一、操作目的
1、搭建 Hive 的分布式环境
2、可以在各个 Hive 的客户端节点上执行 hive 命令
二、基础环境(Hadoop3.3.0集群、单节点 Hive)安装
基于 Hadoop 3.x 集群搭建部署 Hive
三、Hive 分布式集群部署
1、编辑 hive 的配置文件 hive-site.xml
[root@master ~]# vim /usr/bigdata/apache-hive-3.1.2-bin/conf/hive-site.xml
2、增加配置内容
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
<description>Whether HiveServer2 Active/Passive High Availability be enabled when Hive Interactive sessions are enabled.This will also require hive.server2.support.dynamic.service.discovery to be enabled.</description>
</property>
3、把 已经在 master 节点上安装配置好的 Hive 目录及文件发送给 slave1、slave2、slave3 节点
[root@master ~]# scp -r /usr/bigdata/apache-hive-3.1.2-bin root@slave1:/usr/bigdata/
[root@master ~]# scp -r /usr/bigdata/apache-hive-3.1.2-bin root@slave2:/usr/bigdata/
[root@master ~]# scp -r /usr/bigdata/apache-hive-3.1.2-bin root@slave3:/usr/bigdata/
4、在各个节点创建 hive 用户
[root@slave1 ~]# useradd hive
[root@slave2 ~]# useradd hive
[root@slave3 ~]# useradd hive
5、、查看 master 上的系统环境变量
[root@master ~]# cat /etc/profile
6、、slave1 节点上的大数据相关系统环境变量如下
export JAVA_HOME="/usr/lib/jvm/java-1.8.0"
export JRE_HOME="/usr/lib/jvm/java-1.8.0/jre"
export HADOOP_HOME="/usr/bigdata/hadoop-3.3.0"
export HIVE_HOME="/usr/bigdata/apache-hive-3.1.2-bin"
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*:$hive_HOME/lib
7、、编辑 slave1、slave2、slave3 节点上的系统环境变量
[root@slave1 ~]# vim /etc/profile
[root@slave2 ~]# vim /etc/profile
[root@slave3 ~]# vim /etc/profile
8、、使 slave1、slave2、slave3 节点上的系统环境变量生效
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile
[root@slave3 ~]# source /etc/profile
9、、在 slave2 节点上执行 hive 命令
[root@slave2 ~]# hive
启动效果如下:
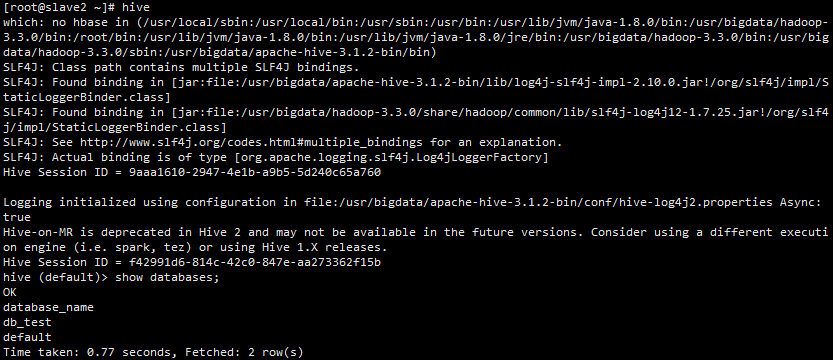
10、在 slave3 节点上执行 hive 命令
[root@slave3 ~]# hive
启动效果如下:
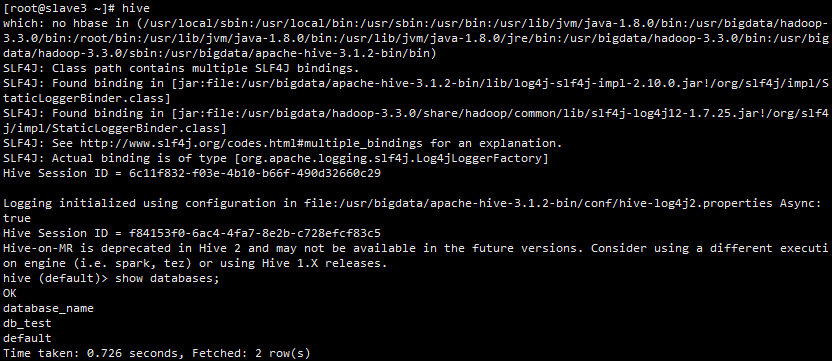
11、由上图的操作可以看到前文在 master 节点上创建的数据库 db_test
四、hiveserver2 服务启动
1、控制台启动
[root@master ~]# hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001
2、后台启动
[root@master ~]# nohup hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001 &
3、查看 hiveserver2 服务启动日志
[root@master ~]# cat /usr/bigdata/apache-hive-3.1.2-bin/logs/hive.log

五、浏览器查看
在浏览器地址栏录入 http://192.168.11.21:10002/ (说明:192.168.11.21 是 hiveserver2 服务启动节点的 IP )
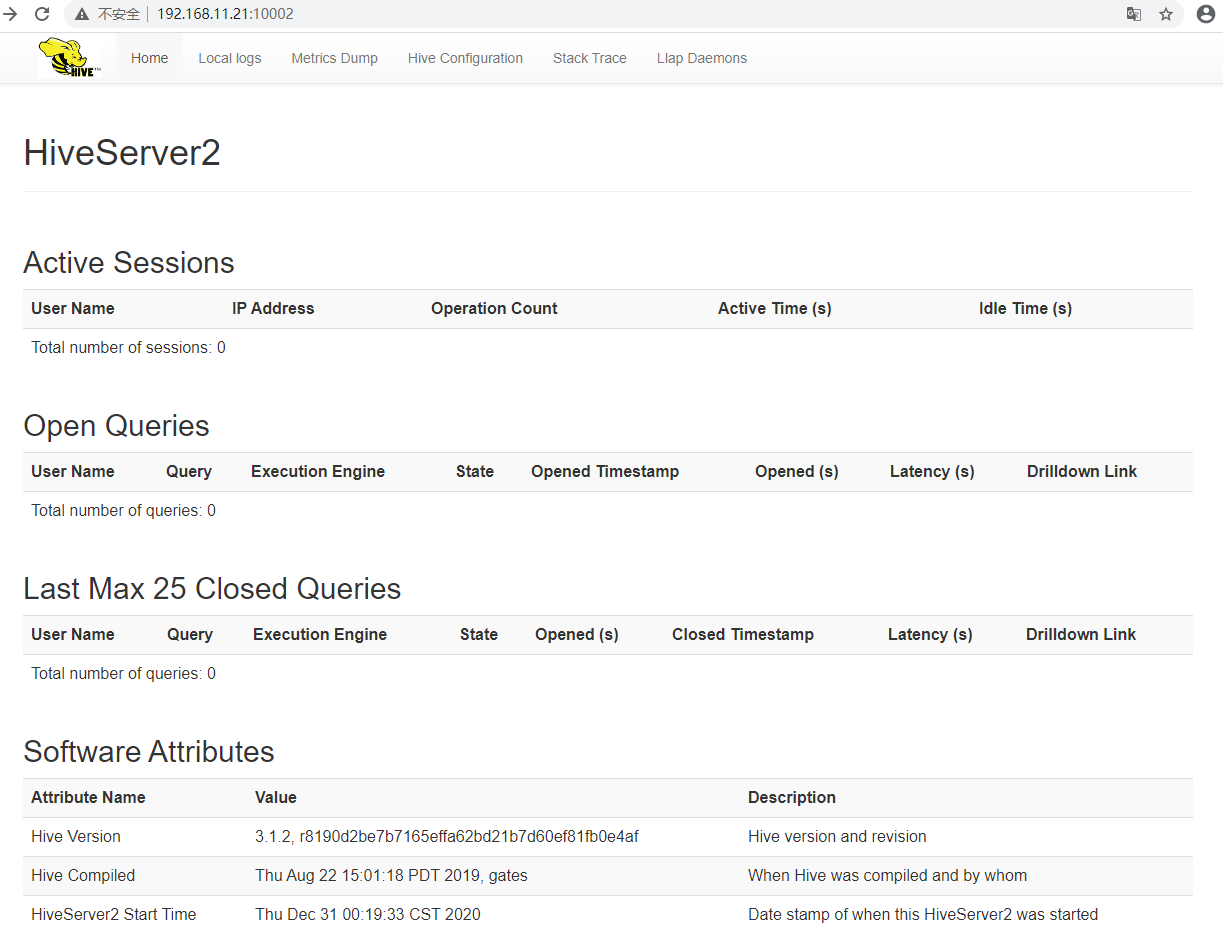
至此,Centos7.x 搭建部署 Hive 3.1.2 分布式集群操作完毕,希望能够对您有所帮助!
最后
以上就是甜美哈密瓜最近收集整理的关于记一次 Centos7.x 搭建部署 Hive 3.1.2 分布式集群一、操作目的二、基础环境(Hadoop3.3.0集群、单节点 Hive)安装三、Hive 分布式集群部署四、hiveserver2 服务启动五、浏览器查看的全部内容,更多相关记一次内容请搜索靠谱客的其他文章。








发表评论 取消回复