENT 5000.0
20 ANALYST 3000.0
20 CLERK 950.0
20 MANAGER 2975.0
30 CLERK 950.0
30 MANAGER 2850.0
30 SALESMAN 1400.0
Time taken: 31.764 seconds, Fetched: 9 row(s)
hive (default)>
(3) 求每个部门的平均薪水大于2000的部门
hive (default)> select deptno,avg(sal)avg_sal from emp
> group by deptno
> having avg_sal > 2000;
......
OK
deptno avg_sal
10 2916.6666666666665
20 2175.0
Time taken: 37.298 seconds, Fetched: 2 row(s)
hive (default)>
having与where不同点
(1)where针对表中的列发挥作用,查询数据;having针对查询结果中的列发挥作用,筛选数据。
(2)where后面不能写分组函数,而having后面可以使用分组函数。
(3)having只用于group by分组统计语句。
4、 Join语句
4.1 等值Join
Hive支持通常的SQL JOIN语句,但是只支持等值连接,不支持非等值连接。
4.2 案例实操
(1)根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
hive (default)> select e.empno, e.ename,d.dname
> from emp e join dept d
> on e.deptno=d.deptno;
.....
OK
e.empno e.ename d.dname
7369 SMITH RESEARCH
7499 ALLEN SALES
7521 WARD SALES
7566 JONES RESEARCH
7654 MARTIN SALES
7698 BLAKE SALES
7782 CLARK ACCOUNTING
7788 SCOTT RESEARCH
7839 KING ACCOUNTING
7844 TURNER SALES
7876 ADAMS RESEARCH
7900 JAMES SALES
7902 FORD RESEARCH
7934 MILLER ACCOUNTING
Time taken: 36.229 seconds, Fetched: 14 row(s)
hive (default)>
4.3 表的别名
好处:
(1)使用别名可以简化查询。
(2)使用表名前缀可以提高执行效率。
案例实操
(1) 合并员工表和部门表
hive (default)> select e.empno, e.ename, d.deptno from emp
> e join dept d on e.deptno
> = d.deptno;
....
OK
e.empno e.ename d.deptno
7369 SMITH 20
7499 ALLEN 30
7521 WARD 30
7566 JONES 20
7654 MARTIN 30
7698 BLAKE 30
7782 CLARK 10
7788 SCOTT 20
7839 KING 10
7844 TURNER 30
7876 ADAMS 20
7900 JAMES 30
7902 FORD 20
7934 MILLER 10
Time taken: 35.142 seconds, Fetched: 14 row(s)
hive (default)>
4.4、 内连接
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
hive (default)> select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno
> = d.deptno;
4.5、 左外连接
左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
hive (default)> select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno
> = d.deptno;
.....
OK
e.empno e.ename d.deptno
7369 SMITH 20
7499 ALLEN 30
7521 WARD 30
7566 JONES 20
7654 MARTIN 30
7698 BLAKE 30
7782 CLARK 10
7788 SCOTT 20
7839 KING 10
7844 TURNER 30
7876 ADAMS 20
7900 JAMES 30
7902 FORD 20
7934 MILLER 10
Time taken: 35.313 seconds, Fetched: 14 row(s)
hive (default)>
4.6、 右外连接
右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。
hive (default)> select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno
> = d.deptno;
....
OK
e.empno e.ename d.deptno
7782 CLARK 10
7839 KING 10
7934 MILLER 10
7369 SMITH 20
7566 JONES 20
7788 SCOTT 20
7876 ADAMS 20
7902 FORD 20
7499 ALLEN 30
7521 WARD 30
7654 MARTIN 30
7698 BLAKE 30
7844 TURNER 30
7900 JAMES 30
NULL NULL 40
Time taken: 32.33 seconds, Fetched: 15 row(s)
hive (default)>
4.7、满外连接
满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
hive (default)> select e.empno, e.ename, d.dname from emp e
> full join dept d
> on e.deptno=d.deptno;
....
OK
e.empno e.ename d.dname
7934 MILLER ACCOUNTING
7839 KING ACCOUNTING
7782 CLARK ACCOUNTING
7876 ADAMS RESEARCH
7788 SCOTT RESEARCH
7369 SMITH RESEARCH
7566 JONES RESEARCH
7902 FORD RESEARCH
7844 TURNER SALES
7499 ALLEN SALES
7698 BLAKE SALES
7654 MARTIN SALES
7521 WARD SALES
7900 JAMES SALES
NULL NULL OPERATIONS
Time taken: 43.97 seconds, Fetched: 15 row(s)
hive (default)>
4.8、多表连接
注意:连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
操作步骤:
(1)数据准备,在/usr/local/hadoop/module/datas目录下创建一个location.txt文本
[root@hadoop101 datas]# pwd
/usr/local/hadoop/module/datas
[root@hadoop101 datas]# vim location.txt
1700 Beijing
1800 London
1900 Tokyo
保存退出!
(2)创建位置表
hive (default)> create table if not exists default.location(
> loc int,
> loc_name string
> )
> row format delimited fields terminated by 't';
OK
Time taken: 0.648 seconds
hive (default)>
(3)导入数据
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/location.txt'
> into table location;
Loading data to table default.location
Table default.location stats: [numFiles=1, totalSize=36]
OK
Time taken: 0.377 seconds
hive (default)>
(4) 查看这个数据表location,数据信息
hive (default)> select * from location;
OK
location.loc location.loc_name
1700 Beijing
1800 London
1900 Tokyo
Time taken: 0.096 seconds, Fetched: 3 row(s)
hive (default)>
(5)多表连接查询
hive (default)> SELECT e.ename, d.deptno, l.loc_name
> FROM emp e
> JOIN dept d
> ON d.deptno = e.deptno
> JOIN location l
> ON d.loc = l.loc;
......
OK
e.ename d.deptno l.loc_name
SMITH 20 London
ALLEN 30 Tokyo
WARD 30 Tokyo
JONES 20 London
MARTIN 30 Tokyo
BLAKE 30 Tokyo
CLARK 10 Beijing
SCOTT 20 London
KING 10 Beijing
TURNER 30 Tokyo
ADAMS 20 London
JAMES 30 Tokyo
FORD 20 London
MILLER 10 Beijing
Time taken: 38.904 seconds, Fetched: 14 row(s)
hive (default)>
大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表e和表d进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表l;进行连接操作。
注意:为什么不是表d和表l先进行连接操作呢?这是因为Hive总是按照从左到右的顺序执行的。
笛卡尔积
1.笛卡尔集会在下面条件下产生
(1)省略连接条件
(2)连接条件无效
(3)所有表中的所有行互相连接
案例实操
hive (default)> select empno, dname from emp, dept;
.....
OK
empno dname
7369 ACCOUNTING
7369 RESEARCH
7369 SALES
7369 OPERATIONS
7499 ACCOUNTING
7499 RESEARCH
7499 SALES
7499 OPERATIONS
7521 ACCOUNTING
7521 RESEARCH
7521 SALES
7521 OPERATIONS
7566 ACCOUNTING
7566 RESEARCH
7566 SALES
7566 OPERATIONS
7654 ACCOUNTING
7654 RESEARCH
7654 SALES
7654 OPERATIONS
7698 ACCOUNTING
7698 RESEARCH
7698 SALES
7698 OPERATIONS
7782 ACCOUNTING
7782 RESEARCH
7782 SALES
7782 OPERATIONS
7788 ACCOUNTING
7788 RESEARCH
7788 SALES
7788 OPERATIONS
7839 ACCOUNTING
7839 RESEARCH
7839 SALES
7839 OPERATIONS
7844 ACCOUNTING
7844 RESEARCH
7844 SALES
7844 OPERATIONS
7876 ACCOUNTING
7876 RESEARCH
7876 SALES
7876 OPERATIONS
7900 ACCOUNTING
7900 RESEARCH
7900 SALES
7900 OPERATIONS
7902 ACCOUNTING
7902 RESEARCH
7902 SALES
7902 OPERATIONS
7934 ACCOUNTING
7934 RESEARCH
7934 SALES
7934 OPERATIONS
Time taken: 35.072 seconds, Fetched: 56 row(s)
hive (default)>
连接谓词中不支持or
hive (default)> select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno
= d.deptno or e.ename=d.ename; 错误的
5、 排序
5.1 全局排序(Order By)
Order By:全局排序,一个Reducer
1.使用 ORDER BY 子句排序
ASC(ascend): 升序(默认)
DESC(descend): 降序
2.ORDER BY 子句在SELECT语句的结尾
3.案例实操
(1)查询员工信息按工资升序排列
hive (default)> select * from emp order by sal;
...
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
Time taken: 35.444 seconds, Fetched: 14 row(s)
hive (default)>
(2)查询员工信息按工资降序排列
hive (default)> select * from emp order by sal desc;
...
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
Time taken: 29.34 seconds, Fetched: 14 row(s)
hive (default)>
5.2、按照别名排序
按照员工薪水的2倍排序
hive (default)> select ename, sal*2 twosal
> from emp order by twosal;
...
OK
ename twosal
SMITH 1600.0
JAMES 1900.0
ADAMS 2200.0
WARD 2500.0
MARTIN 2500.0
MILLER 2600.0
TURNER 3000.0
ALLEN 3200.0
CLARK 4900.0
BLAKE 5700.0
JONES 5950.0
SCOTT 6000.0
FORD 6000.0
KING 10000.0
Time taken: 38.358 seconds, Fetched: 14 row(s)
hive (default)>
从上面排序得出,每排序一个都会加上1600
5.3 、多个列排序
按照部门和工资升序排序
hive (default)> select ename, deptno, sal
> from emp order
> by deptno, sal;
...
OK
ename deptno sal
MILLER 10 1300.0
CLARK 10 2450.0
KING 10 5000.0
SMITH 20 800.0
ADAMS 20 1100.0
JONES 20 2975.0
SCOTT 20 3000.0
FORD 20 3000.0
JAMES 30 950.0
MARTIN 30 1250.0
WARD 30 1250.0
TURNER 30 1500.0
ALLEN 30 1600.0
BLAKE 30 2850.0
Time taken: 39.124 seconds, Fetched: 14 row(s)
hive (default)>
5.4、 每个MapReduce内部排序(Sort By)
Sort By:每个Reducer内部进行排序,对全局结果集来说不是排序。
(1)查看设置reduce个数
hive (default)> set mapreduce.job.reduces;
mapreduce.job.reduces=-1
hive (default)>
(2)设置reduce个数
hive (default)> set mapreduce.job.reduces=3;
hive (default)>
(3)根据部门编号降序查看员工信息
hive (default)> select * from emp sort by empno desc;
.......
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
Time taken: 53.566 seconds, Fetched: 14 row(s)
hive (default)>
(4)将查询结果导入到文件中(按照部门编号降序排序)
hive (default)> insert overwrite local directory '/usr/local/hadoop/module/datas/sortby-result'
> select * from emp sort by sal;
.......
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 57.465 seconds
hive (default)>
当这个命令执行完毕之后,我们在/usr/local/hadoop/module/datas目录下查看文件,会发现多了一个sortby-result文件夹
[root@hadoop101 datas]# pwd
/usr/local/hadoop/module/datas
[root@hadoop101 datas]# ll
total 28
-rw-r--r-- 1 root root 69 Dec 31 01:59 dept.txt
-rw-r--r-- 1 root root 657 Dec 31 02:07 emp.txt
-rw-r--r-- 1 root root 23 Dec 30 02:42 hivef.sql
-rw-r--r-- 1 root root 54 Dec 30 02:49 hive_result.txt
-rw-r--r-- 1 root root 36 Jan 3 16:25 location.txt
drwxr-xr-x 3 root root 189 Jan 3 17:48 sortby-result
drwxr-xr-x 3 root root 115 Jan 2 23:01 stu1
-rw-r--r-- 1 root root 39 Dec 29 17:36 student.txt
-rw-r--r-- 1 root root 144 Dec 30 16:21 test.txt
[root@hadoop101 datas]#
查看sortby-result文件夹的数据
[root@hadoop101 datas]# cd sortby-result/
[root@hadoop101 sortby-result]# ll
total 12
-rw-r--r-- 1 root root 288 Jan 3 17:48 000000_0
-rw-r--r-- 1 root root 282 Jan 3 17:48 000001_0
-rw-r--r-- 1 root root 91 Jan 3 17:48 000002_0
[root@hadoop101 sortby-result]#
查看000000_0、000001_0、000002_0的数据信息
[root@hadoop101 sortby-result]# cat 000000_0
7654MARTINSALESMAN76981981-9-281250.01400.030
7844TURNERSALESMAN76981981-9-81500.00.030
7782CLARKMANAGER78391981-6-92450.0N10
7698BLAKEMANAGER78391981-5-12850.0N30
7788SCOTTANALYST75661987-4-193000.0N20
7839KINGPRESIDENTN1981-11-175000.0N10
[root@hadoop101 sortby-result]# cat 000001_0
7900JAMESCLERK76981981-12-3950.0N30
7876ADAMSCLERK77881987-5-231100.0N20
7521WARDSALESMAN76981981-2-221250.0500.030
7934MILLERCLERK77821982-1-231300.0N10
7499ALLENSALESMAN76981981-2-201600.0300.030
7566JONESMANAGER78391981-4-22975.0N20
[root@hadoop101 sortby-result]# cat 000002_0
7369SMITHCLERK79021980-12-17800.0N20
7902FORDANALYST75661981-12-33000.0N20
[root@hadoop101 sortby-result]#
之后,我们再同样执行操作,在/usr/local/hadoop/module/datas目录下查看文件,会发现多了一个order-result文件夹
hive (default)> insert overwrite local directory '/usr/local/hadoop/module/datas/order-result'
> select * from emp order by sal;
....
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 36.627 seconds
hive (default)>
[root@hadoop101 datas]# ll
total 28
-rw-r--r-- 1 root root 69 Dec 31 01:59 dept.txt
-rw-r--r-- 1 root root 657 Dec 31 02:07 emp.txt
-rw-r--r-- 1 root root 23 Dec 30 02:42 hivef.sql
-rw-r--r-- 1 root root 54 Dec 30 02:49 hive_result.txt
-rw-r--r-- 1 root root 36 Jan 3 16:25 location.txt
drwxr-xr-x 3 root root 115 Jan 3 17:57 order-result
drwxr-xr-x 3 root root 189 Jan 3 17:48 sortby-result
drwxr-xr-x 3 root root 115 Jan 2 23:01 stu1
-rw-r--r-- 1 root root 39 Dec 29 17:36 student.txt
-rw-r--r-- 1 root root 144 Dec 30 16:21 test.txt
[root@hadoop101 datas]#
加载过程:
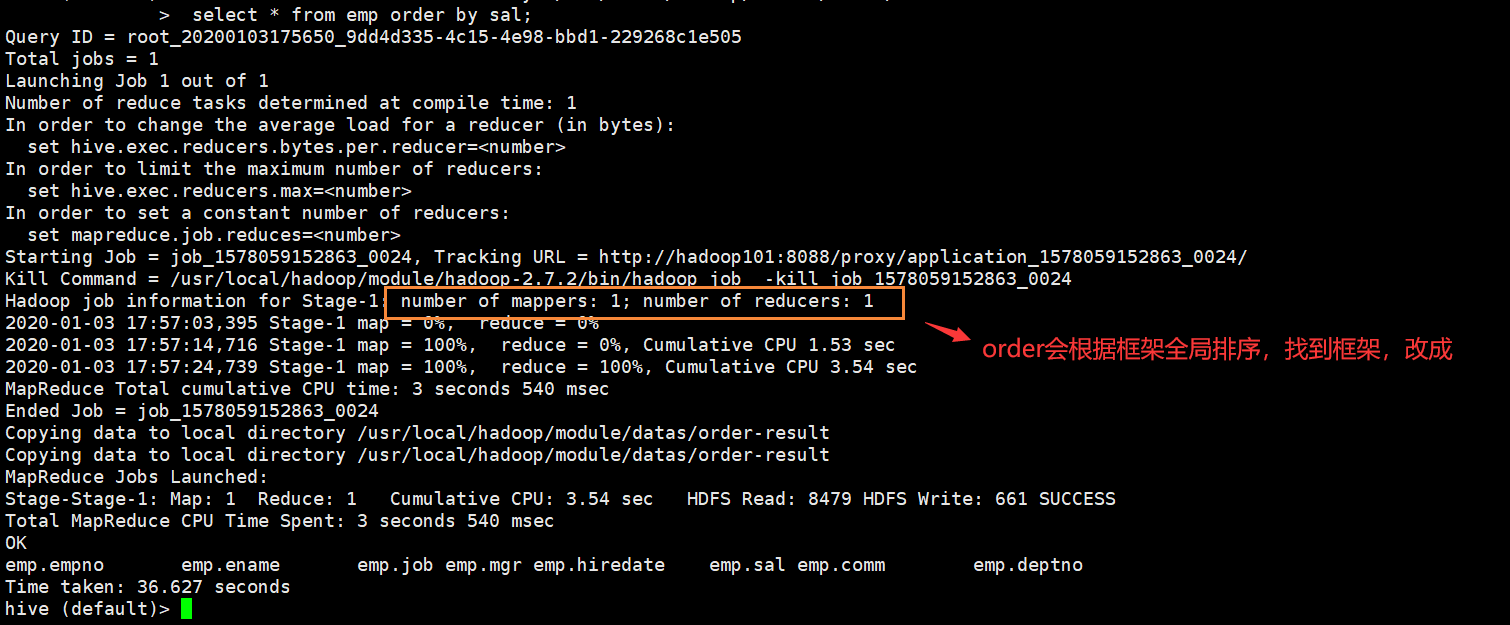
查看order-result文件夹下的数据
[root@hadoop101 order-result]# ll
total 4
-rw-r--r-- 1 root root 661 Jan 3 17:57 000000_0
[root@hadoop101 order-result]#
[root@hadoop101 order-result]# cat 000000_0
7369SMITHCLERK79021980-12-17800.0N20
7900JAMESCLERK76981981-12-3950.0N30
7876ADAMSCLERK77881987-5-231100.0N20
7521WARDSALESMAN76981981-2-221250.0500.030
7654MARTINSALESMAN76981981-9-281250.01400.030
7934MILLERCLERK77821982-1-231300.0N10
7844TURNERSALESMAN76981981-9-81500.00.030
7499ALLENSALESMAN76981981-2-201600.0300.030
7782CLARKMANAGER78391981-6-92450.0N10
7698BLAKEMANAGER78391981-5-12850.0N30
7566JONESMANAGER78391981-4-22975.0N20
7788SCOTTANALYST75661987-4-193000.0N20
7902FORDANALYST75661981-12-33000.0N20
7839KINGPRESIDENTN1981-11-175000.0N10
[root@hadoop101 order-result]#
5.5 分区排序(Distribute By)
Distribute By:类似MR中partition,进行分区,结合sort by使用。
注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
案例实操:
(1)先按照部门编号分区,再按照员工编号降序排序。
hive (default)> insert overwrite local directory '/usr/local/hadoop/module/datas/distribute-result'
> select * from emp distribute by deptno sort by sal;
....
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 55.914 seconds
hive (default)>
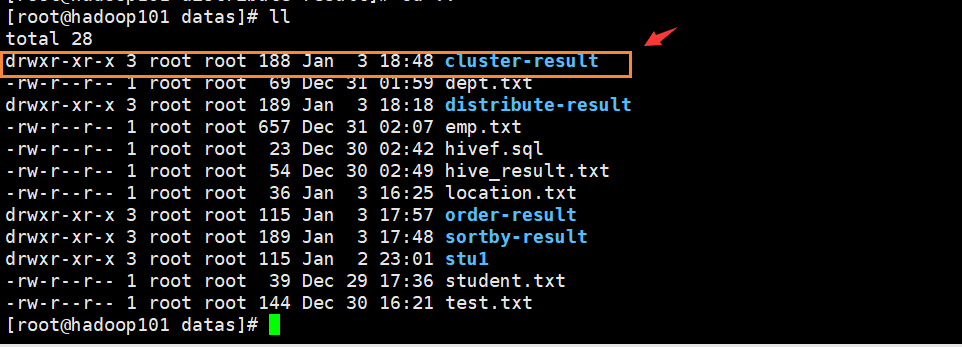
在/usr/local/hadoop/module/datas目录下查看文件,会发现多了一个distribute-result文件夹
[root@hadoop101 datas]# ll
total 28
-rw-r--r-- 1 root root 69 Dec 31 01:59 dept.txt
drwxr-xr-x 3 root root 189 Jan 3 18:18 distribute-result
-rw-r--r-- 1 root root 657 Dec 31 02:07 emp.txt
-rw-r--r-- 1 root root 23 Dec 30 02:42 hivef.sql
-rw-r--r-- 1 root root 54 Dec 30 02:49 hive_result.txt
-rw-r--r-- 1 root root 36 Jan 3 16:25 location.txt
drwxr-xr-x 3 root root 115 Jan 3 17:57 order-result
drwxr-xr-x 3 root root 189 Jan 3 17:48 sortby-result
drwxr-xr-x 3 root root 115 Jan 2 23:01 stu1
-rw-r--r-- 1 root root 39 Dec 29 17:36 student.txt
-rw-r--r-- 1 root root 144 Dec 30 16:21 test.txt
[root@hadoop101 datas]#
查看这个distribute-result文件夹的数据信息
[root@hadoop101 datas]# cd distribute-result/
[root@hadoop101 distribute-result]# ll
total 12
-rw-r--r-- 1 root root 293 Jan 3 18:18 000000_0
-rw-r--r-- 1 root root 139 Jan 3 18:18 000001_0
-rw-r--r-- 1 root root 229 Jan 3 18:18 000002_0
[root@hadoop101 distribute-result]#
[root@hadoop101 distribute-result]# cat 000000_0
7900JAMESCLERK76981981-12-3950.0N30
7521WARDSALESMAN76981981-2-221250.0500.030
7654MARTINSALESMAN76981981-9-281250.01400.030
7844TURNERSALESMAN76981981-9-81500.00.030
7499ALLENSALESMAN76981981-2-201600.0300.030
7698BLAKEMANAGER78391981-5-12850.0N30
[root@hadoop101 distribute-result]#
[root@hadoop101 distribute-result]# cat 000001_0
7934MILLERCLERK77821982-1-231300.0N10
7782CLARKMANAGER78391981-6-92450.0N10
7839KINGPRESIDENTN1981-11-175000.0N10
[root@hadoop101 distribute-result]#
[root@hadoop101 distribute-result]# cat 000002_0
7369SMITHCLERK79021980-12-17800.0N20
7876ADAMSCLERK77881987-5-231100.0N20
7566JONESMANAGER78391981-4-22975.0N20
7788SCOTTANALYST75661987-4-193000.0N20
7902FORDANALYST75661981-12-33000.0N20
[root@hadoop101 distribute-result]#
分区排序,必须设置为:
set mapreduce.job.reduces=3;
5.6、Cluster By
当distribute by和sorts by字段相同时,可以使 用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
1)以下两种写法等价
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
分区查询,生成一个cluster-result文件,也是三个数据
hive (default)> insert overwrite local directory '/usr/local/hadoop/module/datas/cluster-result'
> select * from emp cluster by deptno;
....
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 56.335 seconds
hive (default)>
[root@hadoop101 datas]# cd cluster-result/
[root@hadoop101 cluster-result]# ll
total 12
-rw-r--r-- 1 root root 293 Jan 3 18:48 000000_0
-rw-r--r-- 1 root root 139 Jan 3 18:48 000001_0
-rw-r--r-- 1 root root 229 Jan 3 18:48 000002_0
[root@hadoop101 cluster-result]#
里面是数据是按部门排序
[root@hadoop101 cluster-result]# cat 000000_0
7654MARTINSALESMAN76981981-9-281250.01400.030
7900JAMESCLERK76981981-12-3950.0N30
7698BLAKEMANAGER78391981-5-12850.0N30
7521WARDSALESMAN76981981-2-221250.0500.030
7844TURNERSALESMAN76981981-9-81500.00.030
7499ALLENSALESMAN76981981-2-201600.0300.030
[root@hadoop101 cluster-result]# cat 000001_0
7934MILLERCLERK77821982-1-231300.0N10
7839KINGPRESIDENTN1981-11-175000.0N10
7782CLARKMANAGER78391981-6-92450.0N10
[root@hadoop101 cluster-result]# cat 000002_0
7788SCOTTANALYST75661987-4-193000.0N20
7566JONESMANAGER78391981-4-22975.0N20
7876ADAMSCLERK77881987-5-231100.0N20
7902FORDANALYST75661981-12-33000.0N20
7369SMITHCLERK79021980-12-17800.0N20
[root@hadoop101 cluster-result]#
5.7 分桶及抽样查询
5.7.1 分桶表数据存储
分区针对的是数据的存储路径;分桶针对的是数据文件。
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是之前所提到过的要确定合适的划分大小这个疑虑。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
操作步骤:
先创建分桶表,通过直接导入数据文件的方式
(1)创建分桶表
hive (default)> create table stu_buck(id int, name string)
> clustered by(id)
> into 4 buckets
> row format delimited fields terminated by 't';
OK
Time taken: 1.883 seconds
hive (default)>
在HDFS文件系统查看,被创建出来了
创建出来这个表是空文件数据,我们许需要做的事加载数据到这个表上
(2)准备数据,在/usr/local/hadoop/module/datas目录下新建一个 stu_buck文本,执行如下:
[root@hadoop101 hadoop-2.7.2]# cd /usr/local/hadoop/module/datas/
[root@hadoop101 datas]# vim stu_buck
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
保存退出!
(3)导入数据到分桶表中
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/stu_buck.txt'
> into table stu_buck;
Loading data to table default.stu_buck
Table default.stu_buck stats: [numFiles=1, totalSize=151]
OK
Time taken: 1.727 seconds
hive (default)>
检验,查询stu_buck表的数据
hive (default)> select * from stu_buck;
OK
stu_buck.id stu_buck.name
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
Time taken: 0.621 seconds, Fetched: 16 row(s)
hive (default)>
由上,说明stu_buck表由数据,成功导入ok
我们在HDFS文件系统查看,有数据了:

由上查看还是只有一条数据,发现并没有分成4个桶
我们可以换另一种方式:
首先,把stu_buck表清空
hive (default)> truncate table stu_buck;
OK
Time taken: 0.396 seconds
hive (default)>
查看这个stu_buck表数据是否还有?
hive (default)> select * from stu_buck;
OK
stu_buck.id stu_buck.name
Time taken: 0.135 seconds
hive (default)>

以上,说明已经清空了stu_buck表的数据
创建分桶表时,数据通过子查询的方式导入:
(1)先建一个普通的stu表
hive (default)> create table stu(id int, name string)
> row format delimited fields terminated by 't';
OK
Time taken: 0.187 seconds
hive (default)>
(2)向普通的stu表中导入数据
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/stu_buck.txt'
> into table stu;
Loading data to table default.stu
Table default.stu stats: [numFiles=1, totalSize=151]
OK
Time taken: 0.502 seconds
hive (default)>
检验,查询stu表的数据
hive (default)> select * from stu;
OK
stu.id stu.name
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
Time taken: 0.129 seconds, Fetched: 16 row(s)
hive (default)>
(3)导入数据到分桶表
hive (default)> insert into table stu_buck
> select * from stu;
.........
.........
OK
stu.id stu.name
Time taken: 39.359 seconds
hive (default)>
发现还是只有一个分桶
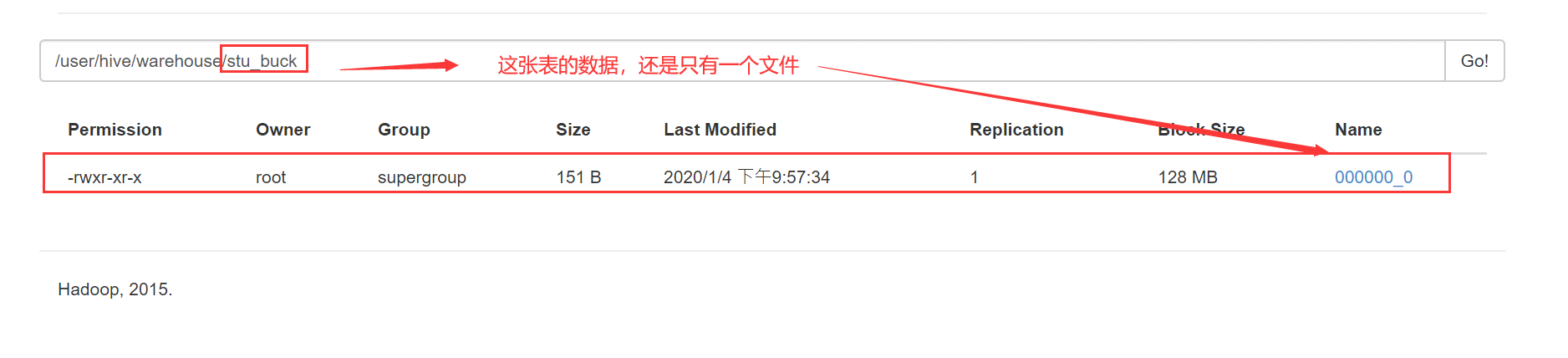
(4)需要设置一个属性
hive (default)> set hive.enforce.bucketing;
hive.enforce.bucketing=false
hive (default)>
由上,hive.enforce.bucketing=false,我们需要改成true,执行命令:
hive (default)> set hive.enforce.bucketing=true;
hive (default)> set mapreduce.job.reduces=-1;
hive (default)>
(5)接下来我们需要对表插入数据,注意的是:在插入这张表的数据前,需要**清空这张表的数据**
清空stu_buck表数据:
hive (default)> truncate table stu_buck;
OK
Time taken: 0.213 seconds
hive (default)>
插入stu_buck表数据:
hive (default)> insert into table stu_buck
> select * from stu;
........
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 4
//4个文件
........
OK
stu.id stu.name
Time taken: 79.077 seconds
hive (default)>
检验,查询stu_buck表的数据
hive (default)> select * from stu_buck;
OK
stu_buck.id stu_buck.name
1016 ss16
1012 ss12
1008 ss8
1004 ss4
1009 ss9
1005 ss5
1001 ss1
1013 ss13
1010 ss10
1002 ss2
1006 ss6
1014 ss14
1003 ss3
1011 ss11
1007 ss7
1015 ss15
Time taken: 0.201 seconds, Fetched: 16 row(s)
hive (default)>
由上,发现查询出来的数据排序发生改变,HDFS文件系统的数据规律:查询数据,文件是由上往下读
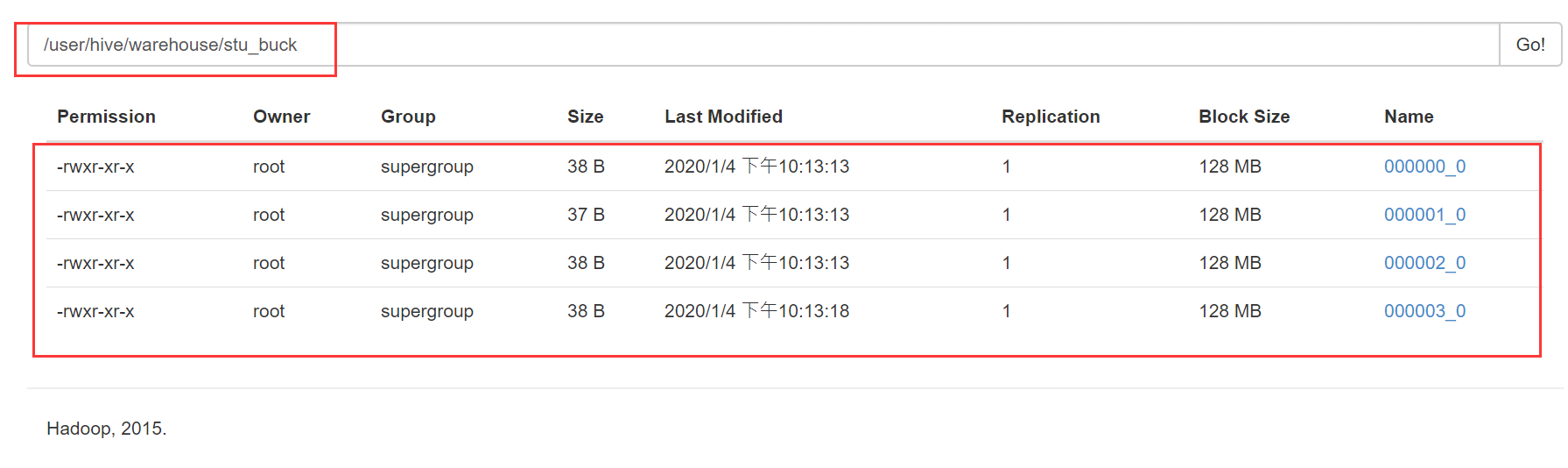
5.8 分桶抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
查询表stu_buck中的数据
hive (default)> select * from stu_buck tablesample(bucket 1 out of 4 on id);
OK
stu_buck.id stu_buck.name
1016 ss16
1012 ss12
1008 ss8
1004 ss4
Time taken: 0.305 seconds, Fetched: 4 row(s)
hive (default)>
注:**tablesample**是抽样语句
语法:TABLESAMPLE(BUCKET x OUT OF y) 。
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y
例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。
注意:x的值必须小于等于y的值,否则
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
6、其他常用查询函数
6.1 空字段赋值
(1)函数说明
NVL:给值为NULL的数据赋值,它的格式是NVL( string1, replace_with)。它的功能是如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为NULL ,则返回NULL。
首先,我们现查看emp的数据:
hive (default)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
查询:如果员工的comm为NULL,则用-1代替
hive (default)> select deptno,nvl(comm,-1) from emp;
OK
deptno _c1
20 -1.0
30 300.0
30 500.0
20 -1.0
30 1400.0
30 -1.0
10 -1.0
20 -1.0
10 -1.0
30 0.0
20 -1.0
30 -1.0
20 -1.0
10 -1.0
Time taken: 0.083 seconds, Fetched: 14 row(s)
hive (default)>
查询emp这张表
hive (default)> select deptno,comm from emp;
OK
deptno comm
20 NULL
30 300.0
30 500.0
20 NULL
30 1400.0
30 NULL
10 NULL
20 NULL
10 NULL
30 0.0
20 NULL
30 NULL
20 NULL
10 NULL
Time taken: 0.112 seconds, Fetched: 14 row(s)
hive (default)>
hive (default)> select deptno,nvl(comm,ename)from emp;
OK
deptno _c1
20 SMITH
30 300.0
30 500.0
20 JONES
30 1400.0
30 BLAKE
10 CLARK
20 SCOTT
10 KING
30 0.0
20 ADAMS
30 JAMES
20 FORD
10 MILLER
Time taken: 0.096 seconds, Fetched: 14 row(s)
hive (default)>
查询:如果员工的comm为NULL,则用领导id代替
hive (default)> select deptno,nvl(comm,mgr) from emp;
OK
deptno _c1
20 7902.0
30 300.0
30 500.0
20 7839.0
30 1400.0
30 7839.0
10 7839.0
20 7566.0
10 NULL
30 0.0
20 7788.0
30 7698.0
20 7566.0
10 7782.0
Time taken: 0.099 seconds, Fetched: 14 row(s)
hive (default)>
由这张表 查看为null
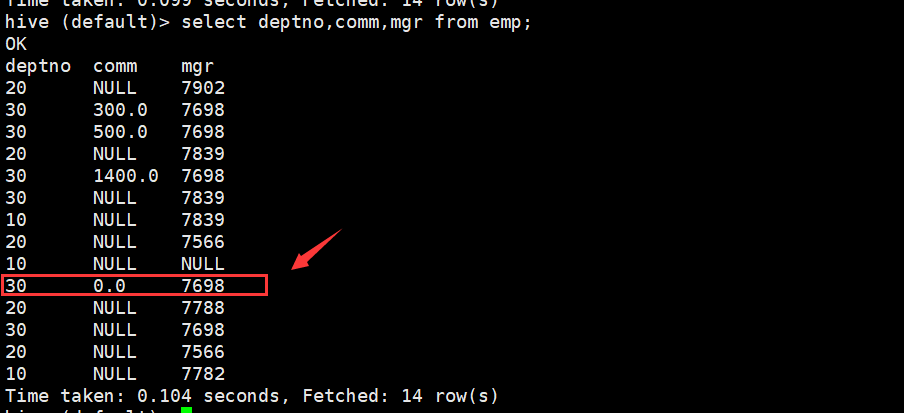
hive (default)> select deptno,comm,mgr from emp;
OK
deptno comm mgr
20 NULL 7902
30 300.0 7698
30 500.0 7698
20 NULL 7839
30 1400.0 7698
30 NULL 7839
10 NULL 7839
20 NULL 7566
10 NULL NULL
30 0.0 7698
20 NULL 7788
30 NULL 7698
20 NULL 7566
10 NULL 7782
Time taken: 0.104 seconds, Fetched: 14 row(s)
hive (default)>
6.2、 CASE WHEN
求出不同部门男女各多少人。结果如下:
A 2 1
B 1 2
步骤:
(1)创建本地emp_sex.txt,导入数据
[root@hadoop101 datas]# vim emp_sex.txt
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女
(2)创建hive表
hive (default)> create table emp_sex(
> name string,
> dept_id string,
> sex string)
> row format delimited fields terminated by "t";
OK
Time taken: 0.125 seconds
hive (default)>
(3)导入数据
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/emp_sex.txt'
> into table emp_sex;
Loading data to table default.emp_sex
Table default.emp_sex stats: [numFiles=1, totalSize=78]
OK
Time taken: 0.414 seconds
hive (default)>
(4)检验,查看emp_sex表数据
hive (default)> select * from emp_sex;
OK
emp_sex.name emp_sex.dept_id emp_sex.sex
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女
Time taken: 0.096 seconds, Fetched: 6 row(s)
hive (default)>
(5)按需求查询数据
hive (default)> select
> dept_id,
> sum(case sex when '男' then 1 else 0 end) male_count,
> sum(case sex when '女' then 1 else 0 end) female_count
> from
> emp_sex
> group by
> dept_id;
.........
.........
OK
dept_id male_count female_count
A 2 1
B 1 2
Time taken: 39.431 seconds, Fetched: 2 row(s)
hive (default)>
6.3、 行转列
相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,…):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
需求:
把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋
当然,我们可以尝试使用hive的jdbc做简单的测试:
步骤:
1、启动hiveserver2服务:
[root@hadoop101 hive-1.2.1]# cd bin/
[root@hadoop101 bin]# ls
beeline derby.log ext hive hive-config.sh hiveserver2 metastore_db metatool schematool
[root@hadoop101 bin]# ./hiveserver2
2、使用beeline 连接客户端
[root@hadoop101 ~]# cd /usr/local/hadoop/module/hive-1.2.1/bin/
[root@hadoop101 bin]# ./beeline
Beeline version 1.2.1 by Apache Hive
beeline>
3、使用jdbc的驱动去连接
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: root
Enter password for jdbc:hive2://localhost:10000:
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000>
4、查看数据表
0: jdbc:hive2://localhost:10000> show tables;
+------------------+--+
| tab_name |
+------------------+--+
| db_hive1 |
| dept |
| dept_partition2 |
| emp |
| emp_sex |
| hive_test |
| location |
| sqoop_test |
| stu |
| stu2 |
| stu_buck |
| stu_bucket |
| stu_partition |
| student |
| student1 |
| student2 |
| student3 |
| student4 |
| student5 |
| student6 |
| student7 |
+------------------+--+
21 rows selected (0.195 seconds)
0: jdbc:hive2://localhost:10000>
5、查看dept的表结构
0: jdbc:hive2://localhost:10000> desc dept;
+-----------+------------+----------+--+
| col_name | data_type | comment |
+-----------+------------+----------+--+
| deptno | int | |
| dname | string | |
| loc | int | |
+-----------+------------+----------+--+
3 rows selected (0.665 seconds)
0: jdbc:hive2://localhost:10000>
6、我们连接一下dept这张表
0: jdbc:hive2://localhost:10000> select concat(deptno,dname)from dept;
+---------------+--+
| _c0 |
+---------------+--+
| 10ACCOUNTING |
| 20RESEARCH |
| 30SALES |
| 40OPERATIONS |
+---------------+--+
4 rows selected (0.87 seconds)
0: jdbc:hive2://localhost:10000>
以上,说明连接上dept这张表,但是中间没有分割符,我们可以这样执行:
0: jdbc:hive2://localhost:10000> select concat(deptno,",",dname)from dept;
+----------------+--+
| _c0 |
+----------------+--+
| 10,ACCOUNTING |
| 20,RESEARCH |
| 30,SALES |
| 40,OPERATIONS |
+----------------+--+
4 rows selected (0.205 seconds)
0: jdbc:hive2://localhost:10000>
查看emp数据结构
0: jdbc:hive2://localhost:10000> desc emp;
+-----------+------------+----------+--+
| col_name | data_type | comment |
+-----------+------------+----------+--+
| empno | int | |
| ename | string | |
| job | string | |
| mgr | int | |
| hiredate | string | |
| sal | double | |
| comm | double | |
| deptno | int | |
+-----------+------------+----------+--+
8 rows selected (0.649 seconds)
0: jdbc:hive2://localhost:10000>
接着,我们可以对这个数据表进行分割符
0: jdbc:hive2://localhost:10000> select concat_ws(",",ename,job) from emp;
+------------------+--+
| _c0 |
+------------------+--+
| SMITH,CLERK |
| ALLEN,SALESMAN |
| WARD,SALESMAN |
| JONES,MANAGER |
| MARTIN,SALESMAN |
| BLAKE,MANAGER |
| CLARK,MANAGER |
| SCOTT,ANALYST |
| KING,PRESIDENT |
| TURNER,SALESMAN |
| ADAMS,CLERK |
| JAMES,CLERK |
| FORD,ANALYST |
| MILLER,CLERK |
+------------------+--+
14 rows selected (0.414 seconds)
0: jdbc:hive2://localhost:10000>
当然,我们可以拼接两个或多个,例如:拼接两个
0: jdbc:hive2://localhost:10000> select concat_ws(",",ename,job,hiredate) from emp;
+----------------------------+--+
| _c0 |
+----------------------------+--+
| SMITH,CLERK,1980-12-17 |
| ALLEN,SALESMAN,1981-2-20 |
| WARD,SALESMAN,1981-2-22 |
| JONES,MANAGER,1981-4-2 |
| MARTIN,SALESMAN,1981-9-28 |
| BLAKE,MANAGER,1981-5-1 |
| CLARK,MANAGER,1981-6-9 |
| SCOTT,ANALYST,1987-4-19 |
| KING,PRESIDENT,1981-11-17 |
| TURNER,SALESMAN,1981-9-8 |
| ADAMS,CLERK,1987-5-23 |
| JAMES,CLERK,1981-12-3 |
| FORD,ANALYST,1981-12-3 |
| MILLER,CLERK,1982-1-23 |
+----------------------------+--+
14 rows selected (0.258 seconds)
0: jdbc:hive2://localhost:10000>
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
0: jdbc:hive2://localhost:10000> select collect_set(dname)from dept;
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1578143773019_0004
INFO : The url to track the job: http://hadoop101:8088/proxy/application_1578143773019_0004/
INFO : Starting Job = job_1578143773019_0004, Tracking URL = http://hadoop101:8088/proxy/application_1578143773019_0004/
INFO : Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1578143773019_0004
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-01-04 23:45:40,828 Stage-1 map = 0%, reduce = 0%
INFO : 2020-01-04 23:45:54,681 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.79 sec
INFO : 2020-01-04 23:46:04,710 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.58 sec
INFO : MapReduce Total cumulative CPU time: 3 seconds 580 msec
INFO : Ended Job = job_1578143773019_0004
+-------------------------------------------------+--+
| _c0 |
+-------------------------------------------------+--+
| ["ACCOUNTING","RESEARCH","SALES","OPERATIONS"] |
+-------------------------------------------------+--+
1 row selected (47.617 seconds)
0: jdbc:hive2://localhost:10000>
操作步骤:
(1)创建本地person_info.txt,导入数据
[root@hadoop101 datas]# vim person_info.txt
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
保存退出!
(2)创建hive表并导入数据
hive (default)> create table person_info(
> name string,
> constellation string,
> blood_type string)
> row format delimited fields terminated by "t";
OK
Time taken: 0.912 seconds
hive (default)>
导入数据
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/person_info.txt'
> into table person_info;
Loading data to table default.person_info
Table default.person_info stats: [numFiles=1, totalSize=128]
OK
Time taken: 0.842 seconds
hive (default)>
(3)检验,查询person_info这张表的数据
0: jdbc:hive2://localhost:10000> select * from person_info;
+-------------------+----------------------------+-------------------------+--+
| person_info.name | person_info.constellation | person_info.blood_type |
+-------------------+----------------------------+-------------------------+--+
| 孙悟空 白羊座 A | NULL | NULL |
| 大海 | 射手座 A | NULL |
| 宋宋 | 白羊座 B | NULL |
| 猪八戒 白羊座 A | NULL | NULL |
| 凤姐 | 射手座 A | NULL |
+-------------------+----------------------------+-------------------------+--+
5 rows selected (0.614 seconds)
0: jdbc:hive2://localhost:10000> select CONCAT_WS(",",constellation,blood_type),name from person_info;
+-------------+------------------+--+
| _c0 | name |
+-------------+------------------+--+
| | 孙悟空 白羊座 A |
| 射手座 A | 大海 |
| 白羊座 B | 宋宋 |
| | 猪八戒 白羊座 A |
| 射手座 A | 凤姐 |
+-------------+------------------+--+
5 rows selected (0.21 seconds)
0: jdbc:hive2://localhost:10000>
按需求查询数据
0: jdbc:hive2://localhost:10000> select
0: jdbc:hive2://localhost:10000> t1.base,
0: jdbc:hive2://localhost:10000> concat_ws('|', collect_set(t1.name)) name
0: jdbc:hive2://localhost:10000> from
0: jdbc:hive2://localhost:10000> (select
0: jdbc:hive2://localhost:10000> name,
0: jdbc:hive2://localhost:10000> concat(constellation, ",", blood_type) base
0: jdbc:hive2://localhost:10000> from
0: jdbc:hive2://localhost:10000> person_info) t1
0: jdbc:hive2://localhost:10000> group by
0: jdbc:hive2://localhost:10000> t1.base;
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1578143773019_0005
INFO : The url to track the job: http://hadoop101:8088/proxy/application_1578143773019_0005/
INFO : Starting Job = job_1578143773019_0005, Tracking URL = http://hadoop101:8088/proxy/application_1578143773019_0005/
INFO : Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1578143773019_0005
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-01-05 00:55:26,888 Stage-1 map = 0%, reduce = 0%
INFO : 2020-01-05 00:55:42,201 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.19 sec
INFO : 2020-01-05 00:55:54,398 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.43 sec
INFO : MapReduce Total cumulative CPU time: 6 seconds 430 msec
INFO : Ended Job = job_1578143773019_0005
+----------+-------------------------------------------+--+
| t1.base | name |
+----------+-------------------------------------------+--+
| NULL | 孙悟空 白羊座 A|大海|宋宋|猪八戒 白羊座 A|凤姐 |
+----------+-------------------------------------------+--+
1 row selected (49.073 seconds)
0: jdbc:hive2://localhost:10000>
6.4 列转行
1.函数说明
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
2.数据准备
[root@hadoop101 module]# cd datas/
[root@hadoop101 datas]# vim movie.txt
[root@hadoop101 datas]#
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
3.创建hive表
hive (default)> create table movie_info(
> movie string,
> category array<string>)
> row format delimited fields terminated by "t"
> collection items terminated by ",";
OK
Time taken: 1.605 seconds
hive (default)>
4.导入数据
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/movie.txt'
> into table movie_info;
Loading data to table default.movie_info
Table default.movie_info stats: [numFiles=1, totalSize=133]
OK
Time taken: 1.782 seconds
hive (default)>
4.查看movie_info数据信息
hive (default)> select * from movie_info;
OK
movie_info.movie movie_info.category
《疑犯追踪》 ["悬疑","动作","科幻","剧情"]
《Lie to me》 ["悬疑","警匪","动作","心理","剧情"]
《战狼2》 ["战争","动作","灾难"]
Time taken: 0.505 seconds, Fetched: 3 row(s)
hive (default)>
若想把行的数据拆分成一列的数据,并独占一行,可以这样执行:
hive (default)> select EXPLODE(category)from movie_info;
OK
col
悬疑
动作
科幻
剧情
悬疑
警匪
动作
心理
剧情
战争
动作
灾难
Time taken: 0.192 seconds, Fetched: 12 row(s)
hive (default)>
另一种方式:按需求查询数据
0: jdbc:hive2://localhost:10000> select movie, category_name
0: jdbc:hive2://localhost:10000> from movie_info
0: jdbc:hive2://localhost:10000> LATERAL VIEW EXPLODE(category) tmpTable as category_name;
+--------------+----------------+--+
| movie | category_name |
+--------------+----------------+--+
| 《疑犯追踪》 | 悬疑 |
| 《疑犯追踪》 | 动作 |
| 《疑犯追踪》 | 科幻 |
| 《疑犯追踪》 | 剧情 |
| 《Lie to me》 | 悬疑 |
| 《Lie to me》 | 警匪 |
| 《Lie to me》 | 动作 |
| 《Lie to me》 | 心理 |
| 《Lie to me》 | 剧情 |
| 《战狼2》 | 战争 |
| 《战狼2》 | 动作 |
| 《战狼2》 | 灾难 |
+--------------+----------------+--+
12 rows selected (0.23 seconds)
0: jdbc:hive2://localhost:10000>
6.5、窗口函数
1.相关函数说明
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n):往前第n行数据
LEAD(col,n):往后第n行数据
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
2.数据准备:name,orderdate,cost
[root@hadoop101 datas]# vim business.txt
[root@hadoop101 datas]#
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
保存退出!
3、创建hive表并导入数据
hive (default)> create table business(
> name string,
> orderdate string,
> cost int
> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
OK
Time taken: 0.63 seconds
hive (default)>
导入数据:
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/business.txt'
> into table business;
Loading data to table default.business
Table default.business stats: [numFiles=1, totalSize=266]
OK
Time taken: 1.298 seconds
hive (default)>
查询business数据表信息
0: jdbc:hive2://localhost:10000> select * from business;
+----------------+---------------------+----------------+--+
| business.name | business.orderdate | business.cost |
+----------------+---------------------+----------------+--+
| jack | 2017-01-01 | 10 |
| tony | 2017-01-02 | 15 |
| jack | 2017-02-03 | 23 |
| tony | 2017-01-04 | 29 |
| jack | 2017-01-05 | 46 |
| jack | 2017-04-06 | 42 |
| tony | 2017-01-07 | 50 |
| jack | 2017-01-08 | 55 |
| mart | 2017-04-08 | 62 |
| mart | 2017-04-09 | 68 |
| neil | 2017-05-10 | 12 |
| mart | 2017-04-11 | 75 |
| neil | 2017-06-12 | 80 |
| mart | 2017-04-13 | 94 |
+----------------+---------------------+----------------+--+
14 rows selected (0.297 seconds)
0: jdbc:hive2://localhost:10000>
需求:
(1)查询在2017年4月份购买过的顾客及总人数
0: jdbc:hive2://localhost:10000> select name,count(*)
0: jdbc:hive2://localhost:10000> from business
0: jdbc:hive2://localhost:10000> where substring(orderdate,1,7)="2017-04"
0: jdbc:hive2://localhost:10000> group by name;
.........
+-------+------+--+
| name | _c1 |
+-------+------+--+
| jack | 1 |
| mart | 4 |
+-------+------+--+
正确查询:
加over(),执行如下:
0: jdbc:hive2://localhost:10000> select name,count(*) over()
0: jdbc:hive2://localhost:10000> from business
0: jdbc:hive2://localhost:10000> where substring(orderdate,1,7)="2017-04"
0: jdbc:hive2://localhost:10000> group by name;
.........
+-------+-----------------+--+
| name | count_window_0 |
+-------+-----------------+--+
| mart | 2 |
| jack | 2 |
+-------+-----------------+--+
2 rows selected (86.19 seconds)
0: jdbc:hive2://localhost:10000>
(2)查询顾客的购买明细及月购买总额
0: jdbc:hive2://localhost:10000> select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from
0: jdbc:hive2://localhost:10000> business;
.........
+-------+-------------+-------+---------------+--+
| name | orderdate | cost | sum_window_0 |
+-------+-------------+-------+---------------+--+
| jack | 2017-01-01 | 10 | 205 |
| jack | 2017-01-08 | 55 | 205 |
| tony | 2017-01-07 | 50 | 205 |
| jack | 2017-01-05 | 46 | 205 |
| tony | 2017-01-04 | 29 | 205 |
| tony | 2017-01-02 | 15 | 205 |
| jack | 2017-02-03 | 23 | 23 |
| mart | 2017-04-13 | 94 | 341 |
| jack | 2017-04-06 | 42 | 341 |
| mart | 2017-04-11 | 75 | 341 |
| mart | 2017-04-09 | 68 | 341 |
| mart | 2017-04-08 | 62 | 341 |
| neil | 2017-05-10 | 12 | 12 |
| neil | 2017-06-12 | 80 | 80 |
+-------+-------------+-------+---------------+--+
14 rows selected (40.192 seconds)
0: jdbc:hive2://localhost:10000>
(3)上述的场景,要将cost按照日期进行累加
0: jdbc:hive2://localhost:10000> select name,orderdate,cost,
0: jdbc:hive2://localhost:10000> sum(cost) over() as sample1,
0: jdbc:hive2://localhost:10000> sum(cost) over(partition by name) as sample2,
0: jdbc:hive2://localhost:10000> sum(cost) over(partition by name order by orderdate) as sample3,
0: jdbc:hive2://localhost:10000> sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,
0: jdbc:hive2://localhost:10000> sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5,
0: jdbc:hive2://localhost:10000> sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,
0: jdbc:hive2://localhost:10000> sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7
0: jdbc:hive2://localhost:10000> from business;
................
(4)查询顾客上次的购买时间
0: jdbc:hive2://localhost:10000> select name,orderdate,cost,
0: jdbc:hive2://localhost:10000> lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1,
0: jdbc:hive2://localhost:10000> lag(orderdate,2) over (partition by name order by orderdate) as time2
0: jdbc:hive2://localhost:10000> from business;
................
+-------+-------------+-------+-------------+-------------+--+
| name | orderdate | cost | time1 | time2 |
+-------+-------------+-------+-------------+-------------+--+
| jack | 2017-01-01 | 10 | 1900-01-01 | NULL |
| jack | 2017-01-05 | 46 | 2017-01-01 | NULL |
| jack | 2017-01-08 | 55 | 2017-01-05 | 2017-01-01 |
| jack | 2017-02-03 | 23 | 2017-01-08 | 2017-01-05 |
| jack | 2017-04-06 | 42 | 2017-02-03 | 2017-01-08 |
| mart | 2017-04-08 | 62 | 1900-01-01 | NULL |
| mart | 2017-04-09 | 68 | 2017-04-08 | NULL |
| mart | 2017-04-11 | 75 | 2017-04-09 | 2017-04-08 |
| mart | 2017-04-13 | 94 | 2017-04-11 | 2017-04-09 |
| neil | 2017-05-10 | 12 | 1900-01-01 | NULL |
| neil | 2017-06-12 | 80 | 2017-05-10 | NULL |
| tony | 2017-01-02 | 15 | 1900-01-01 | NULL |
| tony | 2017-01-04 | 29 | 2017-01-02 | NULL |
| tony | 2017-01-07 | 50 | 2017-01-04 | 2017-01-02 |
+-------+-------------+-------+-------------+-------------+--+
14 rows selected (40.32 seconds)
0: jdbc:hive2://localhost:10000>
(5)查询前20%时间的订单信息
0: jdbc:hive2://localhost:10000> select * from (
0: jdbc:hive2://localhost:10000> select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
0: jdbc:hive2://localhost:10000> from business
0: jdbc:hive2://localhost:10000> ) t
0: jdbc:hive2://localhost:10000> where sorted = 1;
...............
+---------+--------------+---------+-----------+--+
| t.name | t.orderdate | t.cost | t.sorted |
+---------+--------------+---------+-----------+--+
| jack | 2017-01-01 | 10 | 1 |
| tony | 2017-01-02 | 15 | 1 |
| tony | 2017-01-04 | 29 | 1 |
+---------+--------------+---------+-----------+--+
3 rows selected (38.962 seconds)
0: jdbc:hive2://localhost:10000>
6.6 Rank
1.函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
2.数据准备
创建本地movie.txt
[root@hadoop101 datas]# vim score.txt
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
保存退出!
3、创建hive表并导入数据
hive (default)> create table score(
> name string,
> subject string,
> score int)
> row format delimited fields terminated by "t";
OK
Time taken: 0.902 seconds
hive (default)> load data local inpath '/opt/module/datas/score.txt' into table score;
导入数据:
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/score.txt'
> into table score;
Loading data to table default.score
Table default.score stats: [numFiles=1, totalSize=213]
OK
Time taken: 1.927 seconds
hive (default)>
查询score表数据
0: jdbc:hive2://localhost:10000> select * from score;
+-------------+----------------+--------------+--+
| score.name | score.subject | score.score |
+-------------+----------------+--------------+--+
| 孙悟空 | 语文 | 87 |
| 孙悟空 | 数学 | 95 |
| 孙悟空 | 英语 | 68 |
| 大海 | 语文 | 94 |
| 大海 | 数学 | 56 |
| 大海 | 英语 | 84 |
| 宋宋 | 语文 | 64 |
| 宋宋 | 数学 | 86 |
| 宋宋 | 英语 | 84 |
| 婷婷 | 语文 | 65 |
| 婷婷 | 数学 | 85 |
| 婷婷 | 英语 | 78 |
+-------------+----------------+--------------+--+
12 rows selected (0.29 seconds)
0: jdbc:hive2://localhost:10000>
需求
计算每门学科成绩排名。
按需求查询数据
0: jdbc:hive2://localhost:10000> select name,
0: jdbc:hive2://localhost:10000> subject,
0: jdbc:hive2://localhost:10000> score,
0: jdbc:hive2://localhost:10000> rank() over(partition by subject order by score desc) rp,
0: jdbc:hive2://localhost:10000> dense_rank() over(partition by subject order by score desc) drp,
0: jdbc:hive2://localhost:10000> row_number() over(partition by subject order by score desc) rmp
0: jdbc:hive2://localhost:10000> from score;
...
+-------+----------+--------+-----+------+------+--+
| name | subject | score | rp | drp | rmp |
+-------+----------+--------+-----+------+------+--+
| 孙悟空 | 数学 | 95 | 1 | 1 | 1 |
| 宋宋 | 数学 | 86 | 2 | 2 | 2 |
| 婷婷 | 数学 | 85 | 3 | 3 | 3 |
| 大海 | 数学 | 56 | 4 | 4 | 4 |
| 宋宋 | 英语 | 84 | 1 | 1 | 1 |
| 大海 | 英语 | 84 | 1 | 1 | 2 |
| 婷婷 | 英语 | 78 | 3 | 2 | 3 |
| 孙悟空 | 英语 | 68 | 4 | 3 | 4 |
| 大海 | 语文 | 94 | 1 | 1 | 1 |
| 孙悟空 | 语文 | 87 | 2 | 2 | 2 |
| 婷婷 | 语文 | 65 | 3 | 3 | 3 |
| 宋宋 | 语文 | 64 | 4 | 4 | 4 |
+-------+----------+--------+-----+------+------+--+
12 rows selected (41.207 seconds)
0: jdbc:hive2://localhost:10000>
最后
以上就是高挑老虎最近收集整理的关于第6章 hive数据操作---查询(重点)连接谓词中不支持or的全部内容,更多相关第6章内容请搜索靠谱客的其他文章。








发表评论 取消回复